-
课堂行为识别
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
【学习目标】
1. 了解课堂行为识别的基本概念和研究进展。
2. 掌握卷积神经网络和姿态识别的算法和识别原理。
3. 能够利用相关算法,实现行为图片识别和姿态图片识别。-
【学习建议】
1. 学习建议的学习时长为6课时。
2. 阅读相关的书籍和文献。
3. 积极思考课堂行为识别原理。
-
【章节思维导图】
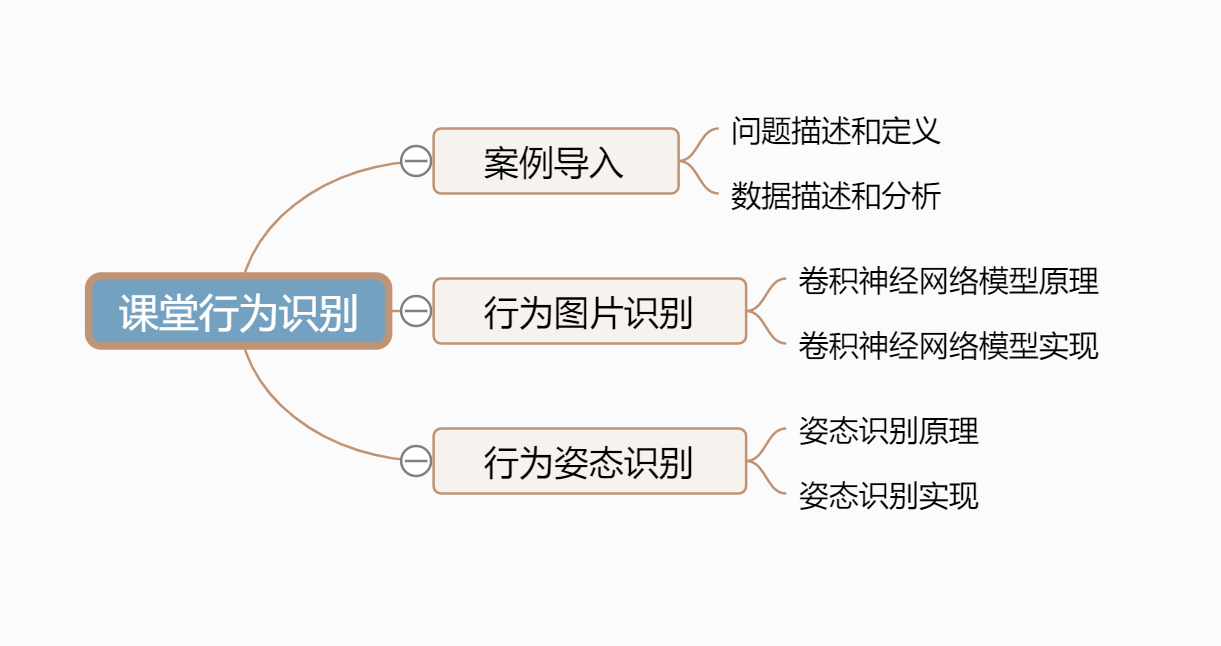
-
9.1案例导入
9.1.1问题描述和定义
1.问题描述
在21世纪中,伴随着科学技术的突飞猛进,人工智能相关技术的快速革新,相应的人工智能产物也逐渐应用到了教育领域。将人工智能引入到课堂教学研究中,获取并分析学生课堂行为,将对改进教学方式,提高教学质量具有极大帮助。本章节采用实际课程教学来获取学生课堂行为数据进行分析,实践教学内容以PyTorch的深度学习架构为基础,采用Python3.7版本,在 GPU的高速平台上进行了行为辨识模型的训练。该平台采用英特尔 Intel XeonE5-1630v3@3.7GHz四核处理器,16 GB的内存,4块 Ge ForceGTX1080 it GPU,总共44 G的显存。
2.课堂行为识别定义
在学生课堂行为类别的定义方法中,S-T分析法是目前比较成熟和常用的课堂行为分类方法,S-T分析法是一种基于学生(Student)和教师(Teacher)的课堂行为检测和统计的方法,也是对课堂教学过程与教学质量评价与反馈的一种分析方法。课堂行为识别是指在一定的采样频率中,对某个教学过程或者研究过程进行观察,再通过另外一个采样频率来进行采样,将采样结果数据进行系统化分析从而得到分析结果以改进教学过程。
S-T行为分类 行为主体 课堂行为分类 T行为 讲课、注意课堂动态、板书、提问、使用多媒体、走动观察学生 S行为 起立、听讲、讨论、思考、做笔记、发言、沉默、做实验 将研究实际与S-T行为分析法结合,本章以研究学生课堂行为为主,对S学生(Student)的计算,记笔记和做练习统一定义为书写行为;根据教学实际中出现的其他行为数据,最终确定了课堂行为中最具代表性的书写,发言,举手3种积极行为,睡觉和玩手机2种消极行为,共5种学生行为进行研究,这5种行为对于教师改进教学方式,学生调整听课习惯具有重要价值。
9.1.2数据描述和分析
1.数据描述
在行为辨识方面,主要包括动作识别,表情识别等以及目标辨识与姿态预测等。由于目前已有的大量数据集如 Mnist,ImageNet等,所以在进行学生课堂行为数据集构建时,首先要对经典数据集、中等规模数据集、深度学习数据集进行分析。
经典数据集可包含:KTH数据集 、Weizmnn数据集;中等规模数据集 :UCF101数据集 、HMDB51数据集。以上为已经开发研究课堂行为识别数据,可用于本研究行为识别数据库且额外加强。
1.1数据采集
数据类别分析完成之后将采用相关设备对教学活动全过程动态监测,采用摄像机与教室四角监控来对课堂全方位的记录学生的课堂行为。
1.2数据处理和去敏
将所采集数据进行数据预处理,对于采集过程中对结果产生误导性数据进行处理,数据处理过程中需要使用大量数据处理设备,从而避免处理者的主观性行为对数据处理产生不可逆影响。
1.3数据集制作
在教学过程中采取数据经过数据处理将生成由课堂行为分类而形成的数据结果,对数据结果再次分类集合,对数据集进行分类讨论。
2.数据结果分析
对所有采集数据经过处理得到最终数据结果,数据集分别被通过不同类别标记符进行标记和数据清洗来获得目标数据,采用YOLOV3方法进行数据分析结果讨论,将数据结果分别导入进行可视化分析得到相关需要结论,
-
9.2行为图片识别
9.2.1卷积神经网络模型原理
卷积神经网络是一种前馈神经网络,它可以根据自身的层次结构对输入的信息进行不变性分类,也就是“平移不变性”,进入21世纪后,由于有许多学者对此进行了深入的研究,卷积网络在自然语言处理和计算机视觉等方面得到了广泛的应用。
卷积神经网络的结构主要由输入层,卷积层,池化层,全连接层,激活函数和输出层组成。卷积层和池化层是相互邻近的,它们彼此之间几乎是相互交错的,CNN把图象的特征空间当作网络的输出,然后把这些特征空间输入到整个连接层,从而实现对图像的分类。
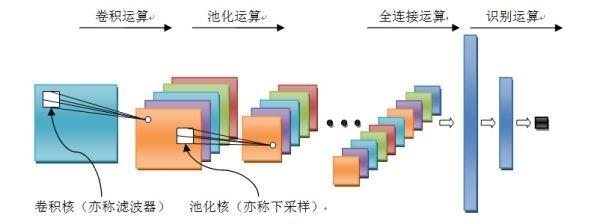
(1)卷积层
卷积层由多个特征面构成, 直接对原始输入矢量/信息进行卷积运算, 是 CNN的基础。每层卷积层可由多个卷积单元构成, 利用反向传播算法得到每个卷积单元的最优参数。卷积层是模仿拥有局部感受野的简单细胞, 利用局部连接和权值共享的方法, 获得某些初级视觉特点的过程。进行卷积运算的目的是获得输入矢量/信息的不同特征。第一层提取较低级的特征, 比如线条、边 缘和角等低层级特征。更多层的网络利用迭代的方法从众多低级特征中提取出更高级的复杂特征。局部连接是指卷积层上的每个节点与上一层特征图中固定范围的节点建立连接。权值共享是指用一组相同的连接强度将同一特征图中的节点与上一层局部建立连接。“一组相同的连接强度”也就是一个特征提取器, 在实际运算中表现为一个卷积核。卷积核通过一定的步长在特征图上“移动”, 每移动一次就是进行了一次卷积操作。通过累积多次卷积操作, 从而提取输入矢量/信息的众多不同特征。也就是说每一个卷积核提取一种特征, 这样n个卷积核就提取了n种特征。卷积层的计算形式见公式: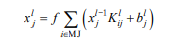
式中: f ( )代表激活函数; K代表卷积核; l 代表卷积层数; MJ是输入层的感受野; b代表每个输入图的一个偏置值。
(2)池化层
池化层是模拟复杂细胞把低级的视觉特征筛选、结合成更高级的抽象视觉特征的过程。实际上是一种降采样。池化层有多种非线性池化函数, 而其中最常见的是“最大池化”。最大池化将输入的图像划分为多个矩形区间, 对每个子区间计算并输出最大值。特征图的输出数量经过池化层采样后不会变, 但其尺寸会变小, 因此有降低计算复杂程度、抵抗微小扰动变化的作用。(3)全连接层
经过若干个特征提取层后, 网络会接入一个全连接层。该层的每个节点都与上一层的所有节点相连接, 同一全连接层的节点之间不连接。全连接层的作用是限制网络规模的大小和增强网络的非线性映射能力。
9.2.2卷积神经网络模型实现
对于不同复杂场景中存在的光照、遮挡、视角变化等问题,传统手工特征并不具有普适性,因此以深度学习的方式从数据中自动学习特征可能更有效利用深度学习模型去自动提取数据中的特征,避免了人工设计特征过程中的盲目性和差异性。
基于深度学习的课堂行为识别方法以端到端的方式,利用可训练的特征提取模型从视频中自动学习行为表征来完成分类。
(1)卷积神经网络
卷积神经网络是一种使用卷积核进行卷积计算且具有深度结构的前馈神经网络,被广泛应用于行为识别领域。卷积神经网络中上层与下层的参数并不是一一进行连接的,卷积神经网络通过卷积核作为中介,使得图像之间可以共享相同的卷积核。主要被应用为利用其3D卷积核进行卷积运算,对视频沿着空间和时间维度直接提取时空特征。
(2)循环神经网络
循环神经网络常被用于对时间序列数据进行建模和特征提取,通过时序门控制时序数据的特征表达在循环神经网络中,每一层神经元的输出都可以在下一时间段应用于自身,循环神经网络可以看成是一个在时间上传递的神经网络,因此循环神经网络的深度是时间的长度。现今主要被应用为:通过卷积神经网络提取视频图像帧中的空间相关性,并产生基于运动的注意力映射,依靠视频级别的动作标签便可以利用注意力映射来定位动作的时空位置。
(3)图卷积神经网络
图卷积神经网络主要被使用于提取空间特征,传统卷积操作只能处理非常整齐的矩阵,图卷积操作就可以对骨骼数据这一不规则的数据进行精准的特征表达。图卷积神经网络实际上跟卷积神经网络的作用一样,就是一个特征提取器,只不过它提取的对象是图数据。图卷积神经网络精妙地设计了一种从图数据中提取特征的方法,从而让我们可以使用这些特征去对图数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding)等。
-
9.3行为姿态识别
9.3.1姿态识别原理
人体姿态估计(Human Pose Estimation)是计算机视觉领域中一个尤为重要的分支,其应用范围非常广泛,诸如行为识别、体感游戏、运动预测、医疗康复等领域。人体姿态估计的整个过程可以分为两步,首先通过分析图像得到图像中人体各部位的关键点信息,然后将关键点连接形成肢体骨架。其目标是检测出图像中人体的一些主要关键点,比如鼻子、手腕、肩膀、膝盖和脚踝等,并将这些点以一定的顺序、方向连接起来。人体关键点组成的人体姿态是人体行为特征中很重要的一种表征,尤其是在视频数据中,可以通过将多帧的人体姿态串联在一起形成某种行为轨迹,是重要的行为描述子之一。因此,人体姿态估计对于诸多领域都有重要的意义。 学习者姿态识别是人体姿态识别在教育领域的具体应用。学习者在课堂上的姿态能够反映出学习者是否在学习过程中进行了较好的参与及思考,学习者姿态识别能够有效地评价学习过程中学习者的学习状态,使教师得到更多的反馈信息,对于教师事后分析学习者的学习状态、改进教学过程及提高教学质量具有重要作用。
传统方式和基于深度学习的方式是目前主流的人体姿态识别算法。传统的识别方法是一种根据图形结构和可变形构件模型设计二维人体部件探测器,通过图形模型建立各个构件之间的连通性,并且在人体运动学的约束条件下,通过优化图形结构模型来估计人体的姿态。在这种传统方法的理论基础上,通常只能通过图像与身体位置曲线或关节曲线之间的非线性映射模型来实现人体姿势的识别估计。基于深度学习的人体姿态估计方法主要是利用卷积神经网络 (CNN)算法来定量提取图像中的人体姿态特征。与传统的人工设计特征方法相比,CNN 不仅需要具有足够丰富且完整的语义信息特征,此外,还需要能够获得具有不同姿势感觉场的每个人类节点特征的特征向量,并通过完整上下文语义类描述每个节点的特征,摆脱了对构件模型结构设计的依赖,进而直接使用坐标回归和特征向量模型来全面充分地反映当前人类对姿态的感知,从而将姿态信息直接应用到各种特定且具体场景的开发实践中。该算法具有速度快、准确性强以及在复杂条件下鲁棒性强的优势。随着深度学习目标检测算法的不断改进和优化,研究人员通过研究不同深度的网络、卷积核大小和特征尺度,构造出各种不同的卷积神经网络并取得了优良成果。目标检测算法主流方向已经转变为以深度学习为基础的目标检测算法。
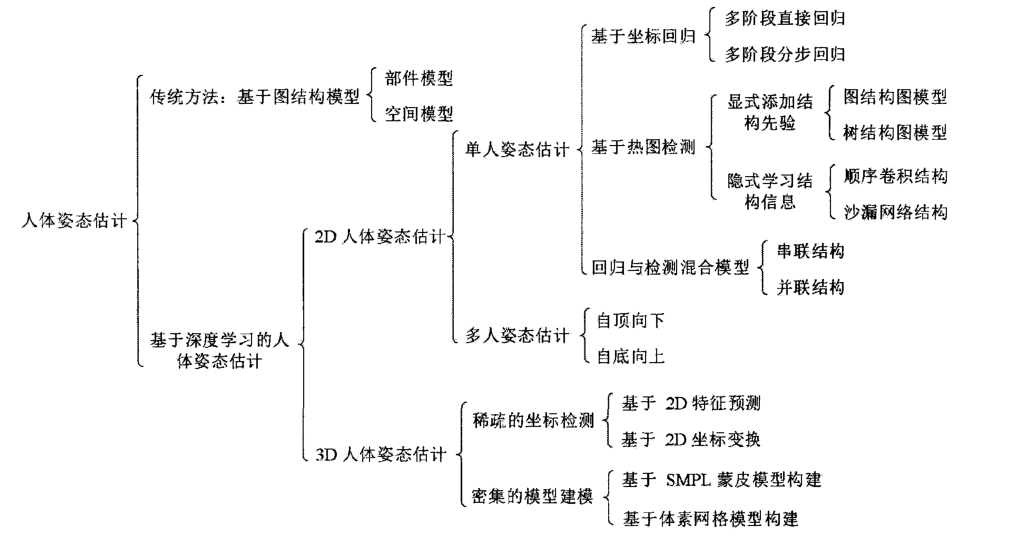
OpenPose 是一个基于卷积神经网络和监督学习的开源项目,主要用于人体姿态识别。当利用 OpenPose 进行目标识别计算时,首先,需要对输入系统中的图像或视频进行预处理,采用归一化的方法对组成图像或视频的数据进行处理,从而便于后续运算。其次 ,采用从上到下的顺序对人体的特征点进行检测,将检测后采集的特征点数据进行矩阵化存储,按照行和列不同的含义进行编码。再次,基于特征点数据,利用神经网络强大的数据拟合能力对采集的特征点数据进行建模,对其中有规则的变化进行数学表征,同时对特征点后续发展趋势(也就是人体关键部位的运动状态)进行预测,以提升特征点在线识别的效率,缩短识别时间,便于在多种类型的设备上进行部署。最后,对建立的特征点数据模型和预测值进行修正,采用残差补全的方法对不准确的结果进行校正,最终确保输出的姿态识别结果符合实际情况和逻辑预期。该算法的检测流程前后共分为两部分。第一部分:采用VGG19提取图像特征,输入图像经过VGG19网络的前10层后生成特征图F(Feature Maps)。第二部分:特征图F输入到后面卷积神经网络,网络共有六个阶段,而每个阶段又有上下两个分支,其中上分支用来预测人体的关节置信度图(Part Confidence Maps),而下分支用来预测人体的部分亲和域(Part Affinity Fields,PAFs)。PAFs编码了各个关键点的联系,用于匹配人体关键点,也是一个二分图匹配(Bipartite Matching)问题,最后得到图像中每一个人的关键点位置及骨骼图像。S(·)和L(·)的内部结构如图所示。

在最近的这二十多年里,目标检测技术大致经历了两个时期:传统的目标检测时期(2012年以前)和基于深度学习的目标检测时期(2012年以后)传统的目标检测技术从1999年的SIFT7(Scale Invariant Feature Transform)算法开始,逐渐出现了很多优秀的算法。该阶段算法中具有代表性的有:HOG (Histogram of Oriented Gradient)、SURF (Speeded Up Robust Features)、DPM (Deformable Part Models)等算法。传统的目标检测技术采用人工特征进行检测,而人工特征的好坏直接影响检测算法的精度,因此这个时期的检测算法普遍存在复杂场景下鲁棒性差的缺陷。直到深度卷积神经网络(Deep Convolutional Neural NetworkDCNN)的出现才打破了这一局限。
基于深度学习的目标检测技术从2014年的R-CNN算法开始,到今天为止,这期间优秀的算法层出不穷,而且每个算法的准确率更高,检测速度也更快。这些算法不再使用人工特征,而是利用深度学习自动提取特征,不仅减少了人类的工作量,而且提高了分类和预测的精度。最具有代表性的算法:R-CNN、SPPNet、Fast R-CNN、Faster R-CNN、YOLO ( You OnlyLook Once)系列算法(YOLOv1、YOLO9000、YOLOv3、YOLOv4、YOLOv5)、 SSD、Mask R-CNN和 RefineDetP等。这些算法具有速度快、准确性强以及在复杂条件下鲁棒性强的优势。随着深度学习目标检测算法的不断改进和优化,研究人员通过研究不同深度的网络、卷积核大小和特征尺度,构造出各种不同的卷积神经网络并取得了优良成果。目标检测算法主流方向已经转变为以深度学习为基础的目标检测算法。
Simonyan等提出了基础的双流网络结构。如图所示,该网络设计了空间流和时间流两个并行的网络,使用两个独立的CNN网络来分开处理视频中空间和时间信息,空间流网络的输入为视频中采样的单帧图像,时间流网络的输入是光流信息,然后将两个网络识别的结果进行融合,最终得到识别的结果.该网络最终在UCF-101数据库、HMDB-51数据库上分别达到了88%、59.4%的准确率.由于它具有非常好的结构,并具有很好的拓展性,所以引起了科研人员的关注。围绕双流网络准确率和鲁棒性,后续涌现了许多改进的算法。

卷积神经网络一般采用2D卷积,在多帧图像上2D卷积的结果是一张特征图,只包含高和宽,而3D卷积的结果是立体的,除了高和宽之外还含有时间维度,因此3D卷积更适合用来处理视频序列的信息。如下展示了2D卷积和3D卷积的区别

循环神经网络在神经网络的输入层、隐藏层和输出层之间的神经元中建立了权值连接,网络模块的隐藏层每个时刻的输出都来自之前时刻的信息。RNN的循环网络模块不仅能够学习当前时刻的信息,也会保存之前的时间序列信息,但对于时间序列较长的信息,RNN容易出现梯度消失的问题,因此提出了LSTM网络来解决这个问题。LSTM网络用一个记忆单元替换原来RNN模型中的隐藏层节点,其关键在于存在细胞状态来存储历史信息,设计了三个门结构通过Sigmoid函数和逐点乘积操作来更新或删除细胞状态里的信息。如图所示为LSTM网络一个单元的内部结构,从左到右分别为遗忘门、输入门和输出门。LSTM网络通过累加的线性形式处理序列信息来避免梯度消失的问题,也能学习到长周期的信息,因此能够用来学习长时间序列的信息。

9.3.2 Yolov5核心基础内容介绍
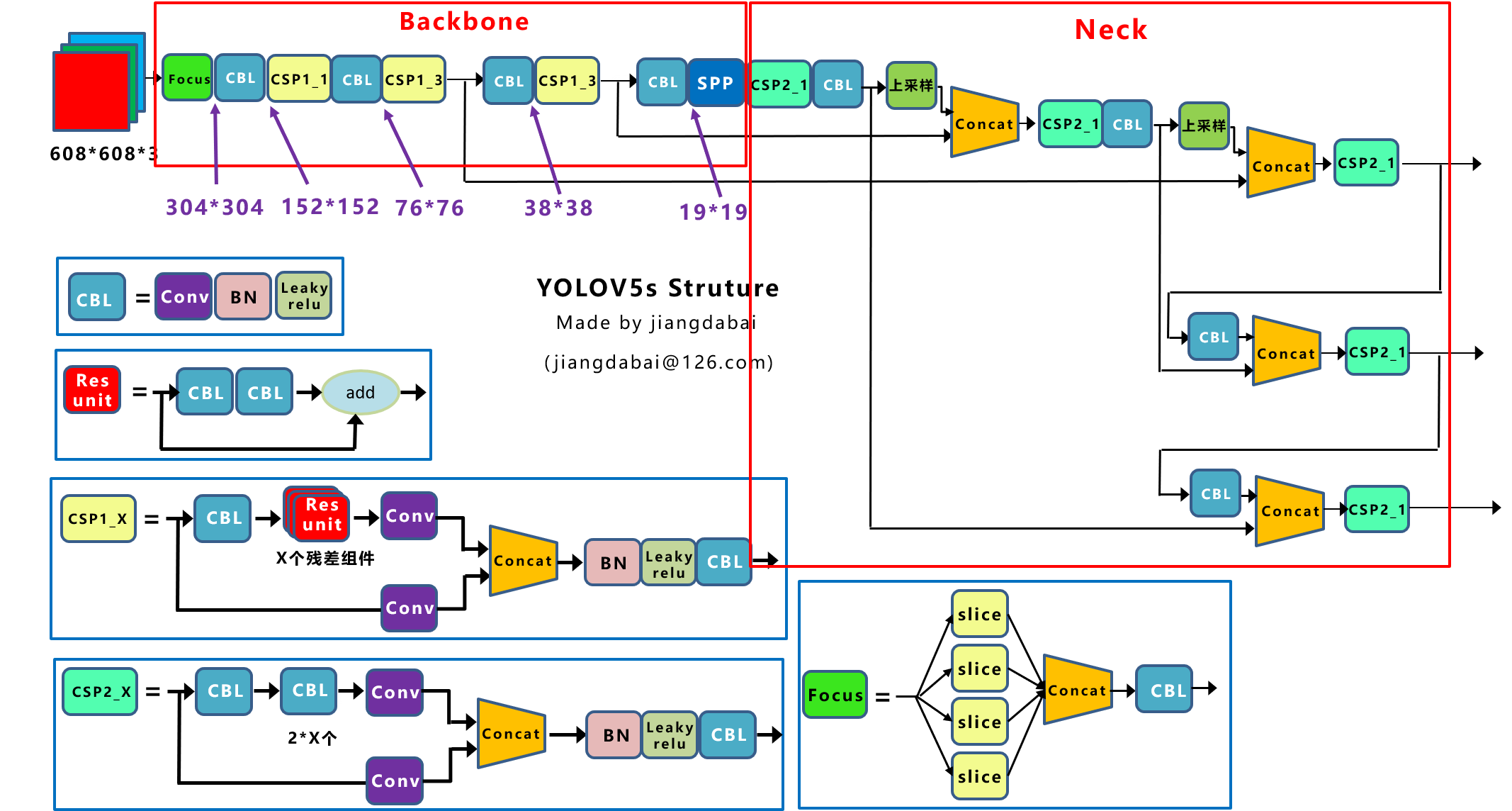
Yolov5的结构和Yolov4很相似,但也有一些不同,按照从整体到细节的方式,对每个板块进行讲解。

Yolov5网络结构图 上图即Yolov5的网络结构图,由图可见,Yolov5还是分为输入端、Backbone、Neck、Prediction四个部分。
(1)输入端:Mosaic数据增强、自适应锚框计算
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
1、输入端
(1)Mosaic数据增强
Mosaic数据增强-YOLOv5中在训练模型阶段仍然使用了Mosaic数据增强方法,该算法是在CutMix数据增强方法的基础上改进而来的。CutMix仅仅利用了两张图片进行拼接,而Mosaic数据增强方法则采用了4张图片,并且按照随机缩放、随机裁剪和随机排布的方式进行拼接而成,具体的效果如下图所示。这种增强方法可以将几张图片组合成一张,这样不仅可以丰富数据集的同时极大的提升网络的训练速度,而且可以降低模型的内存需求。
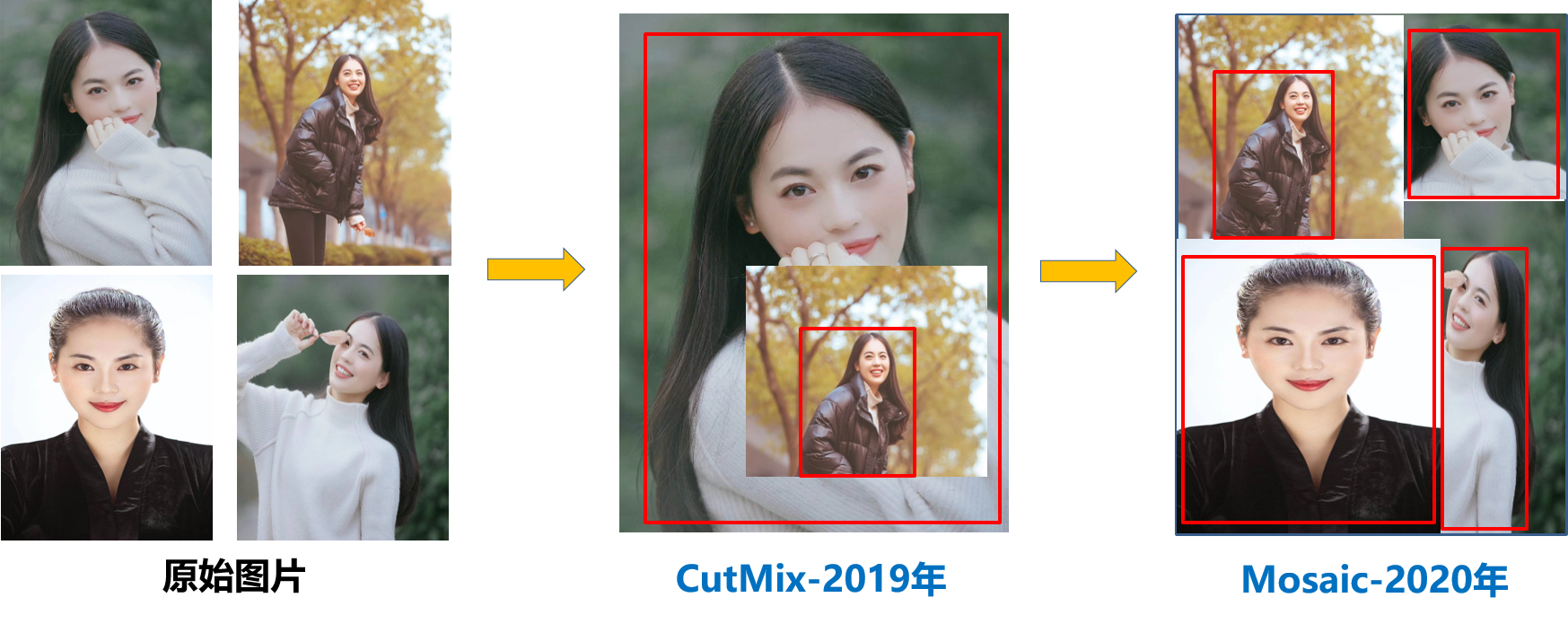
Mosaic数据增强效果 (2)自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

锚框设定 在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
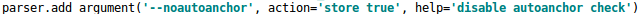
关闭功能实现代码 (3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。比如Yolo算法中常用416×416,608×608等尺寸,比如对下面800*600的图像进行变换。

自适应图片缩放 但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。作者认为,在项目实际使用时,很多图片的长宽比不同。因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此在Yolov5代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。

算法修改后的图片 2、Backbone
(1)Focus结构
Focus结构-该结构的主要思想是通过slice操作来对输入图片进行裁剪。如下图所示,原始输入图片大小为608*608*3,经过Slice与Concat操作之后输出一个304*304*12的特征映射;接着经过一个通道个数为32的Conv层(该通道个数仅仅针对的是YOLOv5s结构,其它结构会有相应的变化),输出一个304*304*32大小的特征映射。

Focus结构 (2)CSP结构
Yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。
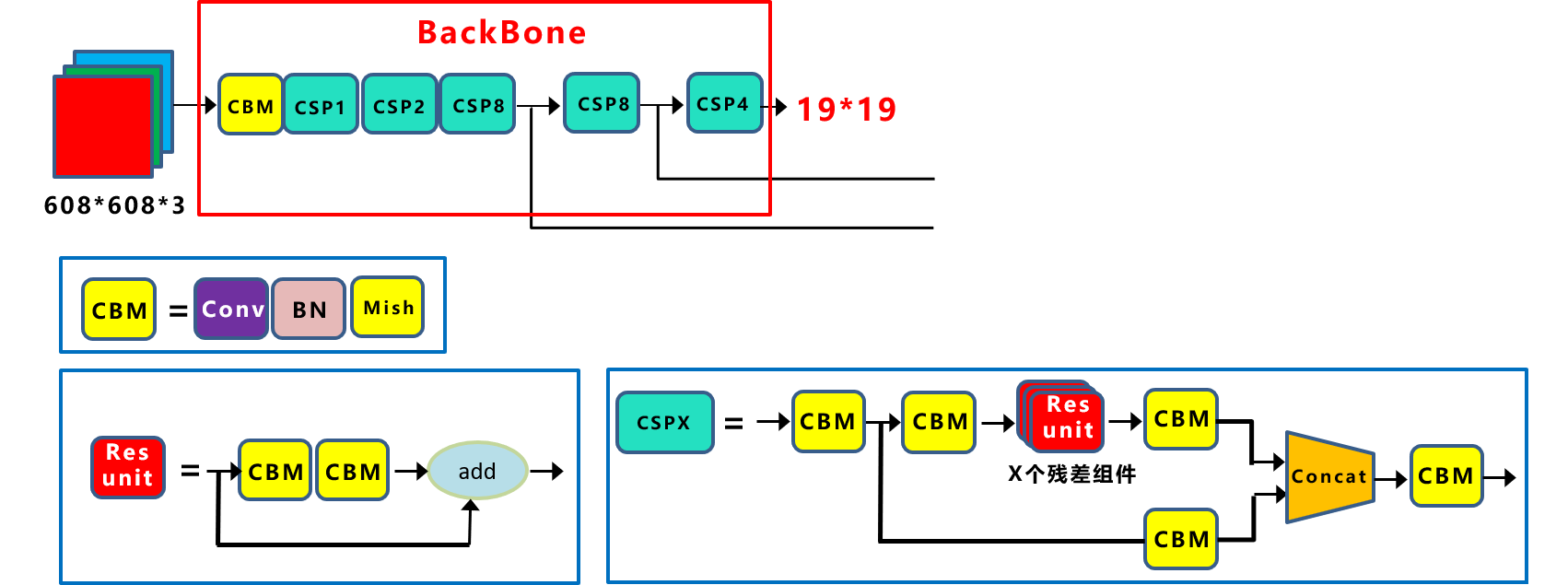
CSP结构 Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构,而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,以CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
3、Neck
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。Yolov5和Yolov4的不同点在于,Yolov4的Neck中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPNet设计的CSP2结构,加强网络特征融合的能力。

Yolov5与Yolov4Neck结构对比 4、输出端
(1)Bounding box损失函数
Yolov5采用CIOU_Loss做Bounding box的损失函数。目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
CIOU_Loss在DIOU_Loss的基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。

其中v是衡量长宽比一致性的参数,也可以定义为:

(2)nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中仍然采用加权nms的方式。
-
【参考文献】
[1]郑丹. 基于双流卷积神经网络的学生课堂行为识别研究[D].沈阳师范大学,2022.DOI:10.27328/d.cnki.gshsc.2022.000260.
[2]卢健,杨腾飞,赵博,等 . 基于深度学习的人体姿态估计方法综述 [J]. 激光与光电子学进展,2021,58(24):69-88.
[3]邓益侬,罗健欣,金凤林 . 基于深度学习的人体姿态估计方法综述 [J]. 计算机工程与应用,2019,55(19):22-42.
[4]刘艳鹏,朱立新,周永章.大数据挖掘与智能预测找矿靶区实验研究——卷积神经网络模型的应用[J].大地构造与成矿学,2020,44(02):192-202.DOI:10.16539/j.ddgzyckx.2020.02.003.
[5]夏磊杰. 基于课堂视频的教学行为智能识别与分析研究[D].华中师范大学,2021.
[6]吴立宝,曹雅楠,曹一鸣.人工智能赋能课堂教学评价改革与技术实现的框架构建[J].中国电化教育,2021(05):94-101.
[7]何秀玲,杨凡,陈增照,方静,李洋洋.基于人体骨架和深度学习的学生课堂行为识别[J].现代教育技术,2020,30(11):105-112.
[8]徐家臻,邓伟,魏艳涛.基于人体骨架信息提取的学生课堂行为自动识别[J].现代教育技术,2020,30(05):108-113.
[9]侯成坤. 基于多模态融合的课堂教师教学行为自动识别研究[D].华中师范大学,2020.DOI:10.27159/d.cnki.ghzsu.2020.001237.
[10]胡佳敏. 基于卷积神经网络的学生课堂行为识别研究[D].华中师范大学,2020.DOI:10.27159/d.cnki.ghzsu.2020.000955.
-
【思考题】
1.课堂行为识别包含哪些技术?原理分别是什么?
2.思考如何将课堂行为识别技术与教学实践相结合
-
-
- 标签:
- 卷积神经网络
- 姿态识别算法
- 机器识别
-
加入的知识群:

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~