-
第六讲:在线学习材料的设计
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
《在线学习设计》课程学习体验调查
大家好!为了解您在本学期《在线学习设计》课程中的真实体验与收获,发现课程设计与实施过程中的亮点与不足,特开展本次问卷调查。
问卷调查链接:《在线学习设计》课程学习感受调查(点击注册后,即可填写)
本次问卷实名填写,完成情况(填写时间)直接计入平时成绩。请大家务必结合实际体验客观作答。我们看重真实反馈,无需刻意好评,也不用担心评分受影响。你的真实意见和建议既是改进课程的核心依据,也是本次平时成绩评定的重要参考。特别说明:所有数据仅用于本次课程评估与优化,绝不会向外公布或传播,请放心填写。
请于本节课结束前提交,预计占用您 5-8 分钟。感谢配合,你的反馈将直接助力教学优化!
-
温馨提示
各位同学好!请各小组于第18周(2026.06.29晚24点整截止)之前提交第四讲“小组作品策展:设计我心目中的在线学习环境”的成果。
期待看到各学习小组心中那个兼具创新与实用性的未来学习环境!如有问题,请在第四讲“提问答疑”区提出,助教老师会及时反馈。
-
Introduction
Textbkoos remain one of the main methods of instruction, but—just like other educational tools—they have been evolving over the last several decades in many aspects (how they are created, published, formatted, accessed, and maintained). Most textbooks today have digital versions and can be accessed online. A large number of textbooks (and other structured instructional texts, such as tutorials) are freely available as open educational resources (e.g., Baraniuk et al., 2017). Many textbooks come with libraries of supplementary educational resources (Ericson & Miller, 2020; Gordon et al., 2021) or even distributed as parts of online educational services built on top of them (Ritter et al., 2019). The transition of textbooks from printed copies to digital and online formats has facilitated numerous attempts to enrich them with various kinds of interactive functionalities including search and annotation, interactive content modules, automated assessments, question ans, chatbots, etc.
As a result of these enrichments, new research challenges and opportunities emerge that call for the application of artificial intelligence (AI) methods to enhance digital textbooks and learners’ interaction with them. There are many research questions associated with this new area of research; examples include:
- How can we facilitate access to textbooks and improve the reading process?
- How can we process textbook content to infer knowledge underlying the text and use it to improve learning support?
- How can we process increasingly more detailed logs of students interacting with digital textbooks and extract insights on learning?
- How can we find and retrieve relevant content “in the wild”, i.e., on the web, that can enrich the textbooks?
- How can we leverage advanced language technology, such as chatbots, to make textbooks more interactive?
- How can we better understand both textbooks and student behaviors as they learn within the textbook and create personalized learner experiences?
-
The Evolution of Intelligent Textbooks
Our previous analyses of the field of Intelligent Textbooks have identified several topical trends (Rodrigo et al., 2023) and historic milestones (Brusilovsky et al., 2022) that help us understand how the field has developed over the years and which challenges have remained the focus of the community. In this section, we present an updated overview of the evolution of the research on Intelligent Textbooks, including more recent developments in the field. We hope that this overview helps the readers understand the “big picture” of research in this fast-developing field.
Generation 1: Intelligence Engineered
The first generation of research on intelligent textbooks was born at the crossroads of intelligent tutoring systems (Reggia et al., 1980) and adaptive educational hypermedia (Brusilovsky et al., 1993). Interfaces of first prototypes did not utilize the familiar textbook layout; instead, they provided students with adaptive access to information items or hyper-cards as a response to students’ performance with accompanying exercises. After the Web (with its hypertext core) became the main platform for the deployment of educational tools, first-generation intelligent textbooks adopted the common structured textbook organization with its tree of sections, a table of contents, and glossaries. On the top of this common structure, these intelligent textbooks implemented a range of personalization techniques to support the readers, such as navigation support (Henze et al., 1999; Weber & Brusilovsky, 2016), adaptive page manipulation (Hohl et al., 1996), content recommendation (Kavcic, 2004), content sequencing (Ullrich, 2008), or a combination of different techniques (Sosnovsky, 2014). These textbooks were developed as closed-corpus environments that provided access to limited collections of carefully crafted of instructional texts and learning exercises (see Fig. 1). The intelligence in first-generation intelligent textbooks was based on traditional knowledge engineering approaches, which required engagement of human domain experts. As illustrated in Fig. 1, these experts helped structure the learning domain as a set of concepts (nodes), connect textbook sections and activities (documents) with domain concepts (edges), and develop personalization approaches based on these domain and content models (gears). Students’ interaction with the elements of the textbook content (texts and exercises) was traced to model the growth of student knowledge about domain concepts and use by its personalization technologies to help students master the textbook knowledge in an individually optimized manner.
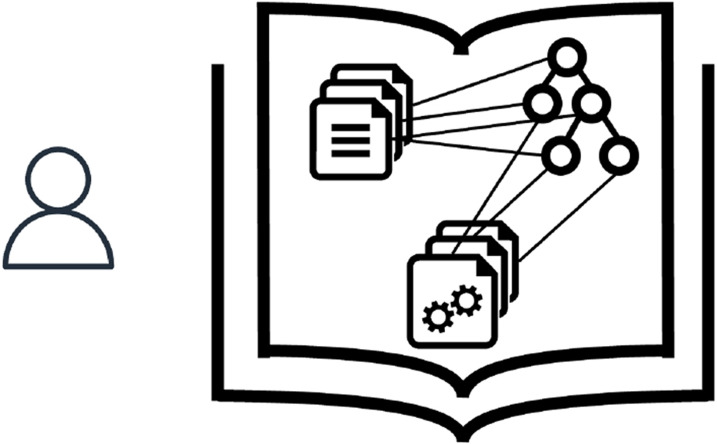
Fig. 1. Intelligent textbooks of the first generation are closed-box adaptive educational systems, which rely on carefully-engineered models of domain knowledge and textbook material. They also enrich textbook reading experience with interactivity, served by exercises and assessments that provide students with various kinds of adaptive support Generation 2: Intelligence Integrated
For the next generation of intelligent textbooks, the focus initially shifted to more practical aspects of implementing textbook environments, such as open architectures (De Bra & Calvi, 1998; Brusilovsky, 2004), integration of textbooks with external educational resources (Dolog et al., 2004a), and standardization of semantic models that support such architectures and integration (Dolog et al., 2004b; Melis et al., 2006). Illustrated in Fig. 2, this integration enabled researchers to address one of the recognized problems of first-generation intelligent textbooks: their closed-box nature (once designed, they were impossible to extend, modify, and scale). The development of Semantic Web technologies offered new standardization formats and modeling languages for shareable and expressive knowledge representation along with new architectural solutions for intelligent software. This development enabled researchers to implement knowledge models for intelligent textbooks as ontologies, develop educational material as interlinked and annotated learning objects, and seamlessly integrate shareable knowledge models and content within textbooks. Although adaptive and intelligent access to textbook content remained the ultimate goal of second-generation intelligent textbooks, the expressive power of employed semantic models supported some new functionalities. The most advanced second-generation textbooks were able to “understand” their content and engage in new forms of interactions with learners such as meaningful question answering and concept mapping (Chaudhri et al., 2013).
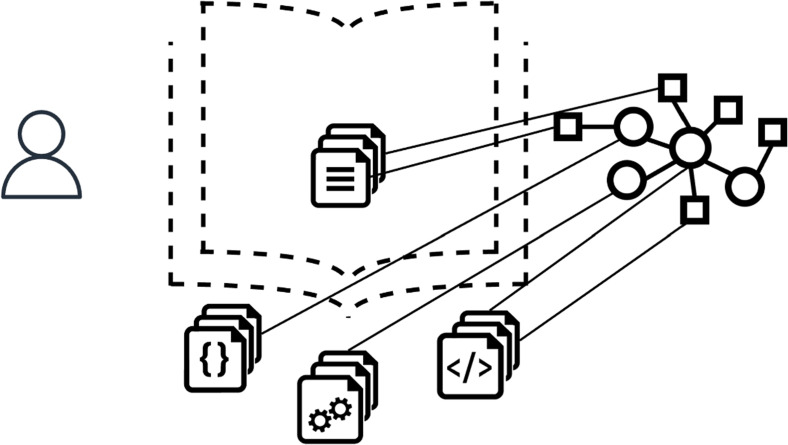
Fig. 2. Intelligent textbooks of the second generation benefit from open architectures and open standards for knowledge representation. They integrate external otologies and interactive learning objects from shared repositories to assemble the adaptive functionality of intelligent textbooks of the previous generation Generation 3: Intelligence Extracted
The next set of intelligent textbook projects were characterized by a fundamental shift in the perspective on the role of textbooks and the AI toolkit used to “make them intelligent”. While the first and second generations were driven by classical AI approaches for symbolic knowledge representation and logic-based knowledge inference, the third generation employed Machine Learning (ML) and Natural Language Processing (NLP) methods focusing on knowledge extraction. Researchers realized that textbooks are not only educational tools, but also sources of high-quality educational content that is written and structured by domain experts (textbook authors) with the purpose of explaining the subject of the textbook to students. Illustrated in Fig. 3, third-generation intelligent textbook researchers treated digital textbooks less as objects to add “intelligence” to, and more as sources of “intelligence” that can be harvested automatically and at scale. A wide range of newly-developed NLP, semantic web, and ML methods were applied to the content of digital textbook with the purpose of extracting topics (Sosnovsky et al., 2012), concepts (Wang et al., 2015), relations (Adorni et al., 2019; Alzetta et al., 2020), and even complete knowledge models (Alpizar-Chacon & Sosnovsky, 2021). Turning the focus of knowledge extraction research back to education, novel NLP approaches used textbooks as knowledge sources to generate individual learning objects (Yarbro & Olney, 2021), explanations (Sovrano et al., 2022), and assessment material (Dresscher et al., 2021; Van Campenhout et al., 2021). Together, the new ability to automatically extract knowledge and learning objects from digital textbooks means that the textbooks themselves could be automatically transformed into intelligent textbooks (Alpizar-Chacon et al., 2020), linked to external interactive content (Rahdari et al., 2020) and connected to each other (Guerra et al., 2013; Alpizar-Chacon & Sosnovsky, 2019).

Fig. 3. Intelligent textbooks of the third generation combined projects that analyzed content, formatting, organization and structure of digital textbooks to automatically extract from them domain knowledge and/or individual learning objects; some of these projects sought to use extracted knowledge to link textbooks to each other Generation 4: Intelligence Datamined
As the adoption of digital textbooks in real educational context expanded, another source of “intelligence” became increasingly available: usage data generated by students interacting with textbooks. These data included latent traces of students’ progress with textbooks through reading, question-answering, explicitly provided annotations (Farzan & Brusilovsky, 2008), highlights (Winchell et al., 2018), and tags (Zhang et al., 2017). Illustrated in Fig. 4, the fourth-generation research on intelligent textbooks applied a range of data-mining methods to leverage student-textbook interaction logs in several ways. Most importantly, the large volumes of student data allowed researchers to better understand reading behavior and connect it to learning progress. On a coarse-grained level, extracted patterns of navigation through textbook sections and pages along with annotation activity were used to predict readers’ overall success or failure (Kim et al., 2021), which then could be used for a timely intervention (Winchell et al., 2018; Yin et al., 2019). On a more fine-grained level, student interactions with textbook sections were used to model their knowledge of domain concepts (Thaker et al., 2019). The resulting models could be used to recommend the most relevant internal (Thaker et al., 2020) or external (Barria-Pineda et al., 2019) content. User interaction data could also be used to improve textbook organization or representation. For example, log data combined with the analysis of textbook content could be used to obtain more reliable prerequisite relationships (Liu et al., 2016). Finally, interaction data could be revealed directly to the readers through the textbook interface. This approach could be used to support open learner modeling, social awareness, and self-regulation (Papanikolaou et al., 2003; Barria-Pineda et al., 2019).

Fig. 4. Intelligent textbooks of the fourth generation use student interaction data to data-mine textbook navigation patterns, predict level of content understanding, construct interfaces utilizing the social dimension of groups/communities of students learning from the online textbooks Generation 5: Intelligence Generated
Illustrated in Fig. 5, many recent works on intelligent textbooks have started to incorporate large language models (LLMs), which are perfectly suited to extract and synthesize information from textbooks. Evidence suggests that most existing LLMs are pre-trained on a large amount of textual data collected from books, textbooks, and even synthetic textbook-like data (CNN, 2023; Gunasekar et al., 2023). As a result, LLMs already capture abundant knowledge contained in textbooks during pre-training and can be used to help learners. For example, the work in Levonian et al. (2023) examines using OpenStax textbooks to power automated question answering tools for learners, showing that retrieval augmented generation techniques are effective at reducing the intrinsic hallucination problem in LLMs. One challenge in this direction is that the context length of LLMs, i.e., the amount of information they can effectively take in during deployment, is limited and not enough to cover long documents (Fernandez et al., 2024). Another important direction is to use LLMs to power more interactive experiences around textbooks, e.g., chatbots: Khan academy leverages their access to GPT-4 by OpenAI to power a tutoring chatbot around their content through prompt engineering (Khan Academy, 2023), while others use GPT-4, a proprietary LLM to simulate tutor-learner conversations and use this data to train smaller, open-source LLMs as chatbots (Sonkar et al., 2023).
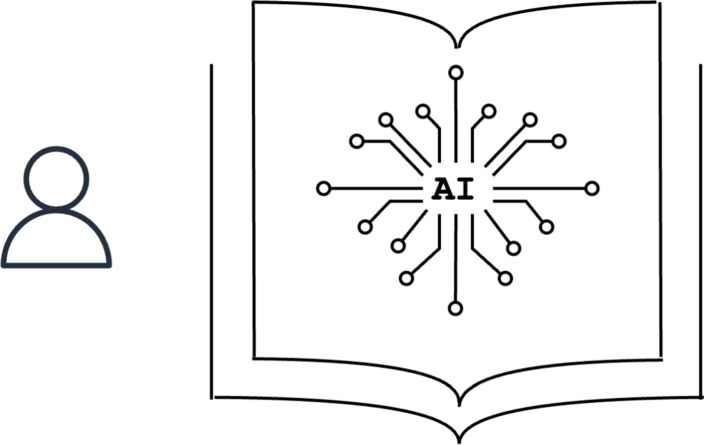
Fig. 5. Intelligent textbooks of the fifth generation seek to utilize new capabilities provided by generative AI systems. The range of problems addressed and methods employed is vast: from new ways to generate assessment material to new dialog-based interfaces to attempts to generate the content of textbooks themselves -
Outlook
Powered by advancing AI technologies, new learner support tools around intelligent textbooks are being developed at a rapid pace. Through the review of existing work, we find that new technology, especially that in the third, fourth, and fifth generations of intelligent textbooks as we categorized above, is enabled by extracting large-scale data from textbooks. For example, chatbots need to be carefully calibrated based on real teacher-learner interaction around learning content (Macina et al., 2023; Wang et al., 2024). These developments reveal a mutually beneficial cycle between the development of new tools and data extraction and analysis: new tools open up new ways of learner-textbook interaction, which generates new types of data that can, in turn, power the development of new tools. This cycle had already existed before in the field of intelligent educational systems. Indeed, the development of richer learning interfaces led to the increased volume of learner data being collected to power user models, which then enabled new personalization approaches. However, with new AI technologies, this cycle accelerated and became more evident. With this vision in mind, it is important for future work on intelligent textbooks to develop new modes of interaction between learners and textbooks, e.g., through drawing, sketching, highlighting (Kim et al., 2020), annotations, and conversations, powered by advanced human-computer interaction, smart interfaces, and generative AI (OpenAI, 2024), which will open up new fronts in data analysis to help us better understand learners.
-
Workshops on Intelligent Textbooks Research
This special issue was motivated by the success of the International Workshop on Intelligent Textbooks, which served as the main forum for reporting progress in this research field over the last five years. Altogether, 54 contributions have been presented at the workshop and published in its proceedings from 2019 to 2023 (Sosnovsky et al., 2019, 2020, 2021, 2022, 2023). Our analysis of these contributions identified eleven main research topics:
- Intelligent and Adaptive Interfaces
- Smart Content Integration
- Content Analysis and Knowledge Extraction
- Learning Content Extraction and Generation
- Intelligent Textbook Authoring and Generation
- Interaction Mining and Behavior Modeling
- Social Interaction and Crowdsourcing
- GenAI-based Textbooks
- Intelligent Textbook Pedagogy
- Domain-Specific Textbook Prototypes
- Bridging Physical and Digital Textbooks
Figure 6 attempts to visualize chronologically how these topics were represented in the papers published in the workshop proceedings in different years and how the community interests evolved. The numbers in the table indicate how many papers that year covered this particular topic. The area of a topic zone in the diagram visualizes the corresponding ratio of this topic. Since many papers covered more than one topic, these areas do not reflect the direct percentage of papers covering the topic but rather the relative focus of the topic compared to all other topics covered that year. For example, in 2019, 10 of 14 papers described different forms of adaptive and intelligent interaction between the interfaces of intelligent textbooks and their users. However, the same papers covered many other topics as well; hence, the area visualizing this topic’s contribution that year corresponds to 27% (instead of 71%). On a relevant note, we have noticed that with time, papers have become more focused on a single technology rather than on a combination of those (while in 2019, an average paper could be attributed to 2.4 topics, these numbers gradually decreased: to 1.7 in 2023). This might reflect the growing maturity of the research presented at the workshop, as the authors gradually started to spend more effort exploring individual technologies rather than presenting projects and prototypes that attempted to do many things at once. It is important to note that the identified topics might differ in granularity, which would influence their representation in the papers. A more detailed analysis could show additional trends; however, even on this level we can see the evolution of the intelligent textbook research over the 5 years.
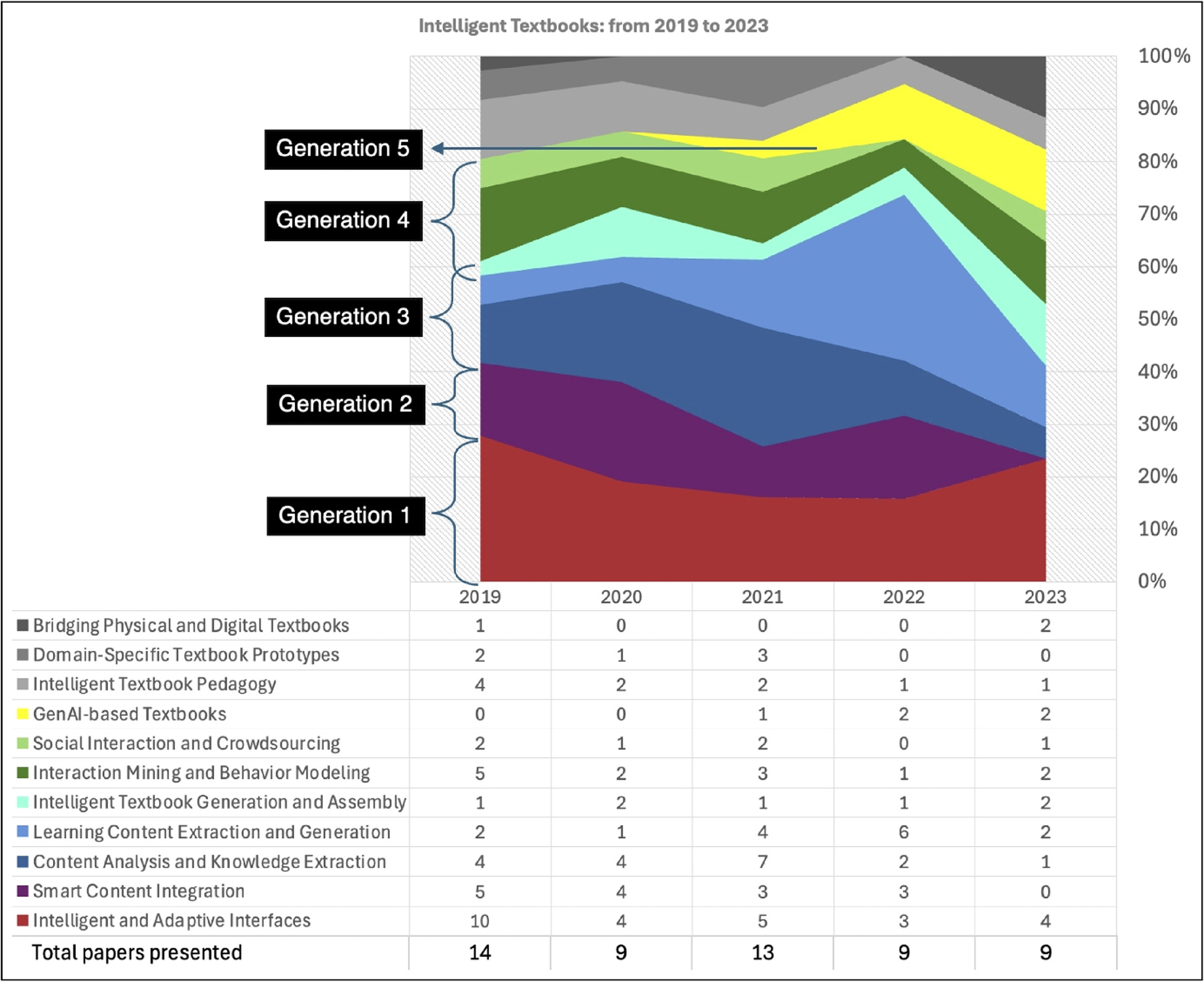
Fig. 6. Analysis of papers published in proceedings of workshops on Intelligent Textbooks -
workshops on Intelligent Textbooks
To make a connection to the previous section, Figure 6 associates (combinations of) topics with the key goals explored by the five generations of intelligent textbooks. It is clear that adaptive support of interaction with textbook content (Generation 1) remains an important aspect of what is considered to be intelligence in intelligent textbooks. At the same time, semantic integration of external interactive resources with textbooks (Generation 2) has gradually given way to approaches focusing on the extraction of knowledge and interactivity from textbooks using methods of ML, symbolic NLP, and content analysis (Generation 3). In turn, very recently, this line of research itself gave way to a new wave of papers driven by the recent success of Large Language Models (Generation 5). We think that this trend will continue and expect to observe both development of new prototypes fully powered by generative AI and enrichment of already developed successful tools with new generative AI technologies. Finally, we see that the stream of research focusing on data-driven and social aspects of intelligent textbooks (Generation 4) has remained stable over the years. The remaining three topics could be classified as miscellaneous. They do not constitute a particular trend, yet provide unique perspectives and ideas on how intelligent textbooks can be enhanced, organized, or orchestrated. The remainder of this section discusses the identified topics in more detail.
Intelligent and Adaptive Interfaces
Intelligent and adaptive interfaces for online textbooks could be considered as an “end product” of several other research directions. This is where the “intelligence” reaches the readers by augmenting their textbook experience with a range of functionalities not available in traditional textbooks. While these new functionalities are typically based on knowledge modeling and processing technologies, the main concern of papers focused on intelligent interfaces is not these foundation technologies but how to use them to offer the new functionalities and extended support to the readers. Among interface-focused papers presented at the workshops, several paper focused on open student models - a visual presentation of learned knowledge and progress (computed by AI student modeling algorithms) to the learners (Barria-Pineda et al., 2019). Other papers focused on such technologies as personalized guidance within the textbook, run-time recommendation of external learning content (Rahdari et al., 2020), and enhancing user interactions with interactive tools such as concept maps and chatbots.
Smart Content Integration
One of the appealing ways to extend online textbooks with additional functionalities not available in traditional textbooks is adding so-called “smart content” items - interactive activities, which engage students into learning by doing (rather than just by reading). Since most of these “smart content” items are in fact learning exercises supporting automatic assessment, working with smart content also enables students to check their understanding of content and receive feedback on their performance. Although only a fraction of “smart content” activities could be intelligent by themselves (i.e., ITS problems with intelligent scaffolding), the work on smart content is important for intelligent textbooks as a whole. Most importantly, “smart content” activities produce a much richer volume of learning data that is crucial for both student modeling and knowledge extraction. The work on smart content has been well-represented at the workshops, especially in papers focused on computer science textbooks, the domain where smart content is becoming increasingly popular (Bommanapally et al., 2020; Alpizar-Chacon et al., 2021; Barria-Pineda et al., 2022; Javadian Sabet et al., 2022). The key research issues examined in the workshop papers focused on smart content are infrastructure (how to connect an interactive item to a textbook while maintaining authentication and data collection) and content matching (how to assign a smart content item to its proper place within a textbook) (Matayoshi & Lechuga, 2020; Javadian Sabet et al., 2022). Smart content grouped with intelligent interfaces forms the first large research theme that focuses on textbook enrichment with additional features and functionality.
Content Analysis and Knowledge Extraction
Textbooks can be seen not only as an object of enrichment, but also as a source of domain knowledge. Modern textbooks are often distributed in XML-based formats, facilitating automated extraction of this knowledge, and even when such extraction is hindered by a textbook format (such as PDF), successful attempts have been made to exploit textbook organization and structure as latent representation of knowledge encoded in a textbook content. The works published in the workshop series have covered many different subtopics related to knowledge extraction. Several papers discussed the construction of knowledge representations from textbooks, using a wide range of approaches, from human-labeling to automated construction via both traditional feature-based NLP techniques and modern embedding-based NLP techniques. Most of them focused on the extraction of topics and concepts. Several works focused on extracting prerequisite-outcome (and other types) of relations and studied the noisy nature of this process (Alzetta et al., 2020; Waters et al., 2021). The extracted knowledge representations can be useful in many downstream tasks, including entity relationship visualization (Passalacqua et al., 2019), matching between textbooks (Alpizar-Chacon & Sosnovsky, 2019) and between textbooks and external learning content (Matayoshi & Lechuga, 2020; Javadian Sabet et al., 2022), monitoring ideas in student discourse (Zhong et al., 2020), and personalized learning support (Thaker et al., 2019).
Learning Content Extraction and Generation
The motivation behind this stream of research is very similar to that of the previous topic. Textbooks are collections of purpose-driven, well-structured, high-quality educational content. Many of them follow predictable formatting patterns and structuring rules. This makes textbooks a valuable source for harvesting modular typified learning material. Rapid development in ML and NLP research facilitated the increase in the number of works on automated extraction or generation of such material based on textbook content. Most of the articles that covered this topic focused on the generation of assessment questions, from multiple-choice to short-answer (Dresscher et al., 2021), and from factual to reasoning (Van Campenhout et al., 2021). In addition, several works explored the feasibility of generating other types of learning content, such as hints (Pavlik et al., 2020) and definitions (Sovrano et al., 2022).
Intelligent Textbook Generation and Assembly
Another stream of research explored by the workshop authors is the generation and assembly of textbooks. The published papers on this topic are not always characterized by a uniform methodology or common attributes of the final product. Some of them have much in common with the two previous topics as they try to exploit ML and NLP methods to automatically generate textbooks from available content. Other papers described projects that focus on the manual construction of textbooks by like-minded users. Yet, they have had a common objective - propose a technology that facilitates creation of digital textbooks from external resources. These resources range from Wikipedia (Pursel et al., 2019) content to domain-dependent material such as Jupyter notebooks (Bommanapally et al., 2020) to existing digital textbooks in PDF format (Alpizar-Chacon & Sosnovsky, 2019). The proposed technologies ranged from a community-oriented authoring platform for the assembly of digital textbooks (Pursel et al., 2019) to a framework for the automated generation of intelligent textbooks enriched with semantic and adaptive services (Alpizar-Chacon et al., 2020). Given its roots in two different research trends – automated generation and community-driven authoring (Fig. 6) – this topic has been associated with the two corresponding generations of research in intelligent textbooks.
Interaction Mining and Behavior Modeling
Most technologies presented at the workshop are aimed at developing and/or supporting complex applications built around textbooks. These applications provide their users with various methods of interaction with the actual content of textbooks, integrated smart content items, and value-adding services enriching textbook functionality. Using traces of these interactions to data-mine sessions, sequences or episodes of students’ reading and learning activity engagement has been a common topic for several workshop contributions (Kim et al., 2020; Heo et al., 2023). Some of these papers go a step further trying to formulate models of student behavior and data-mine rules that would help to classify students’ activity into typical behavioral patterns, predict which model of learning behavior a student is exhibiting, or associate them with factors and parameters of students, textbooks, or learning (Thaker et al., 2019; Kim et al., 2021; Seidel & Menze, 2022).
Social Interaction and Crowdsourcing
The next topic focuses on textbooks as an educational artifact that (potentially) attracts social interaction and collaboration. These social and data-driven approaches seek to employ the so-called “wisdom of the crowd” to improve the interaction between the textbook interface and its users or engage its users in productive engineering tasks. Different forms of social navigation are examples of the former (Barria-Pineda et al., 2019). The latter has explored different ways of organizing the interaction between users and textbooks in such a way that the textbook application could crowdsource the execution of challenging tasks to its users. The outcomes of these interactions would provide the textbook application with the elements of crowdsourced “intelligence” (e.g., concept map-based exercises helping extract types of relations between domain terms (Waters et al., 2021), or text highlighting behavior helping to train a student modeling approach Kim et al., 2020).
GenAI-based Textbooks
The recent success of generative AI has not been ignored by the Intelligent Textbook community. Several papers have explored the use of LLMs for various tasks that can be powered by the automated analysis of the content of digital textbooks and generation of texts that are relevant, fluent, purposeful. The first of these papers - an early adopter of LLMs - experimented with a fine-tuned version of the GPT-2 model to generate short definitions of potentially unfamiliar concepts that a reader might encounter in an academic textbook (Yarbro & Olney, 2021). More papers followed a similar path and used different versions of LLMs to analyze digital textbooks and generate relevant reading comprehension questions (Dijkstra et al., 2022), concept explanations (Sovrano et al., 2023) and answers to students’ questions on the subject of a textbook (Boateng et al., 2022). Finally, one of the papers looked at the content of textbooks and the accompanying indices as a rich source of expert-provided annotations of concepts-rich texts, and used it to fine-tune a deep learning model to recognize these concepts in new textbooks from the same domain (Pozzi et al., 2023).
Intelligent Textbooks Pedagogy
Although, this topic has not been among the most popular directions of reported research, every year the workshop featured a few papers focusing on the pedagogy of designing and deploying intelligent textbooks (Ou et al., 2022), organization of classes using intelligent textbooks, optimal combination of textual and interactive components in textbooks, and effective pathways that students should take when reading them. Some of these papers explore the effectiveness of organizing the interaction with digital textbooks according to well-established didactic approaches, such as programmed instruction (Mohammed et al., 2019). Ritter et al. (2019) proposed a vision for organising intelligent textbooks of the future, including a set of learning tools they should offer to students and orchestration of lessons around such textbooks. Kluga et al. (2019) talked about the importance of interacting with causal concept maps to understand textbook material. The importance of such research should not be underestimated. Although the technology side of intelligent textbooks has been progressing with high pace, empirically proven recipes for effective use of these technologies are still in short supply. At the same time, excessive focus on technology-driven innovation without considering whether or not a developed technology can enable an effective instructional approach is unlikely to produce a useful educational tool.
Domain-Specific Textbook Prototypes
Intelligent textbooks are broadly applicable in many subject domains. Therefore, textbooks that are customized to the unique features of each subject domain are necessary. For example, in the domain of programming, intelligent textbooks can benefit from embedded or integrated smart content allowing students to interact with worked programming examples, solve code analysis exercises and Parsons problems, etc. (Ericson & Miller, 2020). In the domain of quantum cryptography, intelligent textbooks can benefit from built-in interactive visualizations and self-graded quizzes, driven by student objectives. In medical domains such as dentistry and cardiovascular anatomy, intelligent textbooks can benefit from chatbots built into the textbook to ask learners questions and interact with them or take the form of a mobile application helping students learn the logical connections behind key technical terms. Several papers presented at the workshop explored these domain-specific forms of interaction with textbooks and how the users of these textbooks can be intelligently supported (Kluga et al., 2019; Bommanapally et al., 2020; Alpizar-Chacon et al., 2021; Tauqeer et al., 2021; Barria-Pineda et al., 2022).
Bridging Physical and Digital Textbooks
Finally, over the years, the workshop has attracted several unique contributions that are hard to associate with any of the larger trends. A frequent theme for these papers has been an attempt to develop intelligent applications that accompany a paper-based textbook. One of the papers has used a specific term to describe these prototypes: phygital textbooks (blending physical and digital). One example of intelligent textbooks applications exploring this line of research is a tool using paper-based workbooks and a mobile app scanning to enable grading and feedback to hand-written solutions (Feng et al., 2019; Asakura et al., 2023). Another example is an augmented reality system that maintains a digital twin of a paper-based textbook enriched with interactive graphics, on-the-spot assessment, and social note taking (Saindane et al., 2023).
-
The Special Issue of IJAIED on Intelligent Textboo
It was our experience with the Intelligent Textbook workshop that motivated the special issue of the International Journal of Artificial Intelligence in Education on Intelligent Textbooks. The five years of workshops demonstrated an increased interest in the topic as well as a growing maturity of research in this area. The special issue was proposed to the journal, accepted, and announced to the community. The editorial process for this special issue has been organized in two phases. First, interested authors submitted extended abstracts that describe the main contributions of the intended papers and their relevance to the theme of the special issue. Nineteen of such abstracts were received and reviewed by guest editors; authors of nine of them were invited to submit full versions of their papers. Each of the submitted papers was reviewed by at least three reviewers and a guest editor. The final set of papers accepted for publication after several rounds of review includes four submissions.
The papers that form this special issue provide new contributions to the key topics presented in Fig. 6 and follow the trajectory of the development of the state of the art in the area of Intelligent Textbooks. The papers represent a healthy combination of methods and approaches from the third, fourth, and fifth generations of intelligent textbooks.
Sovrano et al. (2024) focuses on providing on-demand explanations to learners using intelligent textbooks, doing so by extracting a knowledge graph from a collection of textbooks and other learning resources. The authors conducted an experiment in the context of legal writing education to show that the enriched textbook leads to better learning outcomes than the baselines. This approach fits into the third and fifth generation of intelligent textbooks, using both more traditional technology such as knowledge graphs and more recent technology such as generative question-answering models. These technologies cover the topics of knowledge extraction, textbook authoring and generation, and genAI-based textbooks, while the end product contributes to the topic of domain-specific textbook prototypes.
Jonnson et al. (2024) follows up on a series of papers in the International Workshops on Intelligent Textbooks on question generation, using approaches that were commonly used before the emergence of LLMs. This work enriches textbooks with generated questions, with an added twist, parallel construction: Questions are generated in English and translated into other languages for existing parallel corpora (textbooks and their translated versions). This approach fits into the fifth generation of intelligent textbooks, also covering the topics of learning content generation and intelligent textbook authoring and generation.
Morris et al. (2024) uses LLMs to generate feedback on student-written summaries of textbook content. This paper isolates two aspects from the scores given to student-written summaries: content and writing, and develops an LLM-based classifier to score these aspects and provide feedback to students. It combines the technologies of the fourth and fifth generations of intelligent textbooks through the analysis of student-written summary scoring data and the use of LLMs for a classification task. These approaches cover the topics of learning content extraction and generation, interaction mining and behavior modeling, and genAI-based textbooks.
Blobstein et al. (2024) continues the fourth-generation trend of extracting useful knowledge from a large volume of interaction data generated by textbook readers. The interesting source of learner data leveraged by this work are students’ annotation in the form “emojies” or hashtags that students use to represent their emotions and other types of reactions to the text they read. The paper demonstrated that aggregating student annotation data could help teachers understand which parts of the text have been challenging or interesting. It also explored the feasibility of using LLMs to predict student annotations.
-
Conclusions
Despite its long history, Intelligent Textbooks remain a field of innovations where new approaches are introduced and explored in various studies (Kukulska-Hulme et al., 2024). Intelligent textbook researchers eagerly adopt technologies developed outside of the field and come up with use-cases and application scenarios that expand the capabilities and potential effectiveness of textbook prototypes. Textbooks continue to be one of the primary sources of knowledge for students, despite more interactive, non-textual content gaining popularity in many other tasks and contexts.
It is time for textbooks to enhance their functionality with interactive features that improve the overall effectiveness of textbooks as learning tools (Clinton-Lisell et al., 2023). Adaptive textbook interfaces, smart content, intelligent services, and community-focused tools to engage with other users will transform learners’ study with textbooks into a more interactive and social learning experience. The new wave of generative AI that already fuels the current generation of intelligent textbooks opens up a wide range of possibilities to make learning with textbooks even more interactive and engaging. LLMs are highly capable of effectively transferring what they learn from pre-training on web-scale text to different contexts, resulting in high levels of fluency and consistency of the generated text. Currently, the most popular direction for these works is to use LLMs to automatically produce assessment questions for intelligent textbooks, with promising early results (Olney, 2023). In addition, new intelligent textbook prototypes are being built that employ generative AI to support new meaningful forms of interaction (Crossley et al., 2024). We expect more interesting works that will use the potential of these models in various forms of learner support around intelligent textbooks, especially if it builds on the success of the previous research. We hope that this special issue will be helpful for all researchers in the field of intelligent textbooks and will guide the future development of the field.
-
小组作品策展:综合利用智能体以及AI等工具,设计我心目中的新形态教材
活动类型:作业提交活动描述:作品:1.体现新形态教材的理念。 2.该教材旨在解决传统教材的什么问题。 3.该教材做了哪些设计以解决这些问题。 4.考虑多维交互以促进深度学习。 5.该教材目前还存在哪些局限性,未来优化目标是? PS:可结合文献说明第1、2、3点。-
小组作品策展活动说明
可结合某一主题的相关知识设计新形态教材/智能教材:例如,在线学习交互(等效交互定理、教学交互层次塔等)、探究社区(认知存在感、教学存在感、社会存在感等)、在线学习的网络支持(知识网络、社会网络、认知社会网络等)等等。
思路引导:
1.先填写第六讲 小组设计新形态教材智能教材引导单:先根据用户移情图记录使用传统教材的真实感受,再总结传统教材的问题,然后利用头脑风暴法提出设计新形态教材/智能教材的方法/方案,最后小组选择最有价值的方法/方案。2.小组综合利用智能体以及AI等工具,设计新形态教材/智能教材,以实现最有价值的方法/方案。3.最后,上传与AI工具交互的对话链接(链接中包含新形态教材/智能教材的“实体”)(PS:可参考下方助教设计的2个案例),并简要说明小组设计的新形态/智能教材的旨在解决传统教材什么方面的问题、功能、特色、现有不足和未来改进方向。提交:引导单word文档(命名格式“第X组-组长-组员”),和,新形态教材/智能教材(在引导单中,提交与AI交互的对话链接即可,确保链接能打开)。
相关案例:
1.AI数字教材课程一体化应用平台(中教云):《新能源汽车技术》新形态教材(试看版)
【PS:平台注册后,可在“一书”的“前往教学平台”的“教材库”查看新形态教材案例】
2.上海财经大学《中国金融史》知识图谱版AI新形态教材一体化新生态创新实践 3.数智教材来了!北大发布全球首创AI智能书,教材将迎来哪些改变?
设计新形态教材/智能教材的平台 & AI工具(不限于此,仅供参考):
1.Jupyter Book ——把课本写成 .md/MyST格式,嵌入代码、公式、图表、交互组件 2.文希AI 3.笔启AI 4.海棠AI
助教老师与各AI交互后设计的“简易版”“探究社区”主题新形态教材(仅供参考):
1.探究社区主题新形态教材(Deepseek版本) 2.探究社区主题新形态教材(文心一言版本)
PS:可基于自身与小组对新形态教材/智能教材的思考与想法,通过智能体 V4.0(https://www.coze.cn/s/zlp3oxS7r7g/)对话,查找相关文献或案例,以启发思考。
例如:“请检索有关‘XX(新形态/智能/智慧教材等)’的国内外文献,谈谈如何AI设计新形态教材?”或:“请提供利用相关技术设计新形态/智能教材的案例。”-
提问答疑
活动类型:提问答疑活动名称:提问答疑活动描述:同学们好!欢迎学习第六讲。大家可将文献研读和活动参与中遇到的疑问,发布在提问答疑区。 无论是概念理解还是案例分析,都可以畅所欲言。也可提问前几讲的相关问题。 助教会在这里实时跟进,为大家即时解答。 也鼓励同学们相互解答,共同攻克难点! PS:可匿名提问,但必须围绕课程或活动内容!-
与AI交互设计新形态教材
活动类型:社会化批阅活动名称:与AI交互设计新形态教材活动描述:每个同学至少评价2个作品,且不能评价自己组。 评价依据: 1.作品是否体现了新形态教材的理念;2.作品是否逻辑结构清晰严谨,内容是否完整详细;3.作品是否回答了新形态教材的哪些焦点问题,是否具有创新性-
小组作品策展
-
群智汇聚,新的思考
活动类型:讨论交流活动名称:群智汇聚,新的思考活动描述:请结合所学,讲讲自身对 新形态教材或智能教材 新认识(包括 新思想/观点/技术/方法等) 1.每位同学至少发表1条帖子 2.评论至少3位其他同学的帖子 3.回复自己帖子下方的同伴/助教评论 PS:有理有据,附文献来源或标注知识来源(如智能体,自我思考或群体启发等)-
讨论交流活动说明
讨论要求:1.每位同学至少发表1条帖子 2.评论至少3位其他同学的帖子(如质疑、补充等) 3.回复自己帖子下方的同伴/助教评论
可聚焦讨论主题,结合以下问题贴例加以思考,或对同伴的观点进行评价或质疑:
思考点/问题贴例:
1.直接用通用大模型问答替代教材内容可行吗?这会不会削弱学生深度阅读和系统化构建知识体系的传统优势?
2.将智能教材/新形态教材与MOOC/社交媒体(新元素)合并,能否真正促进协作学习,还是仅仅制造了更多碎片化的信息干扰?
3.理科强调逻辑推演,文科强调发散思维,目前的智能教材模板是否需要针对不同学科的认知规律进行深度改造?
4.传统的线性教材结构是否应调整(修改/放大/缩小)为完全的非线性网状结构?这种调整对学生的系统思维培养是利大于弊还是反之?
5.智能教材产生的大规模学情数据,除了用于教学,能否用于预测区域教育趋势或辅助公共教育政策制定?
6.如果学生过度依赖教材的自适应推荐,我们是否应该刻意“消除”部分便捷功能,强制培养其信息检索能力?
7.教材评价通常由专家制定,能否逆向由学生的实际学习效果来反向评判教材算法的优劣,并据此自动迭代?PS:在讨论过程中,可通过与智能体 V4.0展开对话(https://www.coze.cn/s/zlp3oxS7r7g/),协助思考,或与同伴开展观点辩论。
高质量帖子标准:1.能够引发多种观点;2.需要分析推理,而非简单查找;3.可以持续引发深入讨论;4.结合在线学习情境。
讨论内容需体现以下至少1种行为:解释(对观点进行阐述或补充)、质疑(提出不同观点或挑战)、整合(综合他人观点形成新理解)。
-
个体学习反思
活动类型:反思活动活动名称:个体学习反思活动描述:1.上传第五讲、第六讲你与智能体,以及其他AI工具对话的长图(确保图片清晰可见),或网址链接(确保能打开),或word文档都可以。 2.填写学习反思单,反思对智能体,以及其他AI工具的使用(结合第五讲/第六讲的具体活动去描述)。-
学习反思活动说明(20260705截止)
4F反馈法是一种非常经典的反思模型,分别代表:Facts(事实)、Feelings (感受)、Findings (发现)和Future (未来/下一步)。这种方法可以帮助你从单纯使用智能体和其他AI工具的学习经历回顾,走向深度的批判性思考和行为改进。
***个体反思活动纳入平时成绩。【1.不以智能体使用能力/AI使用能力作为评分依据。2.重点考察提交的文档或长图的时间,与课程使用“智能体及其他AI工具”的时间对应(即:真实性、完整性和清晰度)。3.使用的智能体及AI工具类型及数量不做限制。】
提交截止时间:2026年7月5日
PS:针对你“与智能体及其他AI工具对话”,以及过去四讲学习中的“人机协作”的任务要求,填写第六讲 学习反思单,反思4个问题(但不限于此,如果有其他反思也可填写在反思单中提交)。
注:1.第五讲和第六讲学习中的“你与智能体及其他AI工具对话”,几种方式任选一种:(1)填写可以打开的链接;(2)插入清晰可见的长图(上次多位同学提交的长图不清晰,建议采用第一种或第三种方式);(3)把学习反思单,以及导出的对话文档/长图放到一个文件夹里上传,并为每个文档和图片备注属于第几讲。2.如果在上次还没有提交第四讲的“你与智能体及其他AI工具对话”,也可以在本次反思单中补充。
另外,前期,何雨轩同学的个体学习反思中,有“推荐使用软件verycapture,可以长截图,很好用!”(需要的同学可参考,但不限于此)
-
-
- 标签:
-
加入的知识群:
.jpg)

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~