-
PISA数据预处理和基本分析
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
PISA数据预处理和基本分析(张亦瑄)


教育数据挖掘方法与应用实验报告
姓名
张亦瑄
学号
202105720433
年级
2021级
专业
教育技术学(师范)
学院
教育科学与技术学院
实验一:pisa数据预处理和基本分析
-
一、实验目的
对pisa数据进行预处理,查找并处理缺失值和异常值,进行基本数据分析。
-
二、实验工具
ibmspss modeler
-
三、实验原理
ibmspssmodeler从商业理解——数据了解——数据准备——模型建立——模型评估——结果部署,拥有一套完整的商业数据挖掘流程;同时spssmodeler将特征工程、算法模型都进行了封装,需要时直接进行调用,大大提高了分析效率。
数据质量检查是数据预处理的首要步骤,涉及识别和处理数据中的缺失值、异常值、重复数据或错误数据等,有助于确保数据的准确性和可靠性。
缺失值处理可以是删除含有缺失值的样本、使用统计方法填补缺失值或者利用机器学习模型进行缺失值的预测。
识别和处理异常值的方法包括使用统计指标(如标准差、箱线图等)进行检测,并根据领域知识或算法将其视为异常并进行处理。
数据转换和规范化对数据进行转换,使其适合特定的分析或建模需求。
数据可视化是利用图标进行数据分析,例如直方图、散点图。
本次实验原理在于清理、准备和探索数据,以确保数据的质量和准确性,为进一步的分析和建模提供可靠的数据基础。这样做可以提高模型的准确性,并支持更深入的数据洞察和决策制定。
-
四、实验步骤
数据导入
从“源”节点中拉出statistics文件至构建区,并将pisa数据导入。
数据探索
使用“数据审核”节点对数据进行初步探索,查看数据的整体情况,了解变量的分布、数据类型等信息。
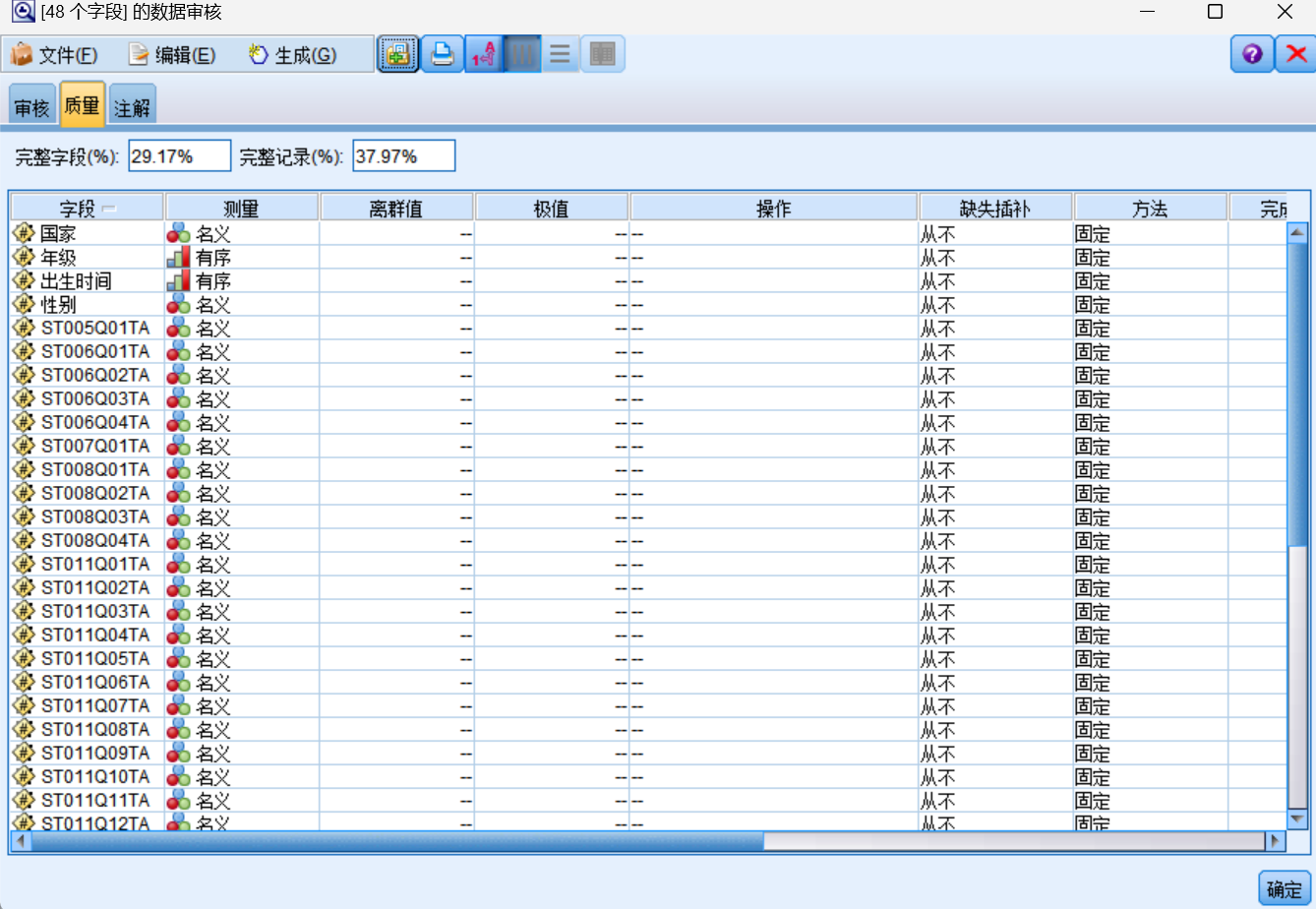
其中完整字段29.17%,完整记录37.97%。
缺失值处理与异常值处理
发现bodyima和soconpa两字段的极值过多。
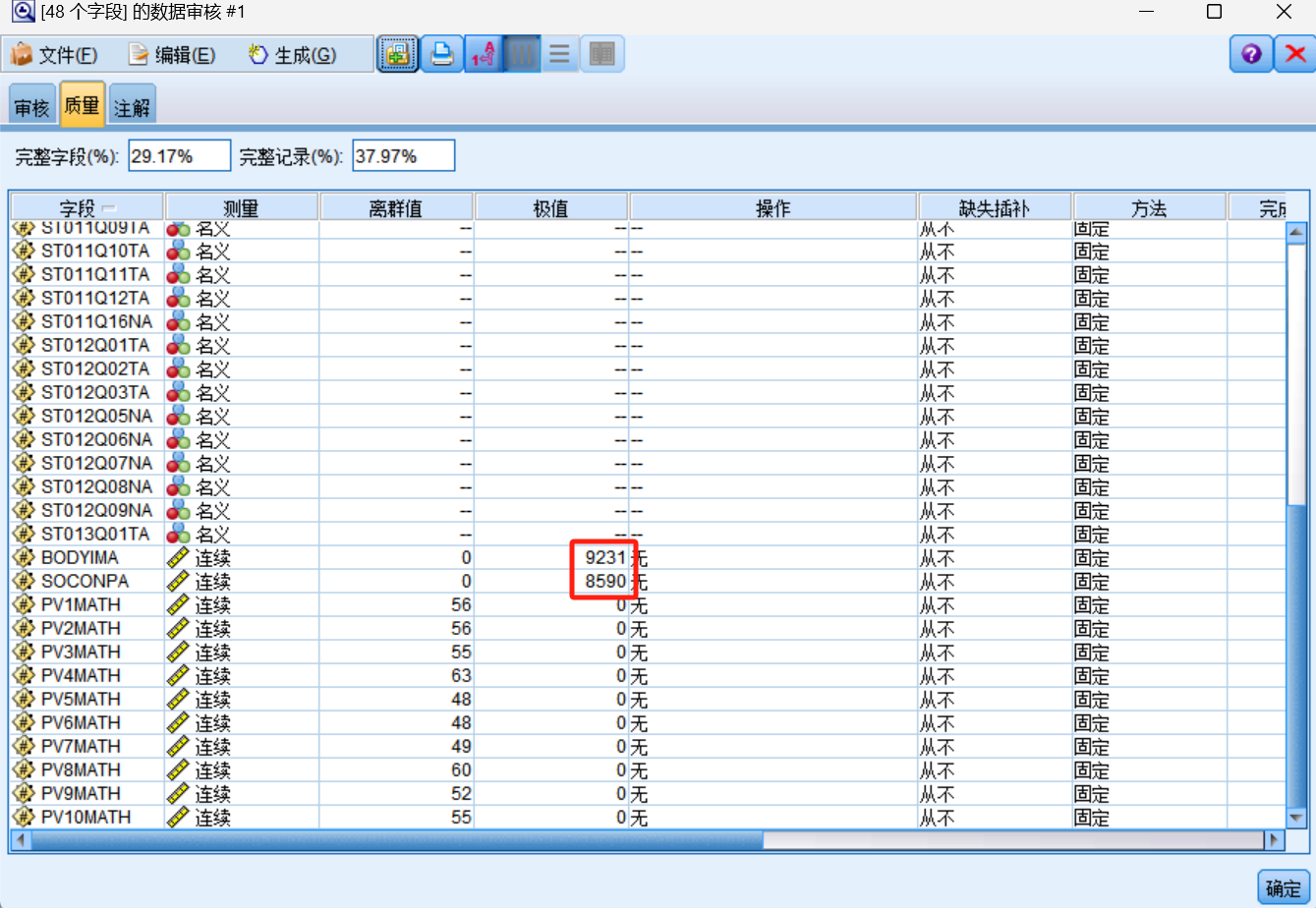
进行“强制替换离群值/丢弃极值”的操作。
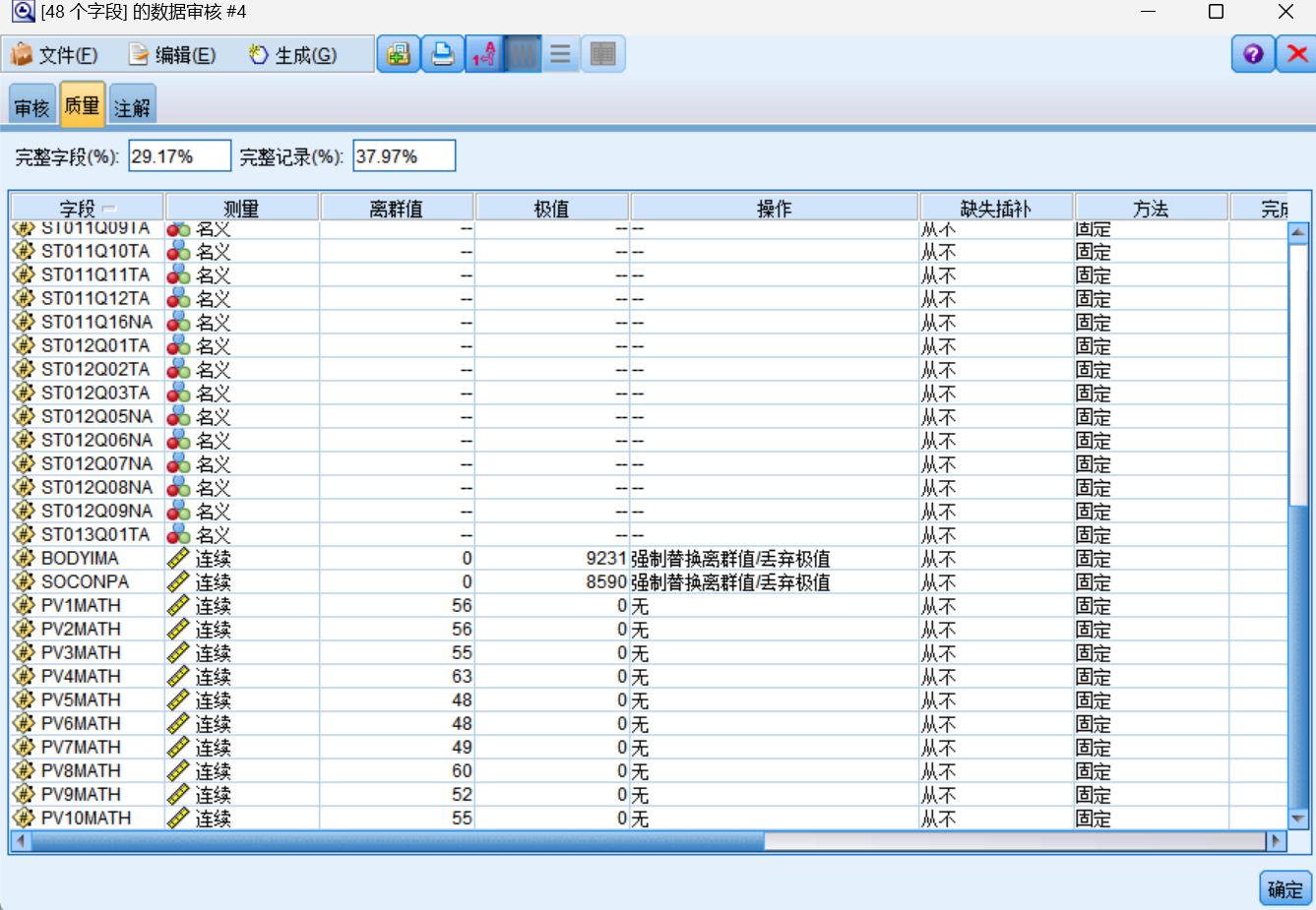
经过处理后的完整字段为33.33%,完整记录为63.39%。
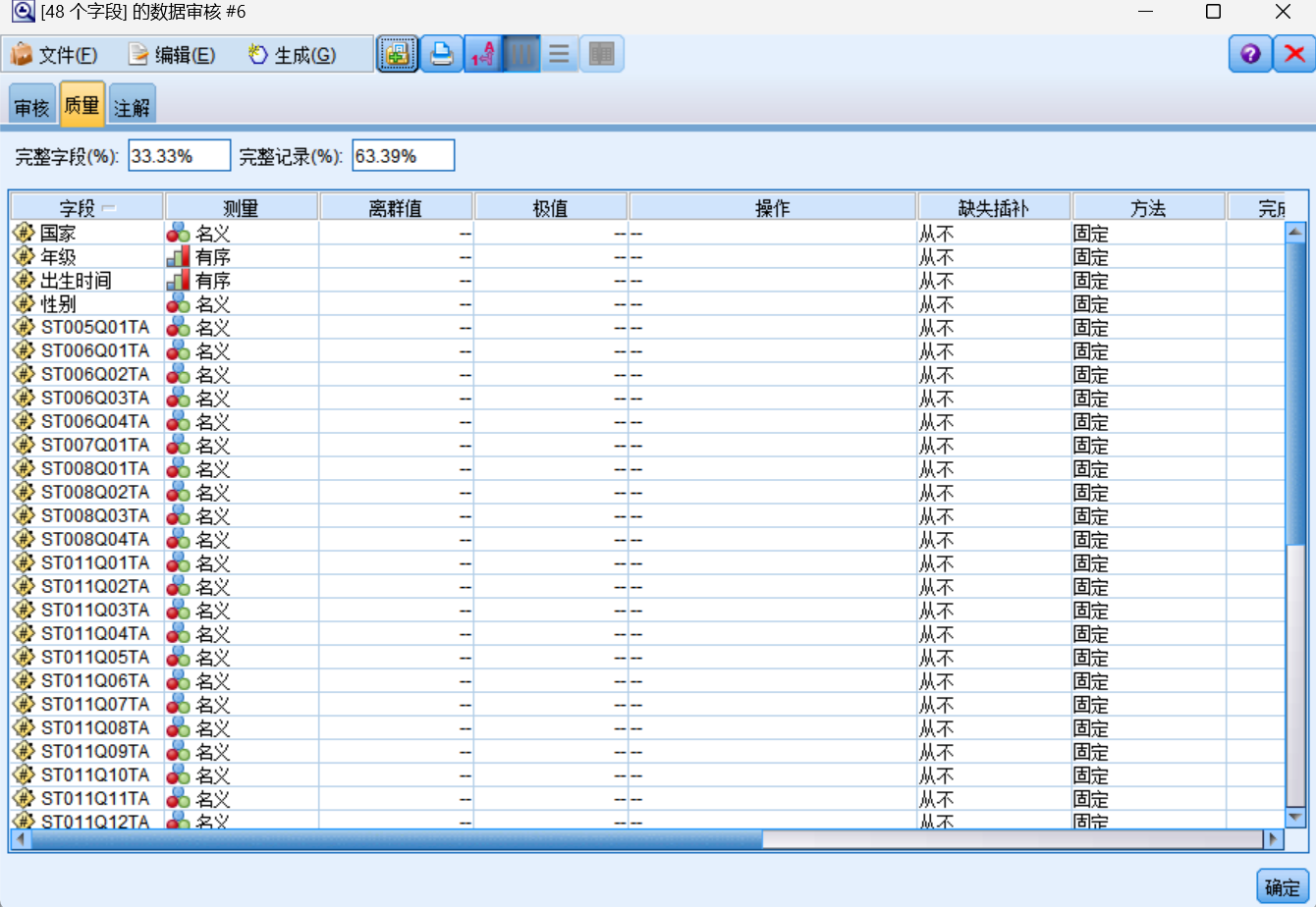
数据的完整性大幅提高,有效字段减少。
-
五、实验结果
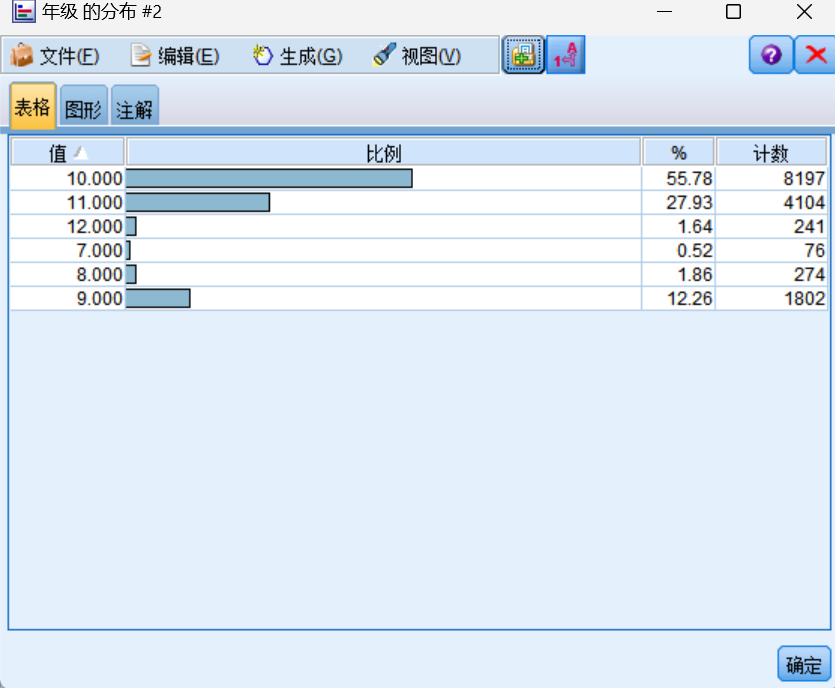
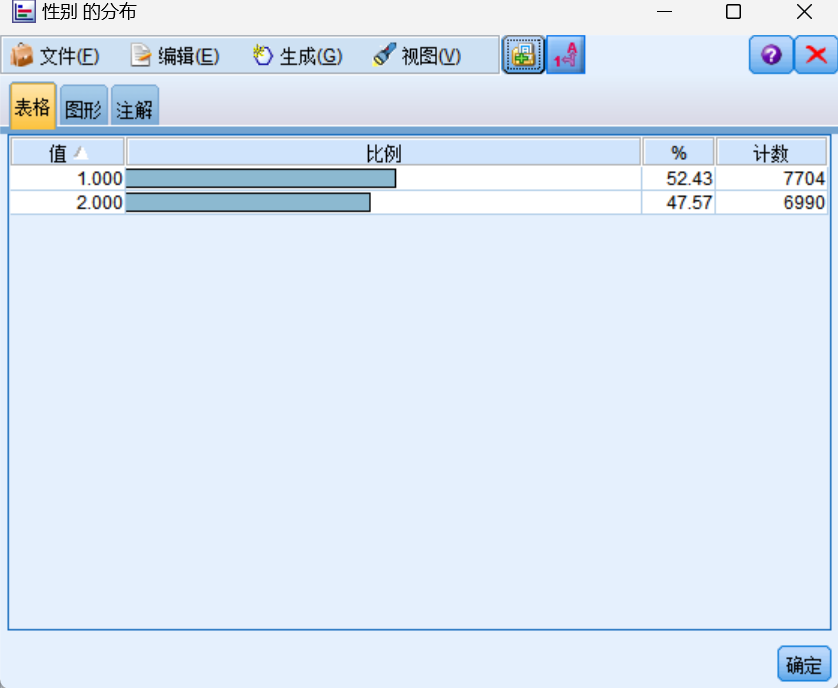
利用分布图可以看到年级、性别等数据的分布以及相关比例。
可以将年级设置为x字段,将pv1math设置为y字段,交叠字段为性别,查看其散点图,可以更直观地看到数据的分布。
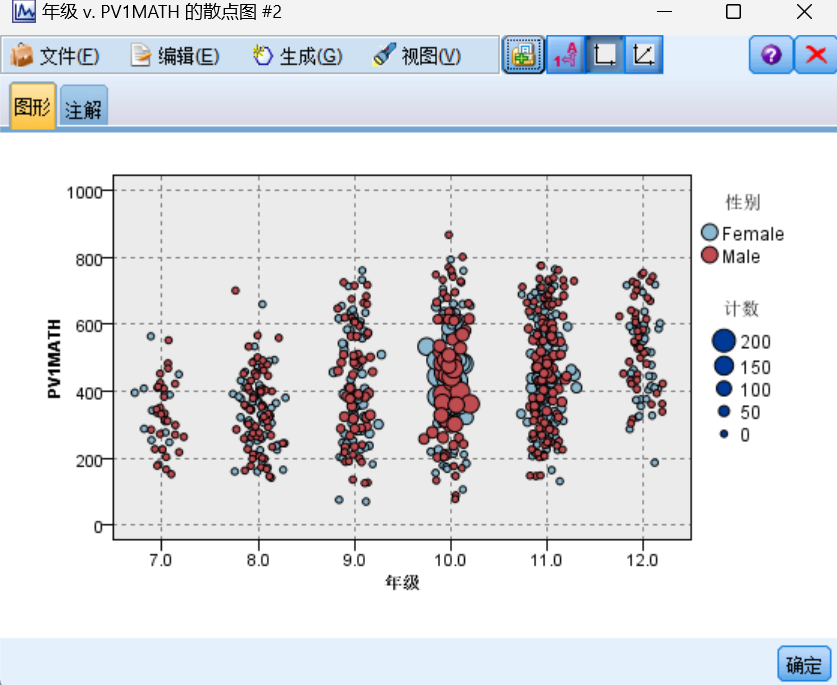
-
六、分析与讨论
查看班级同学个人平均分的分布时,各年级段的分数分布大致呈现正态分布。十年级的学生人数最多,而十二年级和八年级的人数则相对较少。此外,男生的数量多于女生。
且通过数据呈现出来的现象有学生学业成绩和家庭因素有着极高的相关性。家长教育程度为1等级的学生最为普遍。同时,有着好成绩的学生更有可能出现于家长教育程度为1等级的家庭中。
此外,家中有专门用于学习的课桌的学生占据绝大多数,同时,成绩优异的学生也更可能来自家里有用于学习的课桌的家庭。
-
七、总结或个人反思
缺失值处理部分,我采用的方法比较单一,存在着不严谨性。而在实际数据中,缺失值的原因可能有很多种,采用不同的方法处理如均值差补、回归差补等可能会更加准确。
异常值的处理,我采用了强制替换或者丢弃的方法,且选择处理方式的时候没有考虑到数据的背景,比较随意,存在着不严谨性。对于同领域的数据可能业需要不同的异常值处理策略,应该要灵活运用箱线图、z-score等方法,结合数据背景,更好地识别和处理异常值,以确保分析的准确性。
图形的选择部分,由于对于各种图形的优点和绘制还不是特别了解,在选择采用什么图形的时候比较随意比较简单,课后应该有自己的思考,总结每种类型的图形的优缺点,适用于呈现哪些信息,并在呈现数据信息的时候迅速准确的选取最合适的图形。
-
-
- 标签:
- PISA数据预处理和基本分析
-
加入的知识群:
.jpg)

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~