-
行为姿态识别综述
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
文章梳理行为识别的发展历程, 介绍了行为识别的概念及特征。对其他人所用到的技术进行归纳、总结、分析其优缺点,并展望行为姿态识别未来在课堂中的应用潜力。
1 行为识别的发展历程
2 行为识别算法分类总结
3 Yolov5核心基础内容介绍
4 算法及其实现
5 总结
-
1 行为识别的发展历程
在最近的这二十多年里,目标检测技术大致经历了两个时期:传统的目标检测时期(2012年以前)和基于深度学习的目标检测时期(2012年以后)传统的目标检测技术从1999年的SIFT7(Scale Invariant Feature Transform)算法开始,逐渐出现了很多优秀的算法。该阶段算法中具有代表性的有:HOG (Histogram of Oriented Gradient)、SURF (Speeded Up Robust Features)、DPM (Deformable Part Models)等算法。传统的目标检测技术采用人工特征进行检测,而人工特征的好坏直接影响检测算法的精度,因此这个时期的检测算法普遍存在复杂场景下鲁棒性差的缺陷。直到深度卷积神经网络(Deep Convolutional Neural NetworkDCNN)的出现才打破了这一局限。
基于深度学习的目标检测技术从2014年的R-CNN算法开始,到今天为止,这期间优秀的算法层出不穷,而且每个算法的准确率更高,检测速度也更快。这些算法不再使用人工特征,而是利用深度学习自动提取特征,不仅减少了人类的工作量,而且提高了分类和预测的精度。最具有代表性的算法:R-CNN、SPPNet、Fast R-CNN、Faster R-CNN、YOLO ( You OnlyLook Once)系列算法(YOLOv1、YOLO9000、YOLOv3、YOLOv4、YOLOv5)、 SSD、Mask R-CNN和 RefineDetP等。这些算法具有速度快、准确性强以及在复杂条件下鲁棒性强的优势。随着深度学习目标检测算法的不断改进和优化,研究人员通过研究不同深度的网络、卷积核大小和特征尺度,构造出各种不同的卷积神经网络并取得了优良成果。目标检测算法主流方向已经转变为以深度学习为基础的目标检测算法。
Simonyan等提出了基础的双流网络结构。如图所示,该网络设计了空间流和时间流两个并行的网络,使用两个独立的CNN网络来分开处理视频中空间和时间信息,空间流网络的输入为视频中采样的单帧图像,时间流网络的输入是光流信息,然后将两个网络识别的结果进行融合,最终得到识别的结果.该网络最终在UCF-101数据库、HMDB-51数据库上分别达到了88%、59.4%的准确率.由于它具有非常好的结构,并具有很好的拓展性,所以引起了科研人员的关注。围绕双流网络准确率和鲁棒性,后续涌现了许多改进的算法。

卷积神经网络一般采用2D卷积,在多帧图像上2D卷积的结果是一张特征图,只包含高和宽,而3D卷积的结果是立体的,除了高和宽之外还含有时间维度,因此3D卷积更适合用来处理视频序列的信息。如下展示了2D卷积和3D卷积的区别

循环神经网络在神经网络的输入层、隐藏层和输出层之间的神经元中建立了权值连接,网络模块的隐藏层每个时刻的输出都来自之前时刻的信息。RNN的循环网络模块不仅能够学习当前时刻的信息,也会保存之前的时间序列信息,但对于时间序列较长的信息,RNN容易出现梯度消失的问题,因此提出了LSTM网络来解决这个问题。LSTM网络用一个记忆单元替换原来RNN模型中的隐藏层节点,其关键在于存在细胞状态来存储历史信息,设计了三个门结构通过Sigmoid函数和逐点乘积操作来更新或删除细胞状态里的信息。如图所示为LSTM网络一个单元的内部结构,从左到右分别为遗忘门、输入门和输出门。LSTM网络通过累加的线性形式处理序列信息来避免梯度消失的问题,也能学习到长周期的信息,因此能够用来学习长时间序列的信息。

-
2 行为识别算法分类总结
1 按照特征复杂度分类
1.1 低级特征
也称为手动计算特征,既根据对被识别对象的特征知识理解进行特征提取,主要有:
1)图像特征,既基于RGB或灰度图像的特征提取,通常是基于灰度图像
2)光流特征,基于光流场进行特征计算
3)骨架特征,计算骨架的几何特征
1.2 中级特征
主要思想是对图像进行预处理,不直接计算特征,但也不是端对端算法,预处理后经过CNN进行行为识别。常用预处理方法有:
1)基于光流场
2)基于帧差分
两种预处理方案主要反映了行为的时序特征,再结合基于RGB的空间特征识别,形成双流法。
1.3 高级特征
已经证明骨架姿势不但是描述行为最准确的模式,而且不受场景和光照等影响,适用性强。骨架特征主要包括两种:
1)坐标特征,既骨架节点的坐标信息
2)几何特征,与骨架部位的角度,骨架节点距离等几何量相关的特征
2 按照基于骨架的行为识别算法分类
2.1 使用CNN网络
CNN网络的特点是要求输入是图像信息,而骨架基本特征信息通常由向量表示,因此需要设计适用于CNN的骨架图像信息,常用方法有:
1)计算骨架的光流信息形成图像
2)将一个序列骨架节点重构成图像
2.2 使用RNN或LSTM
从一段视频提取骨架的几何特征向量,构成基于时序的输入向量,而RNN和LSTM适用于时序输入。其中:
1)几何特征代表空间信息
2)时序输入堆代表时序信息
2.3 设计深度学习网络
设计专用深度学习网络可直接输入坐标特征和几何特征
3 按照骨架信息获取手段分类
1)基于RGB图像的深度学习模型提取骨架信息
2)基于3D图像
3)基于深度照相机
4 按照信息类型分类
4.1 空间信息
使用CNN提取空间信息,及空间信息之间的相关性,既:
1)节点坐标信息
2)骨架角度
3)骨架框架
4)前后帧骨架相关性
4.2 时序信息
使用RNN或LSTM提取时序信息
5 按照信息提取方式分类
5.1 手动提取特征
既根据对骨架特征的理解进行特征计算,通常这类特征作为RNN或LSTM的输入。
5.2 自动提取特征
通常认为手动提取特征的方法泛化能力差,因此借助深度学习的思想,用学习的方法自动提取特征,核心思想分两步:
1)将骨架数据进行有效的组合或拼接
2)利用深度学习网络模型的特点提取几何特征-
3. Yolov5核心基础内容介绍
Yolov5的结构和Yolov4很相似,但也有一些不同,按照从整体到细节的方式,对每个板块进行讲解。

Yolov5网络结构图 上图即Yolov5的网络结构图,由图可见,Yolov5还是分为输入端、Backbone、Neck、Prediction四个部分。
(1)输入端:Mosaic数据增强、自适应锚框计算
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
3.1 输入端
(1)Mosaic数据增强
Mosaic数据增强-YOLOv5中在训练模型阶段仍然使用了Mosaic数据增强方法,该算法是在CutMix数据增强方法的基础上改进而来的。CutMix仅仅利用了两张图片进行拼接,而Mosaic数据增强方法则采用了4张图片,并且按照随机缩放、随机裁剪和随机排布的方式进行拼接而成,具体的效果如下图所示。这种增强方法可以将几张图片组合成一张,这样不仅可以丰富数据集的同时极大的提升网络的训练速度,而且可以降低模型的内存需求。
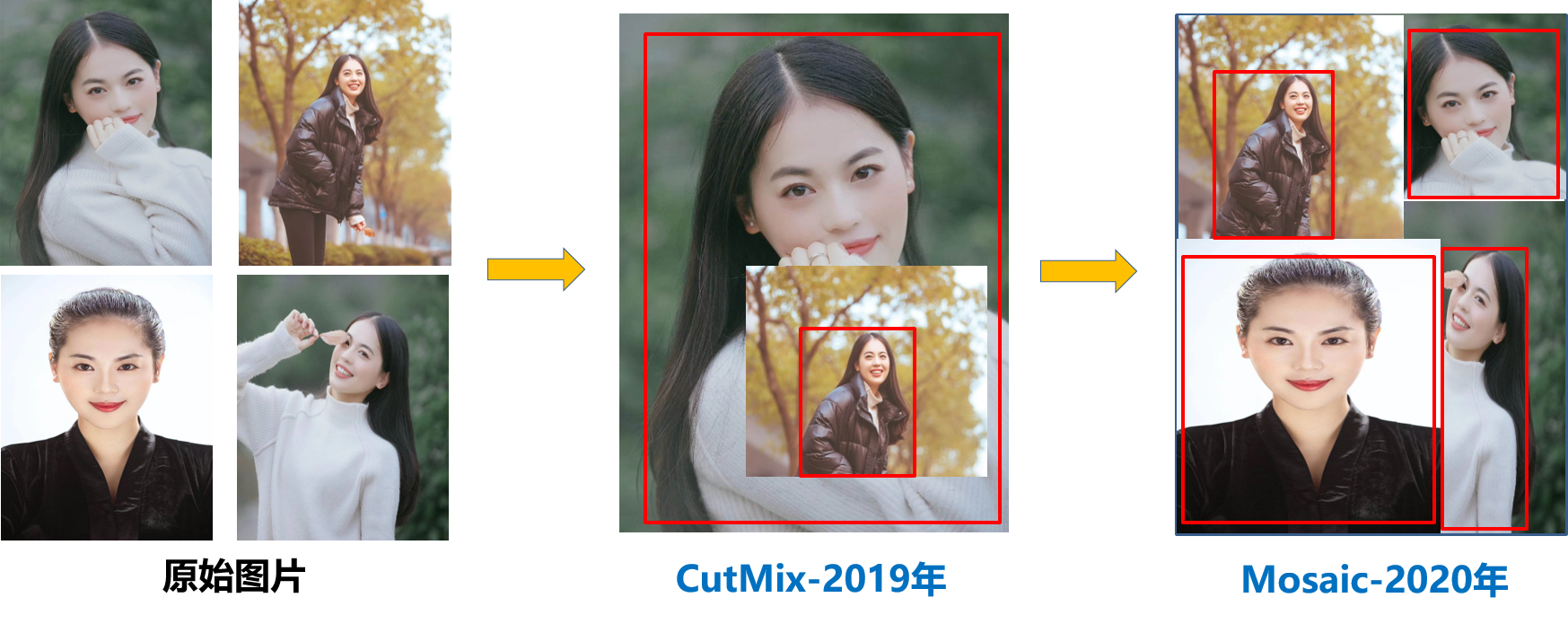
Mosaic数据增强效果 (2)自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

锚框设定 在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
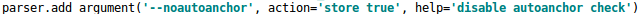
关闭功能实现代码 (3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。比如Yolo算法中常用416×416,608×608等尺寸,比如对下面800*600的图像进行变换。

自适应图片缩放 但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。作者认为,在项目实际使用时,很多图片的长宽比不同。因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此在Yolov5代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。

算法修改后的图片 3.2 Backbone
(1)Focus结构
Focus结构-该结构的主要思想是通过slice操作来对输入图片进行裁剪。如下图所示,原始输入图片大小为608*608*3,经过Slice与Concat操作之后输出一个304*304*12的特征映射;接着经过一个通道个数为32的Conv层(该通道个数仅仅针对的是YOLOv5s结构,其它结构会有相应的变化),输出一个304*304*32大小的特征映射。

Focus结构 (2)CSP结构
Yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。
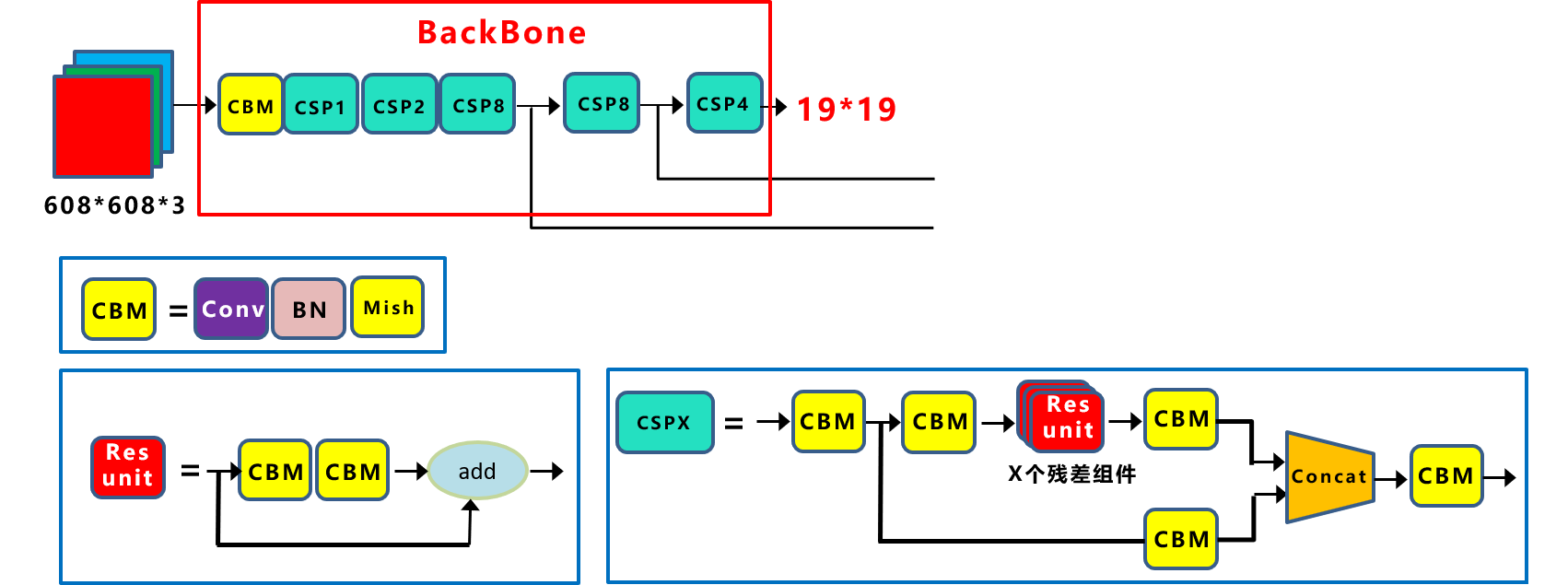
CSP结构 Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构,而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,以CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
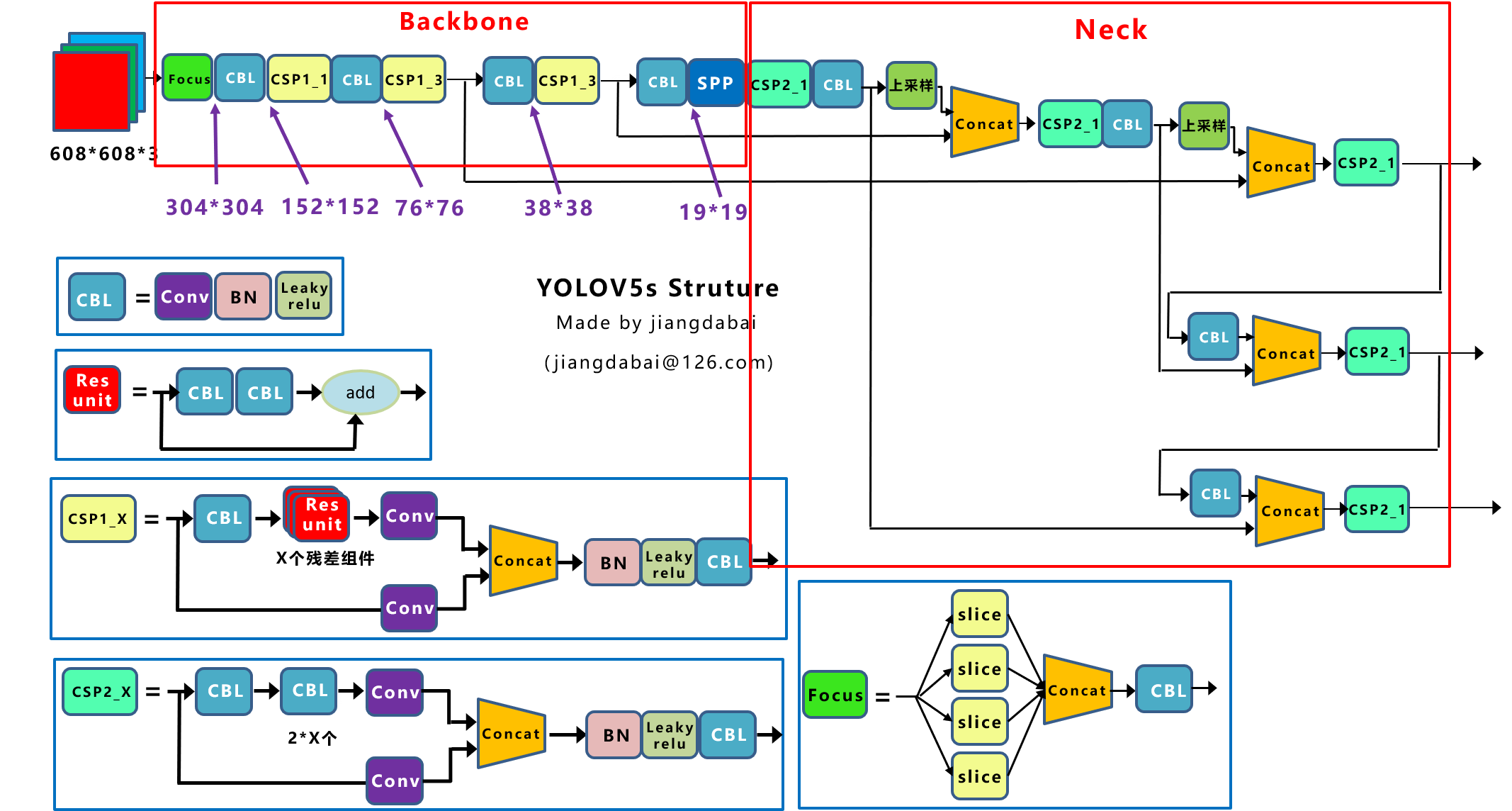
3.3 Neck
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。Yolov5和Yolov4的不同点在于,Yolov4的Neck中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPNet设计的CSP2结构,加强网络特征融合的能力。

Yolov5与Yolov4Neck结构对比 3.4 输出端
(1)Bounding box损失函数
Yolov5采用CIOU_Loss做Bounding box的损失函数。目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
CIOU_Loss在DIOU_Loss的基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。

其中v是衡量长宽比一致性的参数,也可以定义为:

(2)nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中仍然采用加权nms的方式。
-
参考文献
[1]张锦,屈佩琪,孙程,罗蒙.基于改进YOLOv5的安全帽佩戴检测算法[J].计算机应用,2022,42(04):1292-1300.
[2]Zhu Xia. Design of Barcode Recognition System Based on YOLOV5[J]. Journal of Physics: Conference Series, 2021, 1995(1)
[3] Yan Bin et al. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5[J]. Remote Sensing, 2021, 13(9) : 1619-1619.
[4]Qi Dang,Jianqin Yin,Bin Wang,Wenqing Zheng.Deep Learning Based 2D Human Pose Estimation:A Survey[J].Tsinghua Science and Technology,2019,24(06):663-676.
[5]闫兴亚,匡娅茜,白光睿,李月.基于深度学习的学生课堂行为识别方法[J/OL].计算机工程:1-8[2022-12-19].DOI:10.19678/j.issn.1000-3428.0065369.
[6]苏江毅. 基于人体骨架的行为识别算法研究[D].江南大学,2021.DOI:10.27169/d.cnki.gwqgu.2021.000493.
[7]马琳琳,马建新,韩佳芳,李雅迪.基于YOLOv5s目标检测算法的研究[J].电脑知识与技术,2021,17(23):100-103.DOI:10.14004/j.cnki.ckt.2021.2402.
[8]廖煊龙. 面向智能视频监控的目标检测和行为识别技术研究[D].电子科技大学,2019.
-
- 标签:
-
加入的知识群:

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~