-
知识图谱技术路线
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
10.2.1知识图谱类型与结构
【知识图谱的类型】
1.常识|领域|专业 知识图谱,常识知识图谱,一般挖掘的是这些词之间的语义联系,是一些非常稳固的常识性先验知识,如「阿司匹林」-「消炎药」,非常在意准确性;比较主要的 Relation 包括 isA Relation、isPropertyOf Relation
2. 百科全书知识图谱:对于百科知识图谱,一般会在意实体和实体之间的事实,如「王菲」-「妻子」-「李亚鹏」则需要经常更新;
预定义一些谓词,比如说 DayOfbirth、LocatedIn、SpouseOf
更实用的分法是:领域知识图谱和百科知识图谱,比如医疗知识图谱,药品知识图谱,这种垂直领域的知识图谱通常数据来源和应用领域都比较专业和固定,而百科知识图谱更像一个大杂烩。 【知识图谱架构】
一、模式层:
模式层最重要的工作概括为确定数据结构:哪些实体,实体类型,关系,关系类型,属性,属性类型,确定表示的粒度。
Schema属于模式层,用来规范KG的领域与描述对象,即schema描述了知识图谱的数据结构。其实就是用来描述本体层(Ontology)。为知识图谱设计Schema相当于为其建立本体(Ontology),标准的KG包括如下几部分,概念和实体是并列关系,
- 概念和概念层次关系
- 属性和属性值类型
- 关系, 关系定义域概念集, 关系值域概念集
ps:额外添加规则(Rules)或公理(Axioms)来表示模式层更复杂的约束关系;在垂直领域的知识图谱,你就只需要定义实体类型,关系类型,属性类型。
二、数据层:
数据层的水很深,技术栈很长很深,每一个点看起来都有点小众,仔细一查又有大量的分散的方法,又无法确定是否真的实践有用,非常的让人头秃。简单概况数据层的工作:
1.「数据获取」结构化数据能否直接使用,半结构化数据如何转换,非结构化数据如何信息抽取。
2.「清洗整理」单位,格式等的同义,知识缺失时其他标签填充,为缺失的属性构造抽取器,可以利用上下位等概念,或者其他机器学习深度学习方法,单源数据属性融合,多源数据的知识融合:实体对齐,关系对齐,实体消岐,实体链接等。
3. 「数据库」图数据库的选择,存储方式的选择,索引等的设置。
4. 「知识更新」:可以周期性更新,实体的拓展,监控热词更新,关键词搜索引擎的更新。
-
10.2.2 实体标注
一、获取语料(即语言材料,语料是构成语料库的基本单元。)
- 现成语料
在日常生活中的书籍、文档等等资料都可以整合处理后变成语料库来进行使用。
- 网上抓取语料
网上抓取语料,在互联网上每天都会产生大量的文本,例如微博、论坛、留言等等都是可以抓取获得经过处理作为语料库的。其特点就是容易获取且是电子版可以在抓取的时候直接转换成需要的格式。难点在于网上的文本数据的用法有可能跟我实际生活中有差别需要进行进一步的处理。
- 人工采集语料
对于特殊需求的语料只能进行人工采集,例如儿童的文本对话,日常生活中的对话等等。在特殊场景上应用基本上都需要人工进行采集,采集特点会根据需求场景进行规范语料内容,在特定的规范中发挥人本身在生活中的实际对话进行采集。这类采集目前阶段需求量还是非常大。
二、语料的处理
上面提到的不管是现成的语料、网上抓取语料还是人工采集语料都需要做进一步的处理之后才能应用,那么语料的处理过程往往会占据完整的中文自然语音处理工程中的50%-70%的工作量。基本上需要经过如下4个方面数据清洗、分词、词性标注、去停用词进行语料的处理工作。而这4个方面大部分需要进行人工进行处理。
- 语料清洗
语料清洗一般可以从几个维度进行。- 数据格式清洗(不符合需求格式的数据进行清洗)
- 脏数据清洗(对我们不需要的数据进行清洗)
- 数据内容清洗(例如我们只需要文章标题,不需要作者就需要根据实际需求进行对已有的数据进行清洗)
- 数据格式清洗(不符合需求格式的数据进行清洗)
- 分词
分词是对文本分析非常重要的一步,但分词方法又有很多种,所以我们就需要根据我们项目需求,提前设定好分词的颗粒度、以及一些特殊词的分法。以免后期处理产生歧义。这一部分可以结合分词算法来加快数据标注的进度。但是分词算法也有非常多,需要大家根据大家的需求进行选择。如:正向最大匹配算法、逆向最大匹配算法、最大Ngram分值算法、全切分算法、双向最大最小匹配算法等等。
- 词性标注
词性标注,就是给每个词语打标签,如形容词、动词、名词等。词性标注在大部分的处理中是非必须的,只是类似情感分析、知识推理等是需要的。但是相对其他标注词性的标注也是需要更多专业知识的。
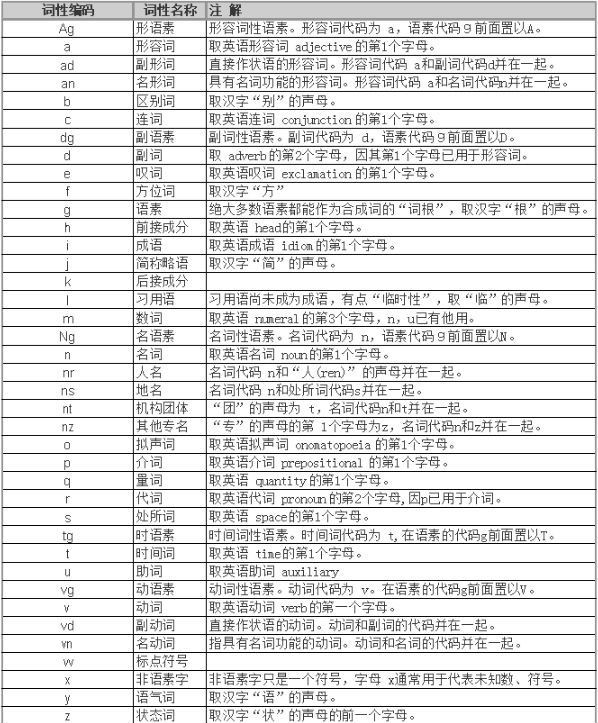
- 去停用词
停用词一般指对文本特征没有任何贡献作用的字词,比如标点符号、语气、人称等一些词。去停用词的操作一定要根据场景进行,有些场景是需要语气词来进行判断情感。
3.NLP文本标注方法
所以可想而知在拿到数据的第一阶段是很头痛的,你会发现维度太多了,而且种类也太多了,每种产品的留言也有可能是不一样的。那么我们就需要从更高维度去分析提出共性和基本处理原则。所以,我们可以从三个维度去考虑。

1.总体原则:这个标注过程中必须遵守的基本原则。
例如:最简原则/最小原则,可以理解成在分词过程中用到的最小颗粒度的分词方法。例:和平饭店,可以分和平饭店整体,也可以分为和平/饭店,那么在这里我们就分为和平/饭店。
2.特殊定义:在标注过程中特殊情况的处理方法。
例如:在分词当中可以遇到的一些专有名词,就不进行拆分等。
3.标注需求:对具体标注过程进行说明。
标注需求部分,我们还是进行两类的区分考虑。
a.词性的角度。
例如:标注的我们需要分为哪些,可以更好的贴切与我们的需求。在本次需求里我们要分析用户对产品的全流程的使用体验,那么能涉及到什么?留言会有什么?首先情感是必须存在的一类。那么什么可以哪些特征词可以表示出客户的情况呢?那么理解到了核心的问题点。特征词和情感词。
b.事件的角度。
什么是事件的角度?本次需求当中需要点会涉及到非常多种类的产品。但是不管什么产品都需要经过一个全流程的事件,最后产生用户反馈。那么在这个全流程过程中哪些点是可以影响用户体验的。这样这个事情的逻辑就出来了,例如:物流、包装、品牌等等。就可以根据实际情况去设定对应的事件了。
-
10.2.3 关系挖掘
10.2.2 关系挖掘
1. 关系抽取
当信息来源是非结构化文本时,构建知识图谱关键的一步是需要从非结构化文本中抽取去结构化信息。知识图谱中的信息抽取是从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术。在知识图谱构建所需的RDD三元组结构中,一般抽取的信息也是「实体」-「关系」-「实体」,知识图谱的构建会先确定好要抽取的信息,确定抽取信息的schema, 然后基于schema去抽取信息。
2. 关系抽取难点——关系重叠
数据中有可能只有一个实体对及关系,也有可能是一个实体同另一个实体之间存在着多种关系,还有可能是一个实体与其他不同实体之间存在着多种关系,这种现象被称为关系重叠。
关系重叠问题在实体关系抽取中会影响抽取的性能,所以解决各种关系重叠类型的实体关系抽取、提高抽取性能是目前研究的重点。
关系重叠,例如:
- Single Entity Overlap (SEO) 单一实体重叠:两个三元组之间有一个实体重叠
- Entity Pair Overlap (EPO) 实体对重叠 :即一个实体对之间存在着多种关系
- Subject Object Overlap (SOO) 主客体重叠 :既是主体,又是客体
3.抽取方法
a.按模型结构分类,关系抽取主要分为 Pipeline 和 Joint 方法。
(1)流水线(Pipeline)方法
先从文本中抽取全部实体(e1,⋯,en),然后针对全部可能的实体对(ei,ej),i≠j判定其之间的关系类别。
(2)联合抽取(Joint extraction)方法
通过修改标注方法和模型结构直接输出文本中包含的(ei,rk,ej)三元组。对于 联合抽取(Joint extraction),又可以分为 "参数共享的联合模型" 和 "联合解码的联合模型":
b.经典的实体关系抽取方法主要分为有监督、半监督、弱监督和无监督这4类。

深度学习的实体关系抽取任务分为有监督和远程监督两类。
在有监督中, 解决实体关系抽取的方法可以分为流水线学习和联合学习两种
远程监督方法缺少人工标注数据集, 因此, 远程监督方法比有监督多一步远程对齐知识库给无标签数据打标的过程,而构建关系抽取模型的部分, 与有监督领域的流水线方法差别不大。
-
10.2.4 知识图谱可视化
知识图谱主要数据模型是RDF数据模型,即Resource Description Framework资源描述框架的基础架构是一个资源(subject)-属性(predicate)-属性值(objecct)这样的一个三元组(triple),由模式(schema)的描述方法并支持推理。知识图谱可以认为是以RDF或属性图表示的知识数据本身。其可以用图数据库存储也可以用其他数据库存储。2000年的时候Neo4j为了解决多媒体关系系统中schema 经常会发生重大变化的问题,提出了用图的方式进行数据的组织、存储与应用。经过发展于2010年正式提出了属性图模型。属性图数据模型跟RDF数据模型的起源于发展是两条线,只不过因为属性图更加易于理解并且通用(更接近通用的图抽象方法)知识图谱也可以用属性图模型存储。知识图谱中常用的RDF模型可以认为是图在语义方向的一种特种模型。
知识图谱是图分析与可视化所基于的图数据中的重要组成部分。知识图谱是一种数据形式,基于这种结构化的数据可以支持从数据分析、智能问答、反欺诈等一系列智能应用。而图分析与可视化是一种基于复杂网络的可视化形式与分析手段,其数据基础是各种图数据,知识图谱只是图数据中的一种。除了知识图谱数据,还可以从其他角度得到不同的图数据,例如各对象间的信息、资源、资金或人员流动与传播的数据;此外,还可以根据各个对象间的特征进行相似度计算,从而生成对象间的相似度网络,并进行展示与分析,如果我们想构建文献相似度图谱,需要根据文献摘要间的文本相似度构建相似度网络,进而利用图挖掘算法进行分析。我们可以基于以上不同规则定义,通过不同手段得到的图数据,进行展示与分析。
图可视化就是把图数据中的节点和边用可视化的网络表示出来。专用的布局算法可以计算网络中节点的相对位置,从而在平面或者3D空间中对其进行较为清晰的展示。而交互式可视化工具是人们从关联数据中识别洞察并产生价值的重要桥梁。图可视化的优点有很多,例如:
- 更快吸收信息。因为人脑处理视觉信息的速度比书面信息要快得多,直观显示数据有利于更快地理解数据,从而快速采取行动。
- 通过与数据进行交互,更高效地提出见解。图可视化工具提供了处理数据的可能性。它鼓励使用数据,提出质疑,增加了发现可行性见解的可能性。一项研究表明,与仅依靠托管报告和仪表板的管理者相比,使用视觉数据发现工具的管理者发现关键信息的可能性要高28%。
- 通过可视化的模式和背景更好地理解问题。图可视化工具不仅可以展示可视化关系,也可以帮助理解数据的背景。通过图可视化工具,可掌握事物之间连接的完整概述,进而识别数据中的趋势和相关性。
- 图可视化是一种有效的沟通方式。视觉表示提供了一种更直观的方式来理解数据,并且是与决策者共享数据发现的有效媒介。
- 不仅是技术用户,每个人都可以使用图可视化工作。不需要特定的编程技能既可实现与图可视化的交互,使得更多的用户能通过图可视化提出观点,增加创造价值的潜力。
-
参考文献
[1]李亚琴,周奕琦.基于知识图谱的数据安全教育研究现状[J].对外经贸,2022(08):142-144.
[2]范柏乃,盛中华,韩家旻,吴赞儿,韩飞.中外区域技术创新知识图谱比较研究[J].自然辩证法通讯,2022,44(11):69-83.DOI:10.15994/j.1000-0763.2022.11.009.
[3]钟卓,唐烨伟,钟绍春,赵一婷.人工智能支持下教育知识图谱模型构建研究[J].电化教育研究,2020,41(04):62-70.DOI:10.13811/j.cnki.eer.2020.04.009.
[4]李振,周东岱.教育知识图谱的概念模型与构建方法研究[J].电化教育研究,2019,40(08):78-86+113.DOI:10.13811/j.cnki.eer.2019.08.010.
[5]陈悦,刘则渊.悄然兴起的科学知识图谱[J].科学学研究,2005(02):149-154.DOI:10.16192/j.cnki.1003-2053.2005.02.002.
[6]陆星儿,曾嘉灵,章梦瑶,郭幸君,张婧婧.知识图谱视角下的MOOC教学优化研究[J].中国远程教育,2016(07):5-9+79.DOI:10.13541/j.cnki.chinade.20160726.005. -
-
- 标签:
-
加入的知识群:

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~