-
PISA数据预处理和基本分析
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
实验一:PISA数据预处理和基本分析


教育数据挖掘方法与应用实验报告
姓名
金宣萱
学号
202105720113
年级
2021级
专业
教育技术学(师范)
学院
教育科学与技术学院
实验一:pisa数据预处理和基本分析
-
一、实验目的
对这个pisa_stu_data_1数据进行预处理,要求查找并处理缺失值何异常值,进行基本数据分析。
-
二、实验工具
spssmodeler
-
三、实验原理
pisa数据预处理实验的原理基于数据清洗与准备的概念。它涉及多个步骤和技术,旨在确保数据的完整性、一致性和质量,使数据适合进行后续的分析和建模:
1.数据质量检查:这是数据预处理的首要步骤。它涉及识别和处理数据中的缺失值、异常值、重复数据或错误数据等。这种检查有助于确保数据的准确性和可靠性。
2.缺失值处理:数据中可能存在缺失值,这会对分析结果产生负面影响。处理缺失值的方法可以是删除含有缺失值的样本、使用统计方法填补缺失值或者利用机器学习模型进行缺失值的预测。
3.异常值处理:异常值可能是数据输入错误或表示真实但极端的情况。识别和处理异常值的方法包括使用统计指标(如标准差、箱线图等)进行检测,并根据领域知识或算法将其视为异常并进行处理。
4.数据转换和规范化:这个步骤涉及对数据进行转换,使其适合特定的分析或建模需求。例如,对数据进行归一化、标准化或进行对数变换,以改善其分布或特征的表现。
5.探索性数据分析(eda):这是一种数据分析方法,通过可视化和统计方法来探索数据的结构、关系和趋势。它有助于了解数据特征、变量之间的相关性,并为后续分析提供洞察和思路。
实验的原理在于通过以上步骤和方法来清理、准备和探索数据,以确保数据的质量和准确性,为进一步的分析和建模提供可靠的数据基础。这样做可以提高模型的准确性,并支持更深入的数据洞察和决策制定。
-
实验步骤
1.数据导入:
·使用"数据源"节点导入pisastudata_1文件。
2.数据探索:
使用“数据审查”节点对数据进行初步探索,查看数据的整体情况,了解变量的分布、数据类型等信息。
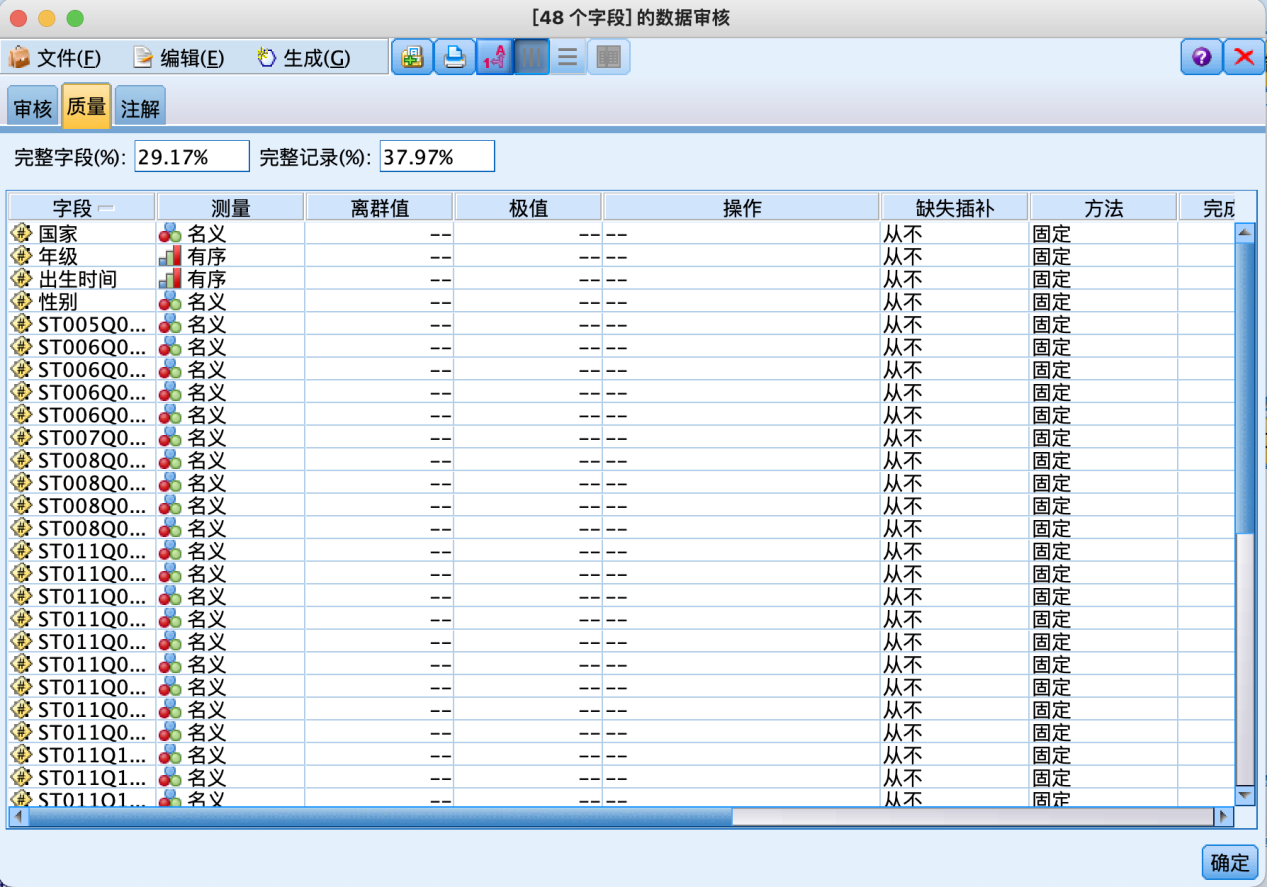

初始文件共24527条记录,其中完整字段29.17%,完整记录37.97%
-
数据填充,重写数据


4.缺失值处理与异常值处理:
使用"数据审核"节点检查数据类型,确认是否存在缺失值。

考虑到字段bodyima和soconpa极值过多,若选用平均值插补会对其造成较大影响,因此首先对两字段进行极值丢弃。完成操作后,利用数据审核查看发现完整字段为33.33%,完整记录为63.39%。

使用"插补"节点对所有完成率不到百分之100的字段处理缺失值,选择合适的方法填充缺失值,比如使用平均值、中位数、或者建模方法进行填充。本研究使用众数对缺失值进行填充。完成操作后,利用数据审核查看发现完整字段为100%,完整记录为100%。

当前的有效记录数为14694条

11.数据转换与规范化:
使用"导出"节点进行数据转换,例如对某些变量进行数值变换、归一化或标准化,以便更好地适应建模需求。
13.基本统计分析:
使用"统计"节点计算基本的统计指标,在统计节点中设置检查变量为调查中对学生家庭环境的调查结果,相关选择了pv1math(学生成绩的平均分),以探索学生成绩与家庭环境的关系。

15.可视化分析:
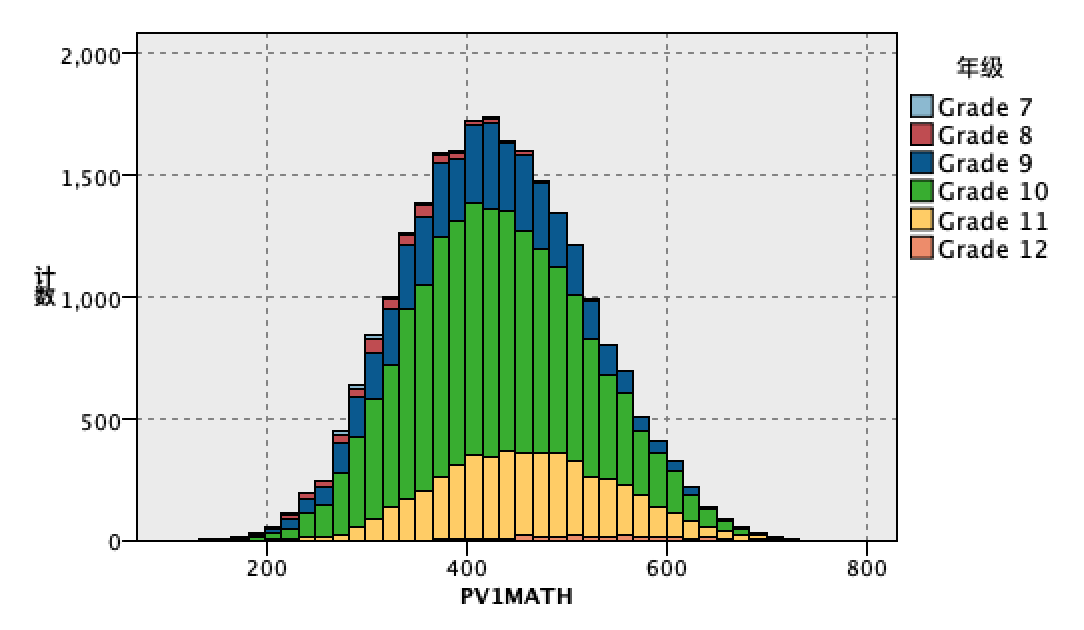
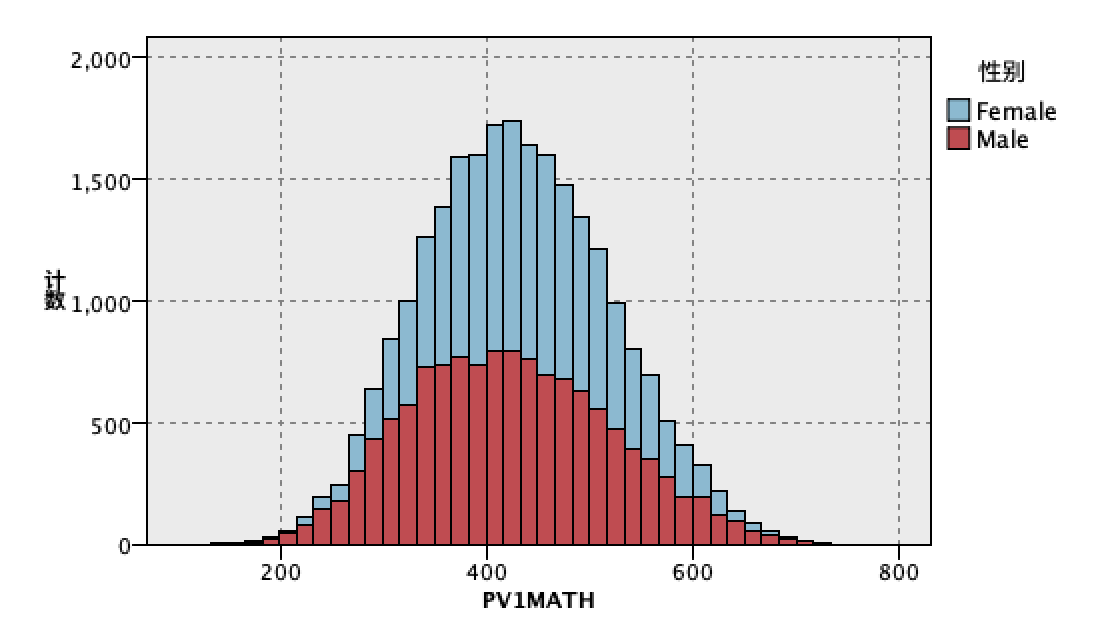
由于处理对象为孤立数据点而非连续线性数据,因此选用散点图进行数据可视化分析,创建散点图,根据统计节点分析结果,选择了st005q01ta(母亲最高教育程度)作为x轴,pv1math(学生成绩的平均分)作为y轴,选择性别作为交叠字段,产生如下散点图:

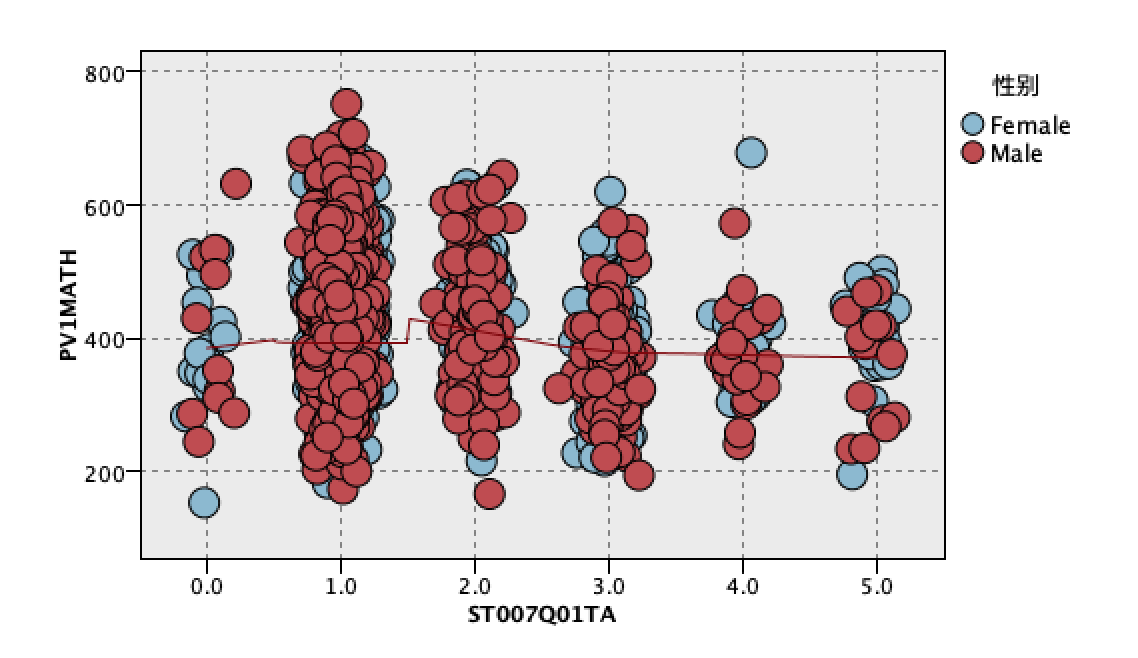
选择了st007q01ta(父亲最高教育程度)作为x轴,pv1math(学生成绩的平均分)作为y轴,选择性别作为交叠字段,产生如下散点图:
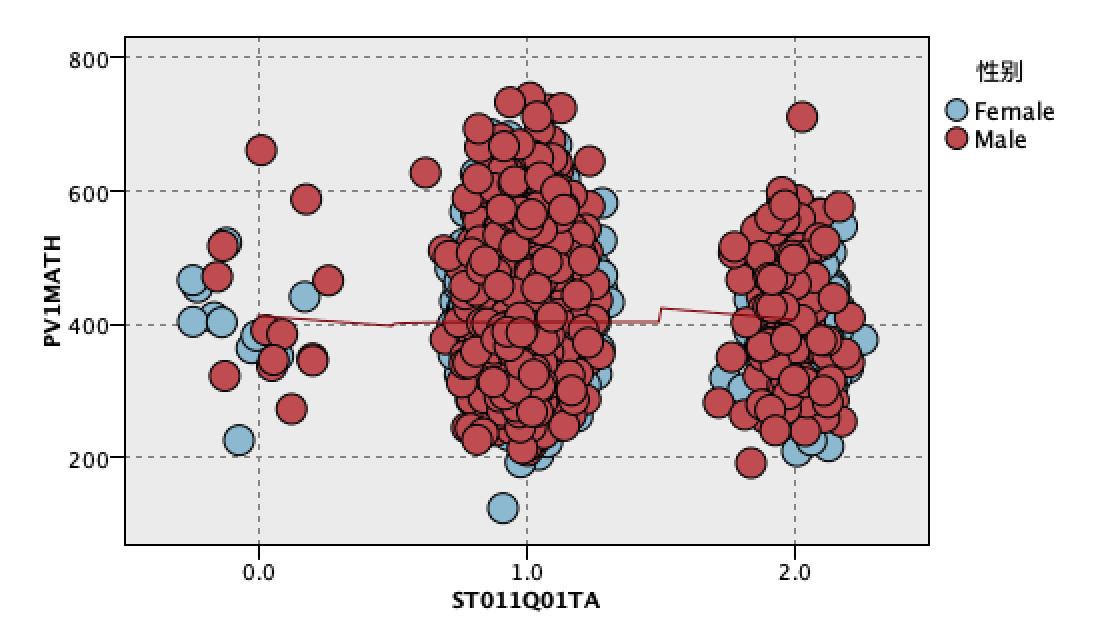
选择了st011q01ta(家里是否有课桌专门作为学习)作为x轴,pv1math(学生成绩的平均分)作为y轴,选择性别作为交叠字段,产生如下散点图:
-
-
- 标签:
-
加入的知识群:

.jpg)

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~