-
The impact of chatbot on language learning: A meta-analysis
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
阅读笔记一:Learning from text, video, or subtitles
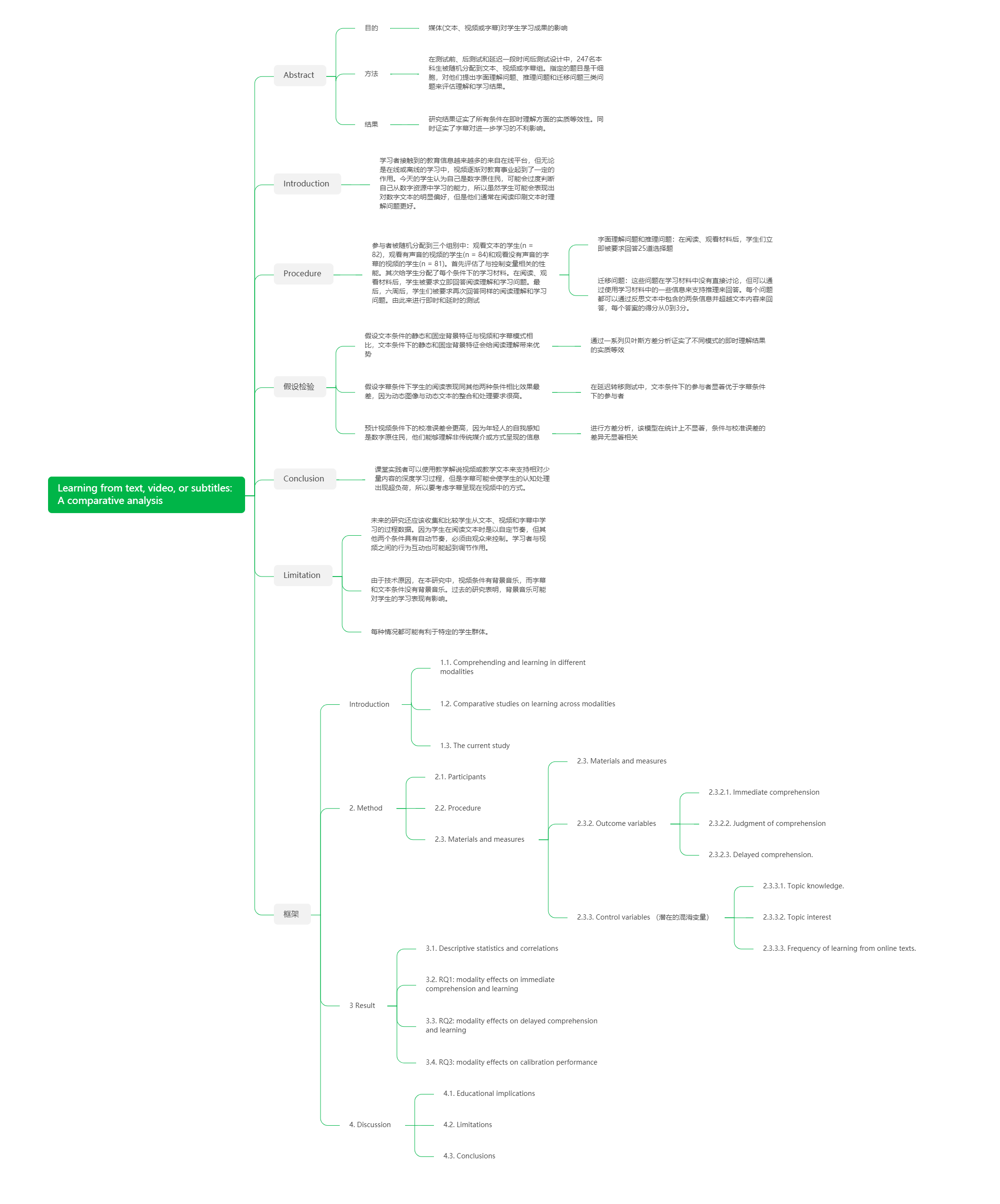
-
Conclusion
该作者的研究有助于我们了解多媒体的学习,数字媒体对于当前学生的课堂内外均具有重要意义,使人们对学习新材料的多种选择是否等同产生了疑问。而对于三种模式的选择上,首先要考虑学习内容的具体目的,如果目的是保持进一步的学习概念性的知识文本形式会更优先于其他的模式,但是如今的学生更喜欢以视频的形式来进行学习,这种模式与即时学习任务也是正相关。再将视频同字幕这两种模式来进行对比,网络上的教学视频大多数都有字幕是因为这些材料最初是用英语制作的,所以需要配上其他语言的文字才能供不同国家的学生使用,但是学生在观看此类有字幕的视频时,处理两种类型很可能会让他们的视觉通道超负荷。所以课堂教学人员可以使用教学解说视频或教学课件来支持相对较少内容的深度学习的过程,而带有字幕的视频会使学生的认知处理负担加重。
-
研究方向:语音情感识别技术对教学的影响的文献综述
1.Introduction
1.1 研究背景和动机
介绍为什么要在教学领域上研究学生和教师的情感变化
1.2 提出研究问题和目标
2.Methods
2.1 描述文献搜索的数据库和关键词:语音情感识别 教学(包括教师、学生、课堂)
2.2 解释文献筛选标准
2.3 数据抽取和分析方法
3.Contents
3.1 介绍语音情感识别技术的基本原理和方法并阐述语音情感识别技术在教学中的潜在应用价值
3.2 分别归纳出语音情感识别在学生情感状态监测中的应用和教师情感表达和反馈中的应用情况
4.Discussion
分析文献研究之间的差异和一致性,最终得出语音情感识别技术对教学产生的影响如何。
5.Conclusion
5.1 总结文献综述的主要发现和重要观点
5.2 对未来研究方向和发展趋势的展望
-
阅读笔记二
文献阅读笔记
文献简介
发表时间
2016
题目
A Real-Time Speech Emotion Recognition System and its Application in Online Learning
期刊名称
Emotions and Technology
作者
Ling Cen, Fei Wu, Zhu Liang Yu, Fengye Hu
原文链接
关键词
Speech; Acoustic features; Affective computing; Emotion; Classification; Online learning
研究目的
本论文的研究目的是开发出一个实时语音情感识别系统,并将其应用于在线学习中。通过识别学生的情感状态,可以帮助教师更好地了解学生对所教授内容的反应,并根据不同的学生学习能力来定制在线课程,以实现最佳的学习效果。
研究内容
本文主要介绍了一种实时语音情感识别系统以及它在在线学习中的应用。该系统能够接受实时记录的预先记录的语音数据和连续语音,并检测语音中表达的情绪状态。通过识别学生的情感状态,该系统可以帮助教师更好地理解学生对教学内容的反应,并根据学生的情感反应对课程内容和教学方式进行调整,以提高在线学习的效果和趣味性。本文还介绍了该系统的技术细节和实验结果,并探讨了在在线学习环境中应用情感识别系统的挑战和可能性。
研究设计
一、模型的构建
该模型根据语音信号的声学特征来识别语音信号中涉及的情感状态进行分类的过程。
从训练语音数据中提取特征集→将特征集和情感类别的目标值输入到支持向量机(SVM)中构建训练模型
(将被检测的语音数据提取相同的特征后输入进模型中,从而得出目标情绪的预测标签)
1、系统流程图(提取特征)
进行语音活动(VAD)以检测是否存在人类语音→如果检测到信号较长,则将其分成几个片段→对分割的信号进行预处理(预加重、分帧和窗口处理)→从处理的信号中提取特征
1.1 VAD算法
运用VAD算法来检测突然出现的语音,以及检测语音与非语音的区别。在本系统中,每隔10毫秒从信号中提取长度为25毫秒的信号帧,将第i帧的信号作为实验样本来进行计算标准偏差,将所有帧中标准偏差的最大值同根据环境情况和背景噪声设置的两个阈值进行计算,通过这种方法可以检测到是否有语音。
(一帧信号通常取在15ms-30ms,帧长为25ms的一帧信号指的是时长有25毫秒的语音信号)
1.2 语音分割
根据语音信号的短时能量和频谱中心点以及预定义的阈值,检测出需要去除的连续语音片段和中间的静音
(①计算每个帧的短时能量:对于第i个帧,将该帧内的样本进行平方运算,然后将平方结果求和。这个求和结果即为该帧的短时能量。
②计算频谱的重心:将总的频率加权和除以总的幅度加权和,得到频谱的重心。第i帧DFT的系数指的是对第i帧语音信号应用DFT变换后得到的频域系数。DFT变换将时域信号分解为一系列频率分量,每个频率分量对应一个频域系数。)
1.3信号预处理
使用(FIR)滤波器对语音信号进行预加重处理,为了突出信号中的重要频率成分。
1.4声学特征
语音信号经过预处理后会被提取出声学特征,用于情感识别。该系统使用三种短期特征(PLP Cepstral Coefficients, MFCC, and LPCC),融合其总特征可得到一个维度为
 的向量,M为每帧提取的特征总数。
的向量,M为每帧提取的特征总数。2、支持向量机(SVM)的学习模型
情绪频率统计分析
在实时录制的连续语音序列中,每个片段都有一个情感类别。录音结束后,根据分类结果对情绪频率进行统计分析,用被归类为该情绪类别的语段数量,除以表示有效预测情绪状态的语音语段总数。
二、实验
在系统构建结束后,通过进行两组实验来证明系统的有效性
第一步:离线实验→使用提前录制的数据
第二步:实时记录和识别→在办公环境中以16kHz的采样频率从一名男性说话者那儿进行录制。
三、模拟学习环境下应用实时系统
记录一名男大学生在互联网上观看一门关于艺术的在线课堂的实时语音。录音时间为10.3分钟,学生以三种状态之一来进行回答,在录音整个过程中消极状态占33.13%,积极状态43.64%。结果表明,该学生的学习过程是愉快的,因为积极情绪的片段多于消极情绪的片段。检测到的消极情绪主要与愤怒和悲伤有关,因为课程有部分内容难以理解和不清楚,这与学生对学生完成情况的反馈一致。
研究意义
该文章的研究意义在于开发了一种实时语音情感识别系统,并将其应用于在线学习中。这项技术可以通过识别语音中的情感状态来了解学生对课程内容的反应,从而为每个学生提供个性化的课程,以达到最佳的学习效果。此外,该系统还可以用于安全、医疗、娱乐等领域的情感识别应用,具有广泛的实用价值。
启示
该文章从离线语音和实时语音识别两个方面来进行实验研究,将收集到的语音通过处理,提取特征后输入到SVM中,作者使用了一对多和一对一两种常见的多类分类方法。最后,通过输出SVM分类器的结果,可以得到输入语音信号的情感类别。
-
读书笔记三
文献阅读笔记
文献简介
发表时间
2022
题目
Research on Feature Fusion Speech Emotion Recognition Technology for Smart Teaching
期刊名称
Hindawi
作者
Shaoyun Zhang1 and Chao Li
原文链接
研究目的
为了充分挖掘情感教学的特点从而实现课堂教学情绪分类的任务,我们提出了一种多特征融合和深度学习的教学语音情绪识别方法。利用训练好的神经网络对更多公开课视频进行分析和比较从而总结出当前优秀课程的情感模式
研究内容
语音情感识别系统包括两个阶段(1)特征提取,从可用的语音数据中提取适当的可用语音特征。(2)分类器,用于判断语音的潜在情感。目前的分类器以单独或组合的形式应用于语音情感识别。针对其选择的问题,提出一种多特征融合方法,用于前端处理语音频谱特征,并与其人工神经网络分类器相结合,形成最终的语音情感识别模型。
研究设计
一、预处理情感语音信号
语音信号的预处理包括预加重、短时分析、分帧、加窗和端点检测。
①预处理:通过傅立叶变换对语音信号频谱进行预加重。预加重的主要内容是高频部分,可以确保信号频谱更加平滑,从而使信号分析或信道参数分析更加容易。
傅立叶变换:用于将一个函数(或信号)从时域(时间域)转换为频域(频率域),即将复杂的信号考虑成由不同简单的信号组成。
②短时分析:即对语音的分析和处理以短时间为基础。
③分帧:对语音进行短时分析时,需要把其中的信号进行按帧处理,对信号进行分割和处理。一帧通常为10-30毫秒,为了实现平滑过渡并保持连续性,相邻帧通常会重叠。根据帧长和步长,可以得到一个语音段的所有语音帧。
④加窗:在对语音信号分之后,当我们使用傅立叶展开时,会出现一个问题:将具有不连续点的周期函数(如矩形脉冲)进行傅立叶级数展开后,选取有限项进行合成。当所选择项数更多时,其合成波形中产生的峰起则会更加接近到原信号中不串联的点。在选择的项数非常大时,其中所产生的峰起值更加仅仅为常数,其大概与跳变值的总额的百分之九等同。该现象被称作吉布斯效应。
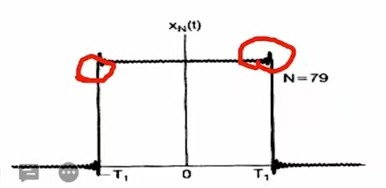
这个时候我们就需要进行加窗处理。常用窗函数是矩形窗和汉明窗。要对语音信号进行加窗,也就是一次仅处外理窗中的数掘。因为实际的语音信号是很长的,我们不能也不必对非常长的数据进行一次性处理。明智的解决办法就是每次取一段数据,进行分析,然后再取下一段数据,再进行分析。仅取一段数据的一种方式就是构造一个函数,这个函数在某一区间有非零值,而在其余区间为0,汉明窗就是这样的一种函数。它主要部分的形状像sin(x)在0到Π区间的形状,而其余部分都是0。这样的函数乘上其他任何一个函数f,f只有一部分有非零值。之后对窗中数据进行FFT,假设一个窗内的信号是代表一个周期的信号,(也就是说窗的左端右端应该大致能连在一起)而通常一小段音频数据没有明显的周期性,加上汉明窗后,数据形状就有点周期的感觉了。直接对信号加矩形窗截断会产生频率泄露。
⑤端点检测:在语音片段中找到语音的起点和终点,将有效语音信息和无效的杂音信号分离开来。
二、三种特征提取方法
1、声音频谱图特征
语音信号是一维信号,直观上只能看到语音的时域信息,而看不到其频域信息。为了可以观测到频域信息,我们需要对语音信息进行STFT(短时傅里叶变化)。
2、FBank特征与人类耳朵的响应特征密切相关,但它仍然有一些缺点,例如 FBank 特征的每个滤波器组之间的叠加部分。
3、MFCC特征通过在提取的 FBank 特征的基础上执行DCT(离散傅里叶变换)可以获得特征
三、随着神经网络的流行,本文作者提出了基于多特征融合和RNN(递归神经网络)相结合的HNN(混合神经网络)的教学语音情感识别分类器。
HNN 分类器的结构

第一部分是卷积特征提取器,它将音频文件的频谱图图像表示作为输入。 特征提取器使用 DenseNet对输入图像进行卷积得到了一个扩展特征图
第二部分是循环神经网络 (RNN) 。RNN 可以处理不同长度的输入,因此不需要音频输入剪辑或填充。RNN 选择 LSTM 结构来解决序列数据中存在的长期依赖关系。
第三部分由两个全连接层和一个 softmax 层组成
在本文中,并行子网络训练的网络结构用于融合特征。特征融合的优点是可以获得最有效的特征和最小维度特征向量集,有利于最终决策。特征融合过程是使用针对三种特征的并行、独立网络进行训练的。每个独立网络都由一个 HNN 组成,对三个不同的特征进行深度处理。之后连接一个全连接层其作用是使用串联连接来收敛独立网络的输出。
四、实验过程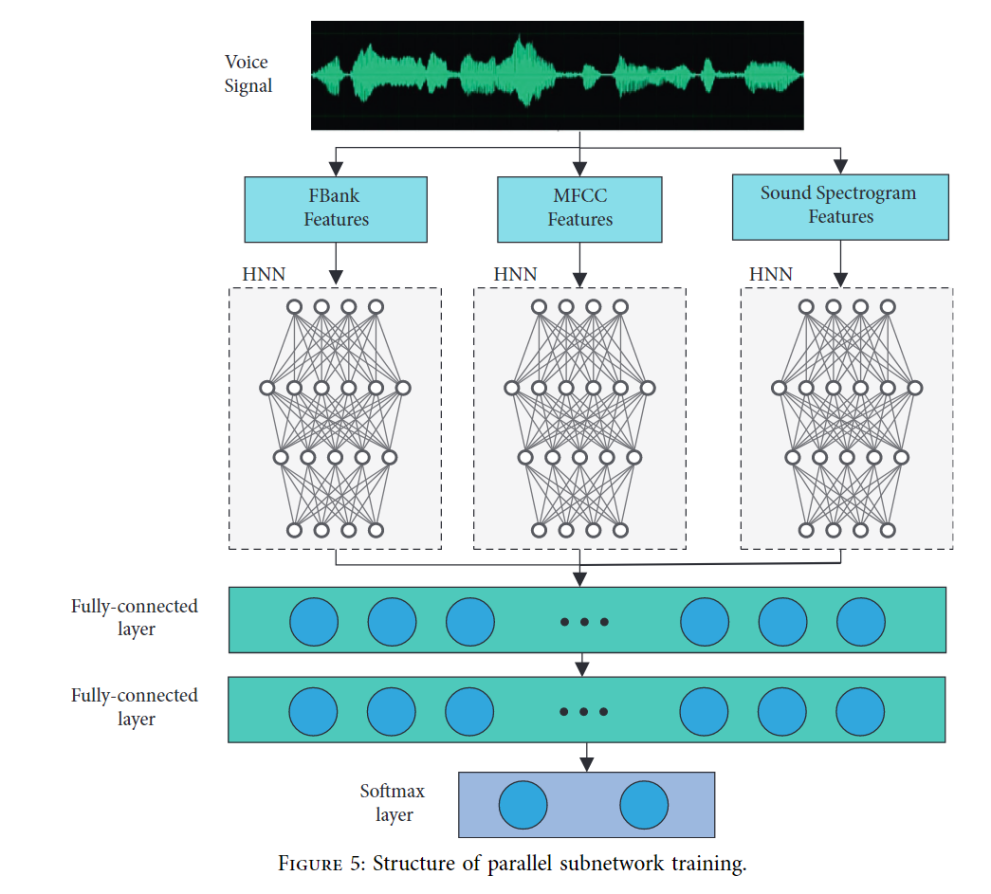
文章使用语言基于BeautifulSoup4爬虫技术从中国大学MOOC平台获取了100门课程的视频数据对数据进行预处理。音频分割使用了 pydub 库中的 split on silence 函数。音频分割会根据静音时间确定说话人的说话间隔,从而根据说话内容将一堂课的音频分割成大量的片段。抓取的100 个课程在音频切割后被分为 30000 多个音频片段并进行了人工标注。标记教学情感数据集存在严重的数据不平衡对占总数据 71% 以上的“平静“标签进行了欠采样处理。下采样操作会丢弃大量数据,我们随机丢弃了约 90% 的数据量,最终留下了 1085 个“平静“标签样本。同样,对于较小的数据集,如“紧张"、"犹豫“和“满意“标签,我们也进行了过采样“操作。过采样是指重复使用一定比例的数据以确保数据量不会太少而导致过拟合问题。虽然经过过采样和欠采样后,数据的比例可能会发生变化,但数据的平衡性会得到更好的改善。
研究意义
本文的研究意义在于研究了一种智能教学情感识别技术,解决了情感数据集分布不均的问题,并通过欠采样和过采样等数据预处理方法,提高了数据集的平衡性和泛化能力,从而避免了过拟合的问题。这项技术可以应用智能教学领域,对提高教学效果和用户体验有一定的促进作用。
启示
语音情感识别研究过程中,有效特征的选取以及使用单一特征的模型往往不能达到很好的分类效果。本文融合了FBank特征、MFCC特征和声音频谱图特征,用于HNN网络训练,从而建立了多特征声音模型。融合过程采用独立的并行式子网络训练,然后通过全连接层进行共同训练。所使用的 HNN 分类器是 CNN 和RNN 的混合分类器。实验结果表明,随着融合特征的增加,模型的识别效果得到了优化。通过训练教学语音情感识别模型,可以实现智能教学过程中情感的快速识别和分类。
-
新选题——聊天机器人对语言学习的影响研究
The impact of chatbot on language learning: A meta-analysis
搜索关键词:AI chat robot; chatbot; language learning
1.Introduction
1.1 研究背景和动机
介绍聊天机器人在语言学习中的应用背景和重要性。说明聊天机器人作为一种交互式学习工具,能够提供个性化学习支持和实时反馈,对语言学习的潜在影响。
1.2 提出研究问题和目标
即评估聊天机器人对语言学习的效果,并探讨其中的影响因素。
2.Methods
2.1 描述文献搜索的数据库和关键词:AI-chatbot,chatterbot;language learning, English learning, foreign language learning, second language learning, language education, language acquisition and language teaching.
2.2 解释文献筛选标准
2.3 对文献进行编码,使用了什么分析方法和工具
3.Contents
3.1 发表偏倚的检验
3.2 综合和解释元分析结果,讨论聊天机器人对语言学习的整体效果的作用
3.3 讨论聊天机器人对语言学习不同影响因素的作用
4.Conclusion
4.1 总结研究的主要发现和结论,强调聊天机器人在语言学习中的潜在价值
4.2 指出聊天机器人对于教育实践和未来研究的启示。
-
读书笔记四:
文献阅读笔记
文献简介
发表时间
2021
题目
Applying Ai Chatbot For Teaching A Foreign
Language: An Empirical Research
期刊名称
International Journal of Scientific & Technology Research
作者
Tran Tin Nghi, Tran Huu Phuc, Nguyen Tat Thang
原文链接
关键词
AI chatbot, intelligent conversational tools, students’performance, ELT, Facebook app, CALL, mobile application
研究目的
本研究探讨应用AI Chatbot来教授外语的可性和效果。通过结合Facebook auto messenger和对话式活动,作者希望让学习者在任何时间任何地点都能自动互动学习英语语法。研究旨在验证Chatbot在英语语言教学中的用效果,并探讨学生自主学习和良好情绪对法知识理解的影响。同时,研究还旨在与之前应用信息技术(ITC)进行语言教学和学的研究相一致,并探讨学生在实验中使用Chatbot学习时的表现提升情况。最终目是提高学生的学习效果和兴趣,改善语言教学过程。
本调查旨在根据兴趣发展的四阶段模型调查学生在日常生活中使用移动应用程序的兴趣。(triggered situational interest, maintained situational interest, emerging individual interest, and well-developed individual)
研究内容
本文主要研究了在教授外语时应用AI聊天机器人的效果。作者通过实验发现,使用AI聊天机器人辅助教学可以提学生的学习成绩,同时还能够提高学生的学兴趣和参与度。作者为探究应用AI Chatbot在教授外语方面的效果,在越南胡志市食品工业大学的本科生中,招募了100名生进行实验研究,其中一组进行了15个学时的英语介词教学,另一组则进行了10个学时的英语词教学,并使用Facebook chatbot作为辅助教学工具。研究采用了性方法和定量研究设计,以比较和评估使用chatbot教授外语的效果。
研究设计
一、实验对象
通过招募来自胡志明市食品工业大学本科生的自愿参与者进行设置的。初始参与者数量每组100名学生。所有学生由同一位老师进行教学,并且研究人员之一也是教师。根据TOEIC分数的排名,学生被随机选择并分为两个水平相当的组。
第一组是对照组,在没有Facebook chatbot帮助的情况下,进行为期15个课时的英语介词教学课程。
第二组是实验组,进行为期10个课时的课堂教学,并且在这期间使用了Facebook chatbot的帮助。
二、实验材料
研究中使用的材料是一本英语代词和介词书第二部分中的 10 个单元,该书由 Ed Swick 编写。作者选择介词进行研究是因为在学习的过程中介词的用法容易被学生忽视。
聊天机器人由 Chatfuel 开发,该聊天机器人于 2015 年建立,目标是在 Facebook Messenger 上构建机器人进行营销。聊天机器人在https://www.facebook.com/englishprepositionuasages/上链接到Facebook页面。
三、实验过程
①对照组:所有学生都必须参加 3 次课程,每个课程周期为 5 节。教师讲授unit 13-22 共 10 个unit。在学习后为学生提供试卷来进行测试。学习内容同实验组相同。
②实验组:步骤 1:向所有学生介绍聊天机器人,让他们进行placement test(类似等级考试)。步骤2:要求学生写出他们在考试中答错的介词种类,以及加入课本中哪个单元的建议。步骤3:实验组的学生可以根据英语介词用法聊天机器人的建议,选择加入课程书中的指定主题班级。步骤4:同对照组学生一起接受了测试和调查。
③实验设计
定量研究设计分为纵向、横向和面板设计结构以及实验和准实验两种类型
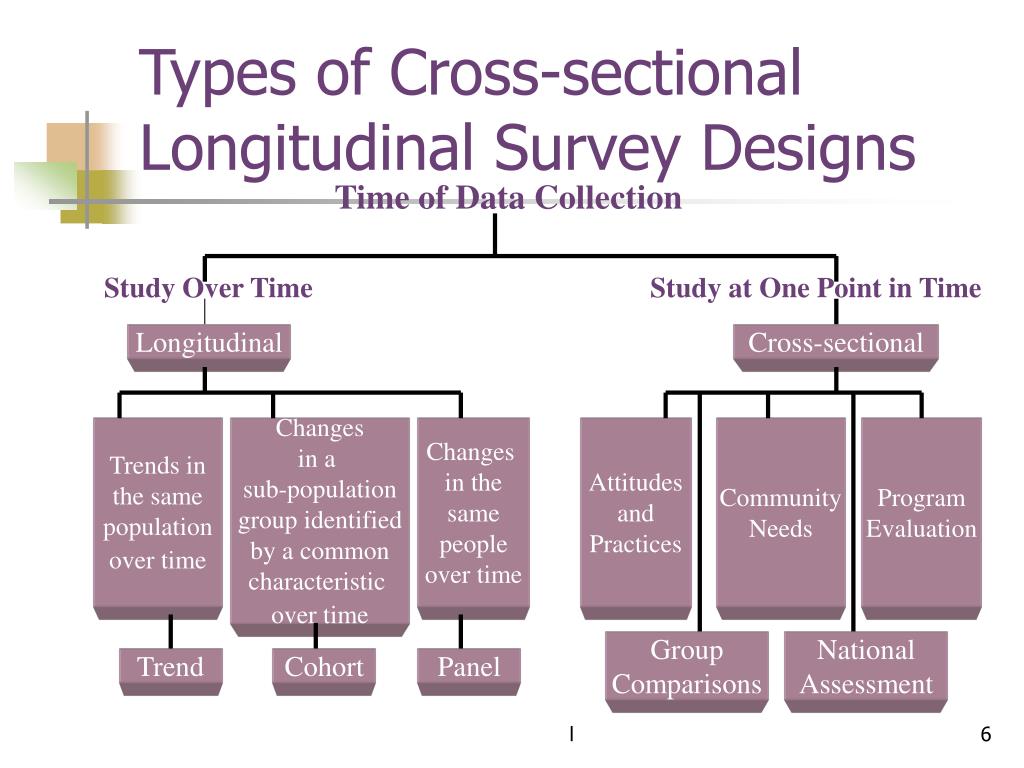
Panel design structure:其中研究参与者(被试)被分配到不同的组别,并且每个组别在研究期间都接受不同的处理或条件。在面板设计中,被试在不同的时间点上被测试或评估,以便比较他们在处理或条件之间的变化。其通常用于长期研究或追踪研究,其中研究者希望观察随时间变化的效果。在不同时间点上对同一组被试进行测量,研究者可以比较被试在不同时间点上的表现,并确定处理或条件对其产生的影响。
研究人员采用了描述性方法来描述所有因素,包括语言和非语言因素、被调查变量之间的相关性以及对参与者的访谈。例如:受访者只能从 "我有意使用手机应用程序来提高我的语言技能 "这一概念变量的选项中选择一个,并且不能同时选择多个选项。
④实验分析
在本研究中,这些统计量主要是通过 T-test( T 检验)和ANOVA(方差分析)计算得出的。(T-test适用于比较两个组的均值,而ANOVA适用于比较三个或更多组的均值。T-test和ANOVA都用于检验组间差异的显著性)作者在实验前首先调查了学生使用移动设备在闲暇时间的分布和频率,并得出学生在闲暇时学习的学生占少数,并且适应移动设备学习的时间也同其他活动时间相比较短。故作者想让学生使用聊天机器人来进行英语学习。
作者先采用ANOVA方差分析证明实验组和对照组存在差异,对照组和实验组(应用聊天机器人的小组)学生在教材各单元的成绩存在差异。在 "分词介词"、"后置介词 "和 "表示位置的介词 "这三个单元的题目中,实验组的成绩要好于对照组,按照 10 分的评分标准,实验组和对照组的平均分差距在 0.45 到 0.50 之间。在 "表示运动或方向的介词"(均值相差 1.21)、"表示时间的介词"(均值相差 1.05)、"介词和短语动词"(均值相差 0.89)和 "介词的多种用法"(均值相差 0.90)单元中,对照组和实验组也存在明显差异。从这些数据来看,实验中的聊天机器人非常有用,它可以帮助我们预测在实际教学中哪些单元可以忽略,哪些单元应该认真教授(比如在均值相差较大的介词类型的组别中)
作者使用假定方差相等和假定方差不相等的方法是为了进行独立样本的均值比较,并确定两个组之间的差异是否显著(显著差异意味着两个组的均值之间的差异不太可能是由于随机抽样误差造成的,而是由于真实的差异导致的,即。)这些发现有助于得出结论,聊天机器人可以用于评估学术进度、预测未来性能和发现潜在问题。
根据研究结果,作者还提出了一个假设:人与人之间的对话比人与聊天机器人之间的对话更容易迷失方向。
由于在two units Compound Prepositions and Prepositions that combine with other words 中均值近乎相同,作者则提高了显著性水平到10%,在这种情况下测试出来:
在实验组和对照组,两组之间进行了两个单元测试的比较,分别是"Unit Test 4 - Compound Prepositions"(复合介词)和"Unit Test 5 - Prepositions that combine with other words"(与其他单词组合的介词)。
在第一个单元测试中,两组之间的平均差异的最低排名为1.80,最高平均差异为0.70。这意味着在这个单元测试中,两组之间的平均差异的范围是从0.70到1.80。
在第二个单元测试中,两组之间的平均差异的最低排名为0.61,最高平均差异为0.78。这意味着在这个单元测试中,两组之间的平均差异的范围是从0.61到0.78。
则说明是否使用聊天机器人对于学生学习成绩来说还是有影响。
当作者进一步考察使用移动应用程序的频率分布与学生成绩之间的相关性时,结果表明,除了玩网络游戏之外,提高语言技能和听音乐、观看 YouTube 最喜欢的频道、浏览 Facebook 和其他社交网络都提高了学生掌握英语介词的成绩。
研究意义
作者让学习者将 Facebook auto messenger同会话活动相结合,从而学习新的英语语法知识,这让他们实现了随时随地自由互动。本研究与以往在语言教学中应用 ITC 的研究是一致的。随后,学生们必须设法完成 ITC 应用程序分配给他们的任务,很快他们就喜欢上了这种新的学习方式,尤其是在实验中使用聊天机器人。学生们在结合课程和聊天机器人学习外语的过程中,学习成绩有了很大提高。
启示
阅读完该文章得出聊天机器人对于学生语言的学习有很大的作用,作者通过验证学生使用其他移动应用程序也同学生的学习成绩有相关性后得出学生将学习同娱乐结合会进一步促进其学习。
-
读书笔记五:
文献阅读笔记
文献简介
发表时间
2023
题目
Effect of chatbot-assisted language learning: A meta-analysis
期刊名称
作者
Shunan Zhang, Cheng Shan, John Sie Yuen Lee, ShaoPeng Che & Jang Hyun Kim
原文链接
研究目的
这篇论文的研究目的是通过进行元分析,综合分析聊天机器人辅助语言学习的效果。研究旨在探讨聊天机器人对学生学习成果的整体影响,并进一步分析聊天机器人在不同语言学习领域、不同界面和开发方式下的效果差异。通过研究聊天机器人的使用,目的是为了提供有关聊天机器人辅助语言学习的证据,以指导未来的教学实践和技术设计。
研究内容
由于以前的报告显示的是聊天机器人对语言学习的混合结果,因此本研究通过使用元分析,整合了先前关于 CALL 实验研究的结果,共检查了来自 18 项研究的 61 个样本。识别和讨论了九个潜在的调节变量(教育水平、目标语言、语言领域、学习结果、指令持续时间、聊天机器人界面、聊天机器人开发、任务优势和交互方式)来探索其有效性。
研究设计
一、研究方法
1、介绍聊天机器人的演变过程以及在教育领域的语言教学的哪些方面起到了作用。
2、介绍聊天机器人的好处,①以聊天机器人的是在线的、免费的而展开的优势②以是同机器进行交流的优势
3、介绍先前研究是如何进行分析的,从而得出聊天机器人对语言学习是有效果的,但未能从每个方面进行分析。进一步推出使用元分析的好处。作者也举了其他国家的元分析论文并提出其只调查了韩国的情况。
4、作者提出本文要研究的三个问题:(1) CALL 的整体效果是什么。(2) 基于 CALL 的实验研究中的关键调节变量是什么。(3)这些因素在多大程度上调节语言学习结果?
5、文献搜索:作者阐述了在Web of Science, Scopus, and Wiley这三个网站进行以两组关键词展开搜索:Two sets of keywords were used: (1) "chatbot," "chatterbot," and "conversational agent"; and (2) language learning-related keywords, including "language learning," "English learning," "foreign language learning," "second language learning," "language education," "language acquisition," and "language teaching."搜索于 2022 年 10 月 7 日以前已发表文章。文章必须用英语书写,由于该领域比较新,作者的筛选还包括会议记录,以获得实现聊天机器人的最新细节。在收集整理完当前资料后实施The snowballing strategy来获得更全面的资料。
6、资料筛选:在剔除重复研究,以及摘要和标题与该主题无关的研究后按照以下的标准继续进行审核,最后得到了18篇符合标准的文章。
(1)研究应比较 CALL 和非 CALL 条件,揭示 CALL 的影响。
(2)研究应提供估计聊天机器人对语言习得影响的效应大小所需的描述性统计。
(3)研究应评估语言习得的结果。
(4)通过随机对照试验或预测试,研究应保证分配到 CALL 和非 CALL 条件下的群体之间的同质性。这一特点可以证明学生过去语言技能的平等性。
7、计算效应大小:当实验有多个评估结果和实验条件时,我们分别计算了相应的效应大小。故当前的荟萃分析从 18 个 CALL 实验研究中提取了 61 个结果。效应大小由两个编码员提取。第一个编码器提取效应大小和相关统计数据,并由另一个编码器进行验证。有两种计算效应大小的方法,分别是Cohen's d和Hedges' g ,他们两个能产生同样的结果但是Hedges’g更适合小样本,故本实验使用Hedge'g来计算效应大小。
8、编码方案:为了探索影响 CALL 有效性的调节变量,作者部分采用了先前研究中提到的调节变量,并根据 18 个包含样本之间的可比特征添加了新的调节变量。两名研究人员独立致力于编码,并讨论了歧义,直到达到共识:实验设计和聊天机器人本身的九个特征被确定为本研究的潜在调节变量。
9、数据分析:本研究采用了综合荟萃分析软件(CMA,版本 3),为了评估 CALL 的总体效果,作者首先将计算出的效应大小相加,计算出总体估计值。随后使用调节变量分析法研究了所选调节因素如何影响 CALL 的效率。最后绘制了漏斗图来分析发表偏倚。
二、研究结果
1、CALL的总体效果:因本研究是横跨不同方向,则随机挑选一个效应模型来计算其大小,最终结果整体效应大小为0.527,则是一个中等大小。因此,一般来说,使用聊天机器人进行语言学习会产生积极的影响,并且学习结果优于非 CALL 情况下的学习结果。
2、从九个调节变量的不同视角进行分析
Educational level:CALL 受益于所有教育水平的学生。然而,K12 教育的学生比大学生从 CALL中受益更多。
Target language:CALL 对目标语言的影响存在显着差异。此外,聊天机器人用于学习外语时的效果大于学习母语时。
Language domain:在语言领域,CALL 的效果差异显著。其中,当聊天机器人用于词汇学习时,效果最大,其次是听力、口语、其他和语法。值得注意的是,在阅读和写作中使用 CALL 时,其效果大小变得微不足道。
Learning outcome:CALL 始终与积极的语言学习结果相关联。在这方面,CALL 对行为学习结果的影响最大,然后是认知学习结果和情感学习结果。学习结果的差异是显着的。
Instruction duration:当实验持续时间为一至三个月和三个月以上时,CALL 的效果适中。当实验持续时间少于一个月时,CALL 的效应较弱。然而,这三个值之间在统计学上没有发现明显的差异(p>0.05)。
Chatbot interface:至于聊天机器人界面,网络条件下的 CALL比应用程序条件下的 CALL具有更大的效应规模,尽管两者之间没有统计学差异(p > 0.05)。
Chatbot development:不同聊天机器人开发的 CALL 效果相似,都有中等程度的影响。此外,与使用现有聊天机器人(相比,作者开发的具有特定功能的聊天机器人对 CALL 的影响更大。
Task dominance:关于谁主导聊天,没有统计学意义(p > 0.05)。有趣的是,用户驱动的互动产生的效果明显高于聊天机器人驱动的互动。
Interaction way:交互作用法的评估结果表明,尽管两种交互作用方式都证明了 CALL 具有积极作用,但学生从语音到文本中获益的程度要高于纯文本。然而,这两个值之间没有统计学意义上的显著差异(p > 0.05)。
三、结果讨论
总体而言,聊天机器人辅助语言学习对学生的学习成果有积极的调节作用。这一结果与以下观点一致,即能与人类进行语言互动的技术可以通过提供有价值的学习机会来提高语言学习效果。这可能归因于聊天机器人的几个特点:(1)聊天机器人为人们提供了随时随地学习语言的机会 (2) 与技术的互动增加了人们交流的意愿。
- 首先,对于教育水平,K12 教育的学生似乎比大学生从 CALL 中受益更多。结果与以前的研究一致,表明年轻学习者同年纪大的学习者相比在使用科学技术来学习更投入。由于作者的研究仅包含两个教育水平的学生,未来的研究可以将参与者扩展到例如老年人探索 CALL 的作用。
- 其次,CALL主要用于学习第二语言,这与Huang等人的研究一致。有趣的是,尽管 CALL 在学习 L1 和 L2 方面具有巨大的潜力,但它在学习 L1 方面明显更好。作者怀疑这一结论有两个原因。首先,L2 采集比 L1 更复杂且更具挑战性。此外,Jeon 到学生在使用聊天机器人之前拥有一定程度的语言知识时具有更好的语言学习性能。鉴于 CALL 的教育潜力,未来的研究应该尽可能地改进其对 L2 的使用。
- 在词汇、听力、说话等方面发现了显着的好处。词汇比语言的其他方面更容易单独和独立地呈现。因此,CALL 最有价值的教学启示在词汇学习中得到了证明。用于口头学习的聊天机器人减少了学生的外语焦虑并增加他们交流意愿,因此,CALL 在口语学习中的价值不能被忽略。然而,关于听力,需要更多的样本来证明结果的可靠性。
- 第四,与指令持续时间相关的结果表明,当持续时间在 1-3 个月之间时,CALL 是最有效的,其次是三个月以上。当研究持续不到一个月时,影响最小。作者的研究证实了语言学习的长期性质以及使用技术的新颖性。语言学习是随时间变化的累积过程,因此,少于一个月的实验的效果不显著。然而,与Fryer等人(2017)和Fryer等人(2020)的研究类似,如果持续时间超过3个月,学生可能会受到新颖性效应的影响,并失去对聊天机器人的兴趣。因此,应该做更多的努力来解决新颖性效应并提高学生的连续使用意图。
- 第五,关于聊天机器人界面和聊天机器人开发,基于Web的 CALL 的效果高于基于移动应用程序的 CALL。此外,还揭示了使用自创聊天机器人而不是现有聊天机器人的有效性。这两个发现可以归因于以下原因。基于 Web 的聊天机器人主要由研究人员根据实验的目的和需求开发。因此学习结果更有效。此外,通过添加其他功能,例如动态评估和实时反馈,自行创建的基于 Web 的聊天机器人具有更多的技术可供性。此外,与预先存在的聊天机器人应用程序相比,定制聊天机器人以匹配特定的语言目标、兴趣和需求提供了更大的灵活性和个性化的学习体验。从自适应学习的角度来看,作者的发现与 Hallahan 等人一致,表明个性化指令、连续评估、动态内容、实时反馈是促进人们成果学习的关键因素。
- 当学习过程是用户驱动的时,CALL 具有更好的学习结果。用户更喜欢 协作中的人进行交互。作者怀疑关于使用聊天机器人进行学习也有类似的偏好。此外,与Hallahan等人一致,学习者主导的过程会产生积极的学习结果。在语言学习中,用户可能会觉得聊天机器人驱动的学习是刚性和不太吸引人的。预选的主题和内容可能与用户的兴趣和目标不一致,这可能会阻碍学习体验。因此,未来的聊天机器人可以通过其他因素来设计,以增加用户的优势。
- 学生使用从语音到文本聊天机器人比单独使用基于文本的聊天机器人中受益更多。这与Abdul-Kader等人(2015)的研究结果一致。这种现象可以解释如下原因:首先,语音到文本功能模仿现实生活中的对话,它允许用户以更自然的、动态、引人入胜和沉浸式的方式练习他们的语言技能。其次,参与对话练习的语言学习者比只练习阅读和写作的语言学习者保留了更多的语法规则。语音到文本系统的技术可供性还提供了更大的教学可供性。未来的聊天机器人可以在设计上不断优化,以提供更现实的对话体验。
四、未来的研究仍有局限性需要解决。
首先,在划分调节变量时,一些样本量较小。例如,只有一个样本用于听力学习,较小的样本量不足以证明 CALL 的有效性。因此,未来的研究应该包括额外的实验条件并扩展样本量以测试 CALL 的有效性。
此外,在本研究中,我们的目标是从实验和准实验中提取数据。然而,在文献筛选过程中,作者发现几篇文章仅通过问卷检查了 CALL 的有效性。因此,在未来的研究中,可以结合使用调查作为方法的研究来研究不同研究方法对 CALL 有效性的影响。
此外,目前的研究通过九个调节变量探索了 CALL 的有效性,但是每个中介效应的细节不应被忽视。
关于聊天机器人的开发,作者发现具有特定功能的自创聊天机器人更有效。但是,要确定哪些功能最有益,还需要进一步研究。
研究意义
这篇论文的研究意义在于探讨聊天机器人辅助语言学习的效果。通过进行元分析,研究者对201项研究进行了综合分析,得出了聊天机器人对语言习得的影响。研究发现,聊天机器人对语言学习有积极的影响,特别是在词汇学习方面效果最显著。此外,研究还发现不同的学习结果和调节变量对聊天机器人的效果也产生了影响。这些研究结果对于推动语言学习领域的技术应用和教学实践具有重要的指导意义。
启示
该文章元分析的整体过程非常的细致具体,对于我自身来写一篇元分析有了进一步的认识。
对于该文章的调节变量从两个方面来展开,对我来说也有一定的启发,并且其在文章中提到在实验本身的这几个变量中的教育等级变量可以覆盖的年龄更多,这让我在筛选文献的时候可以进一步的放在年纪较大的人群对聊天机器人的反应上。
-
读书笔记六:
文献阅读笔记
文献简介
发表时间
2021
题目
Chatbot-assisted dynamic assessment (CA-DA) for L2 vocabulary learning and diagnosis
期刊名称
Computer Assisted LAnguAge LeArning
作者
Jaeho Jeon
原文链接
关键词
Chatbots; dynamic assessment; vocabulary learning; glosssing; cognitive load theory; Dialogflow; artificial intelligence
研究目的
本文的研究目的是探讨Chatbot-Assisted Dynamic Assessment(CA-DA)对L2词汇学习的影响,并提供关于学习者能力的诊断信息。研究旨在通过利用chatbot技术来实现动态评估,以促进词汇习得并在学习过程中提供诊断信息。
研究内容
本文的研究内容是探索使用聊天机器人(chatbots)来辅助第二语言(L2)词汇学习和诊断的动态评估方法。研究重点在于探讨聊天机器人如何提供交互式词汇学习机会,以及如何通过聊天机器人记录学习者的表现来进行动态评估。
研究设计
一、实验对象
本文的实验对象是81名韩国小学英语学习者,年龄在12岁左右,其中58名学习者的词汇量在1200-1500个单词之间。实验分为三个组:控制组、文本提示组和聊天机器人提示组。其中,控制组只进行了阅读活动,没有任何提示;文本提示组在阅读活动中使用了文本提示;聊天机器人提示组在阅读活动中使用了聊天机器人提示。
二、实验材料
研究人员从一本专为年轻的 EFL 学习者设计的书--《The Popcorn Book》从中挑选了两个部分,并将其修订为两个实验环节的阅读材料。为了使每个目标词的出现频率保持一致,研究者对原文进行了改编,并修改了被认为超出学习者水平的复杂结构。最终修改后的材料分别包含 209 个和 221 个单词,其中包括 10 个目标单词,这 10 个目标单词在每篇文章中至少出现一次。
本研究中的聊天机器人由谷歌开源聊天机器人生成器 Dialogflow 生成,并上传到平板电脑上。学习者以书面的形式同聊天机器人进行英语和韩语的交流。
三、实验过程
首先,研究使用了三个测试(前测、后测和延迟后测),分别在两个连续的实验会话之前和之后进行,以揭示聊天机器人辅助动态评估(CA-DA)对词汇习得的影响。每个组都使用相同的格式进行了三次测试。首先,在实验课之前的两周进行了前测,确定了学习者不熟悉的单词,并将这些单词选为实验的目标单词。然后,在两个实验会话期间,参与者被要求阅读文本,并确定下划线的目标单词的含义。CA-DA组接受了逐渐递进的聊天机器人辅助,而CA-NDA组只从聊天机器人那里得到目标单词的定义。对照组没有使用聊天机器人。三个组在每个处理会话中分配了相同的时间,即25分钟。最后,为了检查词汇习得情况,立即在第二个实验会话结束后进行了后测,并在两周后进行了延迟后测以检查词汇保持情况。对每个组的测试结果进行了统计分析。此外,对CA-DA会话中学习者与聊天机器人的交互进行了逐字转录,并进行了定量和定性分析,以揭示词汇学习和学习者能力诊断的潜在影响。
③实验设计
本文的实验过程主要分为以下几个步骤:
1、初始提示的创建:研究者根据之前的文献使用了一个逐渐明确的初始提示集合。这个初始提示集合是基于之前使用动态评估(DA)来学习词汇的文献和一个五步骤的设计过程来帮助学习者识别未知词汇的含义。
2、预实验研究:初始提示集合在预实验中被随机选择的五名学习者中进行了测试。预实验通过平板电脑上的聊天应用程序进行,以尽可能提供与实验会话相似的环境。在预实验中,研究者扮演了聊天机器人的角色,并要求学习者在初始版本提示的指导下进行阅读活动。整个过程被记录下来,并用作构建聊天机器人的数据。
3、聊天机器人的构建:根据学习者对每个提示的反应,研究者创建了最终版本的提示,这些提示最终被输入到聊天机器人中。通过一项一元方差分析(ANOVA)对参与者的得分进行统计分析,结果显示三组之间存在统计学差异。此外,通过Scheffe的事后比较,还发现两个使用聊天机器人辅助的组比控制组表现更好。此外,与控制组相比,CA-DA组在书面形式下更有效地获得了词汇知识。
4、学习者能力的诊断:通过对第一次和第二次会话的实际得分和中介得分的增加,可以看出CA-DA组的学习者在独立和中介表现方面都有所提高。通过定性分析学习者与聊天机器人的中介交互,可以获得有关学习者在过程中词汇分的比较,可以发现学习者在词汇学习能力方面具有不同的起点,因此应为每个学习者准备不同类型的后续学习和教学。
四、实验结果
1、CA-DA对词汇知识的影响:根据实验结果显示,CA-DA组在即时性的词汇积累(即后测)上得分高于其他两组,而CA-NDA组的得分也高于对照组。同样,在延迟后测中,CA-DA组的得分也高于其他两组,而CA-NDA组的得分也高于对照组。通过对参与者得分进行一元方差分析,结果显示三组之间存在统计学差异,F(2,50) =21.640, p < .05, η^2 =0.46。此外,Scheffe的事后比较还表明,两个受Chatbot辅助的组在词汇知识方面优于对照组(p < .05)。另外,在延迟后测中也得到了相同的结果。也就是说,三组之间存在统计学差异,F(2,50) =16.277, p < .05, η^2 =0.39。具体而言,可以观察到两个受Chatbot辅助的组在书面形式的词汇知识方面比对照组更有效地学习(p < .05),并且CA-DA组表现优于CA-NDA组(p < .05)。
2、基于CA-DA的学习者能力诊断:除此之外,学习者3和学习者4在第一次会话中的实际得分为0,这表明他们无法在没有Chatbot提示的情况下提供目标词的正确定义。然而,在Chatbot的帮助下,学习者3在第二次会话中仅用了16次提示就成功完成了任务,这可以通过学习者的中介得分来确认。学习者4也能够在Chatbot的帮助下给出这些单词的定义,总共用了30次提示。根据他们的中介得分,可以认为他们在词汇学习能力方面具有不同的起点,因此应该为每个学习者准备不同类型的后续学习和教学。学习者每个单词的表现信息可以进一步支持后续学习的进行。例如,当教师意识到学习者4在识别某个单词的定义方面比学习者3更困难时,教师可以为学习者4提供更具体与该单词相关的例子,并为学习者3准备包含该单词的更复杂和具有挑战性的句子。
研究意义
该研究的意义在于引入了Chatbot-Assisted Dynamic Assessment(CA-DA)的概念,将聊天机器人作为中介来辅助学习者进行词汇学习。通过CA-DA,学习者可以在阅读文本时与聊天机器人进行开放式对话,获得对于陌生单词的自动化中介,而不受多选题格式的限制。这项研究发现,通过聊天机器人进行DA能够促进词汇习得,并在学习过程中提供关于学习者能力的诊断信息。与以往的DA文献不同的是,本研究利用了聊天机器人技术来创建诊断信息。研究结果表明,CA-DA组可以提供关于学习者能力的诊断信息,这些信息在CA-NDA组中是不可用的。教师可以利用这些信息为后续学习做出教学决策。此外,通过引入CA-DA的概念,这项研究为DA研究社区提供了一条新的研究途径,并在更广泛的技术增强语言评估领域中提供了新的教学理解。总的来说,这项研究证明了聊天机器人可以作为学习工具来促进第二语言习得,特别是在词汇学习方面。通过在课堂环境中应用DA,这项研究证实了CA-DA能够提升词汇习得,并在学习过程中提供有关学习者能力的诊断信息。聊天机器人具有人类化的特点,使学习者能够与其进行互动,从而创造了有效的词汇学习条件。此外,聊天机器人可以在多个学习者之间实现一对一的互动,如果教育环境适当,可以适用于更多的学习者。通过在不同设备上使用聊天机器人,学习者可以随时随地与其互动。这项研究为将评估与学习相结合的潜力提供了证据,并为今后在语言学习的其他领域中探索使用聊天机器人的可能性提供了指导。
启示
该文章为本周在谷歌学术、web of science检索到的文献之一,其表明了聊天机器人可以在L2语言学习中的单词学习方面对学生学习成绩产生积极影响。符合筛选的标准。
-
读书笔记七:
文献阅读笔记
文献简介
发表时间
2022
题目
Investigation of the influence of artificial intelligence markup language-based LINE ChatBot in contextual English learning
期刊名称
Frontiers in Psychology
作者
Chien, Yu-Cheng;Wu, Ting-Ting;Lai, Chia-Hung;Huang, Yueh-Min
原文链接
关键词
LINE ChatBot, artificial intelligence markup language (AIML), competitive strategy, English learning, contextual learning
研究目的
本研究的目的是探讨基于人工智能标记语言(AIML)的LINE ChatBot在英语学习中的影响,特别是在英语会话练习中,包括说话和听力。
研究内容
探讨基于人工智能标记语言(AIML)的LINE ChatBot在上下文英语学习中的影响。具体来说,研究对象为两个班的高中生,分为实验组和对照组。实验组使用LINE ChatBot进行具有竞争元素的英语对话练习,而对照组仅使用LINE ChatBot进行非竞争性的英语对话练习。研究目标是评估这两种学习方式对学生英语口语和听力能力的影响以及竞争性元素对学习动机的影响。通过调查学生在使用LINE ChatBot时的学习效果和动机,研究者旨在探讨这种学习方法的优势以及其在教育环境中的应用潜力。
研究设计
一、实验对象
实验对象包括台湾南部一所高中两个班级的73名二年级学生。由于班级设置因素的限制,本研究的研究对象无法随机分配,因此将一个班级的 37 名学生随机分为实验组(男生 17 人,女生 20 人),而另一个班级的 36 名学生则为对照组(男生 19 人,女生 17 人)。
二、实验材料
在课堂上,教师对两组学生采用了相同的教学内容和指导学习活动,并选择了 Studio Classroom 作为本课程的教材。
在本研究中的LINE聊天机器人,用于结合英语会话的学习活动,它基于人工智能标记语言(AIML),为练习会话创造了一个情境英语学习环境。同时,结合语音文本识别(STR)技术来识别学生的对话。最初,所有参与者都被要求加入一个 LINE 群组,并与 LINE 聊天机器人进行互动,以提高他们的听说能力。后续学生可在LINE群组中与同学匿名互动。
三、实验过程
①实验前测
首先,为确保学习者初始能力和行为的同质性,对学生的听说能力和学习动机进行了前测。听力测试使用的是工作室课堂学习材料,口语能力教师使用多维流利量表进行评分。此外,根据 Pintrich(1991)提出的学习动机策略问卷(MSLQ)对学生的学习动机进行了问卷调查。完成前测后,教师向两组学生解释了本研究将开展的学习活动,以及如何使用 LINE ChatBot 情境学习环境。

②实验设计
在本研究中,实验组和对照组的学生都使用 LINE 聊天机器人进行为期 4 周的课后学习活动来进行英语会话的听说练习。对照组的学生加入了LINE聊天机器人,进行没有竞争的会话练习,而实验组的学生则参加了包含竞争的LINE聊天机器人会话练习。
他们利用课堂上所学的知识,从教材中自主选择合适的句子作为对话主题,在 LINE 群组中朗读自己的句子,并聆听同伴朗读的句子作为对话练习。值得注意的是,学生们在互动过程中保持匿名,即不透露 LINE 小组中同学的身份。在完成每周的学习活动后,所有学生都进行了会话练习,其中包括实验组的一次口语活动和 36 次听力练习,对照组的 35 次听力练习。然后,任课教师会对学生的口语表现要素(如发音、吐字和语调)给予反馈。实验组的学生会获得与实验竞赛阶段相关的额外分数。
在完成4周的课后学习活动后,学生们被要求完成后测问题,以测量他们的英语听说能力,从而确定使用LINE聊天机器人的学习效果。同时,为了研究竞争对学习动机的影响,还通过 MSLQ 进行了后测。
研究结果显示,一:实验组和对照组的口语和听力后测成绩均高于前测成绩。二:当学生参与情境学习时,有竞争或无竞争的学习都会影响他们的内在学习动机。
研究意义
1、使用LINE ChatBot为基础的AIML(Artificial Intelligence Markup Language)创建了一个创新的英语学习环境,让学习者能够在自主、匿名的情况下进行英语会话练习,从而提高他们的英语口语和听力能力。
2、研究探讨了竞争对于学习动机和成果的影响,发现竞争可以提高学习者的内在学习动机,从而提高他们的学习成果。
3、本研究使用了移动助学技术(MALL),利用智能手机和平板设备实现了实时教育互动,为学习者提供了一种新颖、有效的英语学习方法。
4、研究发现,匿名学习环境可以有效减轻学习者在英语交流中的尴尬感和紧张感,从而提高他们的英语学习效果。
本研究为探索利用线上聊天机器人提高英语学习效果提供了有益的见解,为提高非英语母语国家学生的英语学习能力提供了一种创新的方法。
启示
该文章为在谷歌学术上检索到的文章,实验自变量不符合筛选的标准,其为有竞争和无竞争在有聊天机器人应用于语言教学的背景下。
-
本周进度:
以chatbot、AI chatbot、language learning、English language learning 、L2 learning 为关键词将Google Scholar 中的文献完成了筛选共124篇,在对题目和摘要进行阅读后符合要求的有58篇,进一步进行筛选。因本实验研究聊天机器人对语言学习的影响,故实证研究的自变量应是是否将聊天机器人运用在语言学习中且研究应该提供聊天机器人对语言习得影响的效应大小的描述性统计,经过最后筛选仅有6篇文章符合标准。
-
读书笔记八:
文献阅读笔记
文献简介
发表时间
2022
题目
Investigating college EFL learners’ perceptions toward the use of Google Assistant for foreign language learning
期刊名称
Interactive Learning Environments
作者
Howard Hao-Jan Chen , Christine Ting-Yu Yang & Kyle Kuo-Wei Lai
关键词
Intelligent personal assistants; Google Assistant; human-machine interaction; learners’ perceptions; second language speech
研究目的
本文的研究目的是探讨大学生对使用Google Assistant(谷歌助手)进行外语学习的看法,以及他们的语言水平对这些看法的影响。
研究内容
本文主要研究了大学英语作为外语(EFL)学习者对使用谷歌助手(Google Assistant)进行外语学习的看法。研究者通过观察和访谈等方法,探讨了不同语言水平的学习者对谷歌助手的使用感受,以及是否存在沟通中断(Communication Breakdown)等问题。此外,研究还探讨了学习者在与谷歌助手交流过程中所采取的策略。包括以下的三个方面:
1、调查EFL学习者对谷歌助手在语言学习中的使用的看法。
2、探讨语言水平影响学习者对谷歌助手的看法。
3、了解学习者在与谷歌助手交流过程中采取的策略。
研究设计
一、研究对象
从台湾北部的一所大学招募了 29 名 EFL 学习者(6 名男性和 23 名女性),并在报名前告知他们在完成实验后可获得约 16 美元的奖励。参与者的年龄在 18-22 岁之间(平均年龄为 20.24 岁),母语为普通话。由于研究目的之一是调查语言水平对学习者使用 IPA 的影响,所有参与者都需要提供他们在 TOEIC、TOEFL iBT、IELTs 或 GEPT 中口语部分的分数,并根据分数将他们分为低(L)、中(I)和高(HI)组。
二、研究工具
1、Intelligent Personal Assistant(IPA):Google Assistant on Google Home Hub
作者决定使用 Google Home Hub 作为媒介来观察参与者如何与它交互,以及此功能如何影响参与者对使用 IPA 进行英语学习的看法。
2、Questionnaire and survey:A 5-point Likert-scaled questionnaire and a survey
①其中包含八个项目,以收集有关参与者对英语的一般看法及其英语学习体验的信息
②对参与者进行了一项调查,以了解他们对在英语学习中使用 GA 的看法,以及对学习者-IPA 互动的相互可理解性的看法。
3、Interview
在完成调查后,每个参与者都单独给予半结构化口头访谈。访谈包括以下三个问题:1)你与 GA 互动的整体感觉是什么。2) 你最喜欢的应用是什么。为什么。3) 在英语学习中使用 GA 的优缺点是什么。任何进一步改进的建议?
4、Logs of conversations between participants and IPA
为了更好地确定学习者与 IPA 交互过程中出现交流中断(CBs)的场合和原因,作者下载了每位参与者与 GA 之间的对话记录以作进一步分析
三、实验过程
在上机操作之前,研究人员首先告知参与者整个实验,其中一名研究人员简要介绍了如何通过一些基本命令与谷歌互动,并向参与者解释了整个过程。
实验由两个环节组成:60 分钟与谷歌互动的实践环节和 30 分钟的调查环节。实践环节包括 6 个 10 分钟的任务,让参与者体验 GA 提供的各种活动。第一个任务要求参与者向 GA 提出各种问题,以获取信息。在第二和第三项任务中,参与者命令 GA 播放音乐/新闻和讲故事/笑话。在第四和第五个任务中,参与者玩了四个互动游戏,并与谷歌 Home Hub 上的五个聊天机器人进行了自由对话。最后一项任务要求参与者使用由台湾团队开发的两款英语学习应用程序。
实践环节结束后,向参与者发放了问卷调查,参与者有大约 20 分钟的时间完成问卷调查。调查之后是访谈,时间约为 10 分钟。整个实验耗时约 1.5 小时。
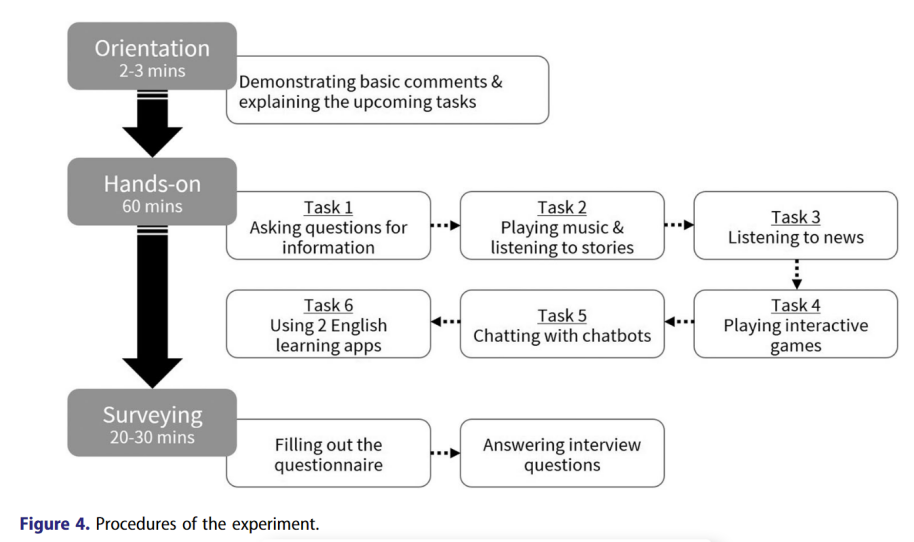
研究结果显示:
1、不同语言水平的学习者对使用IPA(如谷歌助手)在语言学习中的作用持有正面看法。他们认为IPA有助于提高他们的发音、词汇量、阅读能力、听力和口语能力。
2、学习者在与IPA(如谷歌助手)交流时的语言水平对他们的感知和被理解程度有一定影响。对于具有较高语言水平的学习者,他们认为IPA对他们的英语理解程度较高,而对于较低水平的学习者,他们认为IPA在理解他们的英语方面表现不足。
3、在与IPA(如谷歌助手)交流时,较低水平的学习者可能会遇到更多的沟通障碍。这主要是由于发音错误的原因,这导致IPA在理解学习者的英语方面表现不足。
4、不同水平的学习者在修复沟通障碍时采用的策略有所不同。较低水平的学习者更多地采用重复策略,而较高水平的学习者则更多地采用重新表述策略。
5、该研究提出两个建议:
①针对语言教育工作者,建议他们鼓励学习者使用IPA,因为这些工具在语言学习方面有一定潜力。
②针对CALL研究人员,建议他们开发需要学习者产生更复杂目标语言的应用程序,以提高IPA在语言学习中的交互性和教育价值。
研究意义
1、探讨了EFL(英语作为外语)学习者对使用Google Assistant(谷歌助手)进行语言学习的看法。
2、探讨了不同英语水平的EFL学习者对Google Assistant的理解程度以及Google Assistant对他们的理解程度。
3、研究了EFL学习者是否会因为英语水平的不同而影响他们对Google Assistant的看法。
4、了解了EFL学习者在与Google Assistant互动过程中遇到的沟通中断问题以及他们采用的策略。
启示
该文章为调查大学生在使用智能个人助理 (IPA) 进行第二语言 (L2) 学习的研究,其中研究了EFL学习者是否会因为英语水平的不同而影响他们对Google Assistant的看法,得出在与IPA(如谷歌助手)交流时,更高级别的学习者与 GA 实现了更好的相互可理解性,而较低水平的学习者可能会遇到更多的沟通障碍。可作为编码的一个角度来进行思考。
-
本周进度:
在Web of Science, Google scholar, Scopus, and Wiley中初筛出36篇,按照以下标准进一步筛选,发现有14篇不符合,最后剩下22篇。
(1)对语言教育进行了实证研究; (2) 使用语音识别聊天机器人; (3) 包含有关聊天机器人设计的足够信息; (4) 包含足够的信息来清楚地描述学生对聊天机器人的经验或观点。
-
-
- 标签:
-
加入的知识群:
.jpg)

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~