-
基于矩阵分解的个性化学习推荐
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
前言
随着信息技术的迅速发展,混合式教学成为热潮,在线学习平台为学习者提供了丰富多样的资源。海量资源供给、平台及技术支持使得学习可以随时随地进行,不再受时间和空间的限制,但要找到适合自己、且对学习有持续帮助的资源仍有一定困难。而个性化推荐技术可以有效的进行信息过滤,在繁杂冗余的信息中过滤出有实用价值的信息,既可以提高学习者满意度,又能促进在线学习的发展。矩阵分解是个性化学习推荐原理之一,在数学、工程技术、经济管理科学等领域,涉及了大量矩阵原理,其重要性由此可见。基于矩阵分解的个性化学习推荐可以针对个体差异性,提供多种与当前学习相关的参考内容,为后续学习提供便利。本小节内容将简单介绍矩阵分解原理的集中分类,以及基于矩阵分解原理的个性化学习推荐的实现过程[1]。
-
一.矩阵分解原理
矩阵分解是指将一个矩阵表示为结构简单或具有特殊性质若干矩阵之积或之和,大体分为三角分解、正交分解、满秩分解和奇异值分解。矩阵分解模型是一种非常适合用来构建实时推荐模型的算法,它通过训练用户的偏好模型来解决向用户做出实时推荐的问题。
1.基本原理
将推荐值矩阵R分解为矩阵U和P,使得U和P的乘积得到的矩阵R∗中的元素值与R中的元素值非常接近。那么R∗中对应于R中的未知元素值就是预测值。

2.分类
(1)三角分解
如果方阵A可表示为一个下三角矩阵L和一个上三角矩阵U之积,即 A=LU,则称 A可作三角分解。矩阵三角分解是以Gauss 消去法为根据导出的,因此矩阵可以进行三角分解的条件也与之相同,即矩阵A 的前 n-1 个顺序主子式都不为 0,即An不等于0.所以在对矩阵 A进行三角分解的第一步应该是判断是否满足这个前提条件,否则怎么分解都没有意义。矩阵的三角分解不是唯一的,但是在定的前提下,A=LDU 的分解可以是唯一的,其中D是对角矩阵。矩阵还有其他不同的三角分解,比如Doolittle 分解和 Crout 分解,它们用待定系数法来解求A的三角分解,当矩阵阶数较大的时候有其各自的优点,使算法更加简单方便。
(2)正交三角分解(QR分解)
正交三角分解法是求一般矩阵全部特征值的最有效并广泛应用的方法,一般矩阵先经过正交相似变化成为Hessenberg矩阵,然后再应用QR方法求特征值和特征向量。它是将矩阵分解成一个正规正交矩阵Q与上三角形矩阵R,所以称为QR分解法,与此正规正交矩阵的通用符号Q有关。如果实(复)非奇异矩阵A能够化成正交(酉)矩阵Q与实(复)非奇异上三角矩阵R的乘积,即A=QR,则称其为A的QR分解。
(3)满秩分解
定义:对于m×n的矩阵A,假设其秩为r,若存在秩同样为r两个矩阵:Fm×r(列满秩)和Gr×n(行满秩),使得A=FG,则称其为矩阵A的满秩分解。
性质:满秩分解不唯一:假设存在r阶可逆方阵D,则A=FG=F(DD−1)G=(FD)(D−1G)=F′G′;
◎任何非零矩阵一定存在满秩分解。证明如下;
◎假设存在初等变换矩阵Bm×m,使得

(4)奇异值分解(SVD)
奇异值分解(Singular Value Decomposition)是线性代数中一种重要的矩阵分解,是特征分解在任意矩阵上的推广[2]。
假设M是一个m×n阶矩阵,其中的元素全部属于域 K,也就是实数域或复数域。如此则存在一个分解使得其中U是m×m阶酉矩阵;Σ是半正定m×n阶对角矩阵;而V*,即V的共轭转置,是n×n阶酉矩阵。这样的分解就称作M的奇异值分解。Σ对角线上的元素Σi,其中Σi即为M的奇异值。常见的做法是为了奇异值由大而小排列。如此Σ便能由M唯一确定了。其应用主要包括求伪逆、平行奇异值、矩阵近似值。
-
二.矩阵分解推荐实现
为了获得目标 用户的兴趣,得到合适的推荐结果,一些学者采用基于领域的协同过滤推荐算法,得到相似的用户或项目,进一步得到推荐结果。但这些相似度算法大部分关注用户对项目的评分等级,以向量的形式比较距离,忽略了用户行为本身作为一个普通序列所具有的意义,而且用户对项目的倾向程度会根据时间的变化而变化,在用户对推荐结果需求数量比 较少时,还要尽可能把用户近期最为感兴趣的项目放在靠前的位置。矩阵分解是运用较为广泛的一种技术,可以随着用户信息的实时变化而改变推荐结果。
其主要原理是根据用户的使用习惯对物品、课程等项目进行分类,即将项目划分到不同的类别,而这些类别可以理解为用户的兴趣偏好。不同的用户,会有不同的兴趣偏好。例如用户A喜欢艺术类课程,用户B喜欢文学、历史类课程,用户C喜欢工商、经济类课程,但是基于这种想法,单纯对课程进行分类不能向学习者进行个性化的课程推荐。因此,我们需要了解学习者对课程的喜好程度,根据喜好程度值向学习者推荐相关课程[3]。
具体来说,假设用户物品的评分矩阵是m*n维,即一共有m个学习者,n门课程。通过一套算法转化为两个矩阵U和V,矩阵U的维度是m*k,矩阵V的维度是n*k,
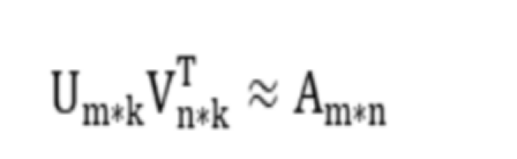
该方法基于这样一个假设,用户对某一课程的喜爱程度由k个因素(如课程时长、授课平台等)决定,Uni表示第n个学习者对第i个因素的偏好程度,而Vxi表示第X门课程满足第i个因素上的程度,Anx则表示学习者n对课程x的喜好程度,我们就可以根据喜好程度值向学习者推荐后续课程。
接下来我们将介绍基于奇异值分解(SVD算法)推荐课程的应用过程:
1.SVD基本算法
矩阵分解,就是把用户和物品都映射到一个K维空间上,这个k维空间不是直接看到的,通常称为隐因子。
假设每一门课程都得到一个向量q,每一个用户也得到一个向量p。对于课程,与它对应的向量q中的元素,有正有负,代表着这门课程背后暗藏的一些用户关注的因素,对于用户,与它对应的向量p中的元素,也有正有负,代表这个用户在若干因素上的偏好。课程被关注的因素和用户偏好的因素,它们的数量和意义是一致的,就是我们在矩阵分解之初人为指定的k。如何得到每一个用户,每一门课程的k维向量,这是一个机器学习的问题。按照机器学习思想,一般考虑两个要素:损失函数和优化算法。
SVD的损失函数是这样定义的:
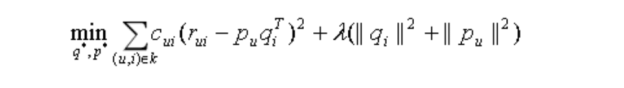
损失函数由两部分组成,前一部分是控制模型的偏差,后一部分控制模型的方差。前一部分:用分解后的矩阵预测分数,要和实际用户评分之间误差越小越好;后一部分:得到的隐因子向量要越简单越好,以控制这个模型的方差,换句话说,让它在真正执行推荐任务时发挥要稳定。
整个SVD的学习过程就是:
1)准备好用户课程的评分矩阵,每一条评分数据看做是一条训练样本
2)给分解后的U矩阵和V矩阵随机初始化元素值
3)用U和V计算预测后的分数
4)计算预测的分数和实际分数的误差
5)按照梯度下降的方向更行U和V 的元素值
得到分解后的矩阵之后,实质上就是得到每个用户和每门课程的隐因子向量,拿着这个向量再做推荐计算更加简单,简单来说就是拿着物品和课程两个向量,计算点积就是推荐分数。
2.考虑偏置信息:有一些用户会给出偏高的评分,有一些物品也会收到偏高的评分(比如一部观众为表演者铁粉的电影),所以原装的SVD就有一个变种:把偏置信息抽出来的SVD;一个用户给一门课程的评分会由四部分相加:
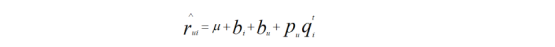
从左到右分别代表:全局平均分、物品的评分偏置、用户的评分偏置、用户和课程之前的兴趣偏好。
3.增加历史行为
有的用户评分比较少,事实上相比较沉默的大多数,主动点评电影或者美食的用户是少数,也就是说显示反馈比隐式反馈少。在SVD中结合用户的隐式反馈行为和属性,这套模型称为SVD++,在SVD++目标函数中,只需要把推荐分数预测部分稍做修改,原来的用户向量那部量分增加了隐式反馈向量和用户属性向:
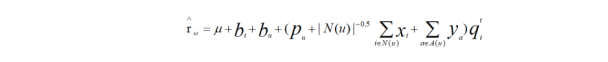
学习算法依然不变,只是要学习的参数多了两个向量:x和y。一个是隐式反馈的课程向量,另一个是用户属性的向量,这样在用户没有评分时,也可以用他的隐式反馈和属性做出一定的预测。
4.增加时间因素
在SVD中考虑时间因素,通常有几种做法:1)对评分按照时间加权,让久远的评分更趋近平均值 2)对评分时间划分区间,不同的时间区间内分别学习出隐因子向量,使用时按照区间使用对应的隐因子向量来计算 3)对特殊的期间,如节日、周末等训练对应的隐因子向量。
5.在线平台如何推荐课程
通过之前构建目标函数之后,就要用到优化算法找到能使它最小的参数。优化方法常用的选择有两个,一个是随机梯度下降(SGD),另一个是交替最小二乘(ALS),在实际应用中,交替最小二乘更常用一些,这也是推荐系统中选择的主要矩阵分解方法。
(1)最小二乘原理(ALS)
找到两个矩阵P和Q,让它们相乘后约等于原矩阵R:
P和Q两个都是未知的,如果知道其中一个的话,就可以按照代数标准解法求得,比如知道Q,那么P就可以这样算:
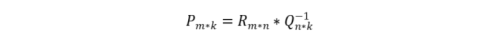
也就是R矩阵乘Q矩阵的逆矩阵就得到了结果,反之,知道了P再求Q也一样,交替最小二乘通过迭代的方式解决这个循环难题:
1)初始化随机矩阵Q里面的元素值;
2)把Q矩阵当做已知的,直接用线性代数的方法求得矩阵P;
3)得到了矩阵P后,把P当做已知的,故技重施,回去求解矩阵Q;
4)上面两个过程交替进行,一直到误差可以接受为止;
使用交替最小二乘好处:在交替的其中一步,也就是假设已知其中一个矩阵求解另一个时,要优化的参数是很容易并行的;在不是很稀疏的数据集合上,交替最小二乘通常比随机梯度下降要更快的得到结果。
(2)隐式反馈:实际上推荐系统关注的是预测行为,行为就是一再强调的隐式反馈。
如何从解决预测问题转向解决预测行为上来,这就是One-Class,简单的理解就是如果把预测用户行为看成一个二分类问题,猜用户会不会做某件事,但实际上收集到的数据只有明确的一类:用户干了某件事,而用户明确不干某件事的数据却没有明确表达,这就是One-Class由来,One-Class数据也是隐式反馈的通常特点。
对隐式反馈的矩阵分解,需要将交替的最小二乘做一些改进,改进后的算法称作加权交替最小二乘,加权交替最小二乘对待隐式反馈:1)如果用户对物品无隐式反馈则认为评分为0;2)如果用户对课程有至少一次隐式反馈则认为评分是1,次数作为该评分的置信度。
目标函数变为:
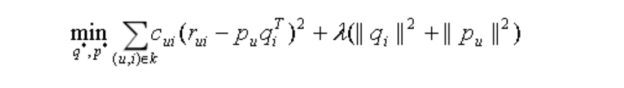
Cui就是置信度,计算误差时考虑反馈次数,次数越多,就越可信。置信度一般也不是等有反馈次数,根据一些经验,置信度Cui这样计算:
Cui=1+aC,a是超参数,需要训练,默认值为40,C是次数;针对那些没有反馈的缺失值,就是在我们给定的设定下,取值为0的评分就非常多,有两个原因需要在实际使用时要注意的问题:1.本身隐式反馈就只有正类别确定的,负类别是假设的 2.会导致正负类别样本非常不均衡,严重倾斜到0评分这边。
不能使用所有的缺失值作为负类别,矩阵分解的初心就是要填充这些值。面对这个问题的做法就是负样本采样:挑一部分缺失值作为负类别样本即可,怎么挑有两个方法:1.随机均匀采样和正类别一样多(可靠度不高) 2.按照物品的热门程度采样。
(3)推荐计算:让用户和课程的隐因子向量两两相乘实际上复杂度还是很高,尤其是对于用户数量和课程数量都巨大的应用,Facebook提出两个办法得到真正的推荐结果:
第一种,利用一些专门设计的数据结构存储所有课程的隐因子向量,从而实现通过一个用户向量可以返回最相似的K门课程;
第二种,拿着课程的隐因子向量先做聚类,海量的课程会减少为少量的聚类,然后在逐一计算用户和每个聚类的推荐分数,给用户推荐课程就变成了给用户推荐课程聚类,得到给用户推荐的聚类后,再从每个聚类中挑选几门课程作为推荐结果。
6.案例分析
向用户推荐课程的过程可以形象化为一个猜测用户对课程进行评分的任务,下面表格里面是5个用户对于5门课程的评分情况,就可以理解为用户对课程的喜欢程度。
课程1
课程2
课程3
课程4
课程5
小薛
5
3
4
4
?
用户A
3
1
2
3
3
用户B
4
3
4
3
5
用户C
3
3
1
5
4
用户D
1
5
5
2
1
首先根据前面的这些评分情况(即已有的用户向量)计算一下小薛和用户A、B、C、D的相似程度,找出与小薛最相似的n个用户。根据这n个用户对课程5的评分情况和与小薛的相似程度会猜测出小薛对课程5的评分,如果评分比较高的话,就把课程5推荐给用户小薛,否则不推荐。
在实现SVD之前,先来回忆一下ItemCF和UserCF对于这个问题的做法。首先ItemCF的做法,根据已有的用户评分计算课程之间的相似度,得到课程的相似度矩阵,根据这个相似度矩阵,选择出前K个与课程5最相似的课程,然后基于小薛对这K门课程的得分,猜测小薛对课程5的得分,有一个加权的计算公式。其次UserCF的做法是根据用户对其他课程的评分,计算用户之间的相似度,选择出与小薛最相近的K门课程,然后基于K个用户对课程5的打分计算出小薛对课程5的打分。这两种方式存在的问题是,如果矩阵非常稀疏就会导致预测效果不好,因为两个相似用户对同一物品打分的概率以及小薛同时对两个相似课程评分的概率可能都比较小。另外,这两种方法显然没有考虑到全局的课程或者用户,只是基于最相似的例子,也会导致结果偏差。
通过SVD算法推理,可得出小薛对课程5的得分为3.25,基于此得分,系统会将课程5推荐给用户小薛。
简单理解即,

C1、C2、C3、C4分别表示文史类、艺术类、金融类、编程类课程,用户矩阵是指用户A、B、C、D 对课程种类和课程内容的偏好评分,课程矩阵是指用户对C1、C2、C3、C4四门课程的种类和内容的评分。将用户矩阵与课程矩阵相乘即可得到用户*课程的共现矩阵,也就可以观察到不同用户对不同课程的偏好程度,学习系统会根据用户*课程矩阵向用户推荐相关课程,如系统会多次向用户C推荐艺术类课程,向用户D推荐金融类课程。
-
结语
矩阵分解本质上都是在预测用户对一个物品的偏好程度,这种针对单个用户对单个物品的偏好程度进行预测,得到结果后再排序的问题,在排序学习中称为point-wise。其中point意思就是:只单独考虑每个物品,每个物品像是空间中孤立的点一样,与之相对的,还有直接预测物品两两之间相对顺序的问题,就叫做point-wise,之前说的矩阵分解都属于point-wise模型。这类模型存在的问题是只能收集到正样本,没有负样本,于是认为缺失值就是负样本,再以预测误差为评判标准去无限逼近这些样本。逼近正样本没问题,但是同时逼近的负样本只是缺失值而已,还不知道真正呈现在用户面前,到底是不喜欢还是喜欢呢?虽然这些模型采取了一些措施来规避这个问题,比如负样本采样,但问题依然存在。
更直接的推荐模型应该是:能够较好地为用户排列出更好的物品相对顺序,而非更精确的评分。针对以上问题提出的方法是:贝叶斯个性化排序,简称BPR模型。
-
参考文献
[1]史加荣,李金红.新型深度矩阵分解及其在推荐系统中的应用[J].西安电子科技大学学报,2022,49(03):171-182.
[2]孙金岭,庞娟.基于奇异值分解方法的条件异方差下协整秩检验[J].统计与决策,2016(04):21-24.
[3]王娟,熊巍.基于矩阵分解的最近邻推荐系统及其应用[J].统计与决策,2019,35(06):17-20.
[4]陈辉,王锴钺.基于相似度计算的深度神经网络矩阵分解推荐算法[J].山东理工大学学报(自然科学版),2022,36(06):67-73.
[5]刘业政,吴锋,孙见山,杨露.基于群偏好与用户偏好协同演化的群推荐方法[J].系统工程理论与实践,2021,41(03):537-553.
[6]马莹雪,甘明鑫,肖克峻.融合标签和内容信息的矩阵分解推荐方法[J].数据分析与知识发现,2021,5(05):71-82.
-
-
- 标签:
-
加入的知识群:

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~