-
PISA数据的决策树分析
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
PISA数据的决策树分析(王慧)


教育数据挖掘方法与应用实验报告
姓名
王慧
学号
202105720127
年级
2021级
专业
教育技术学(师范)
学院
教育科学与技术学院
实验二:pisa数据的决策树分析
-
一、实验目的
使用c5.0决策树算法与chaid决策树算法对pisa数据进行挖掘与分析。
-
二、实验工具
spss modeler
-
实验原理
数据清洗:
缺失值处理:检测数据中的缺失值,选择删除包含缺失值的样本,或 者用合适的方法填补缺失值。
异常值处理:识别和处理异常值,这些异常值可能是由于错误记录、 测量误差或其他原因导致的。
数据格式统一:确保数据的格式统一,比如统一日期格式、标签名称 等,以便后续分析和建模。
重复值处理:排查并去除重复的数据记录,避免数据重复引入偏差.
数据转换:根据模型需求进行数据转换,比如对数据进行归一化、标 准化等操作,以便提高模型性能。
数据集成:将来自不同来源的数据整合为一个数据集,确保数据完整 性和一致性。
通过对数据样本进行去重、补缺、除异的操作,使数据可信度与质量提升。
决策树分析:
数据预处理:对pisa数据进行清洗、缺失值处理、归一化等操作, 以便进行后续的数据分析和建模。
特征选择:从pisa数据集中选取与学习成绩相关的特征变量,例如学生的性别、年龄、家庭收入、父母受教育程度、教师质量等。
构建决策树:利用特定的决策树算法(如id3、c4.5、cart等)对选定的特征变量进行递归划分,构建出决策树模型。
模型评估:通过交叉验证、测试集验证等方法对所构建的决策树模型进行评估,检验其分类或回归性能的有效性和稳定性。
结果解释:解释决策树模型中各个节点的意义和分支的判定条件,探究学习成绩与其他因素之间的关系和影响规律。
-
四、实验步骤
1.数据导入
源→选择statistics文件控件拖入,右键选择编辑,导入要处理的文件,应用后确定。
2.数据清洗
输出选项卡→数据审核控件,与源数据连接,右键选择运行-质量。观察源数据,发现源数据中的st005q01ta-st013q01ta的字段含有异常值、空白值和空值,在审核过程中系统给出提示以下字段存在离群值和极值,但考虑到学生的各方面数学可信值取决于学生的表现成绩,各个学生的成绩表现相差较大是合理的,故不做处理。
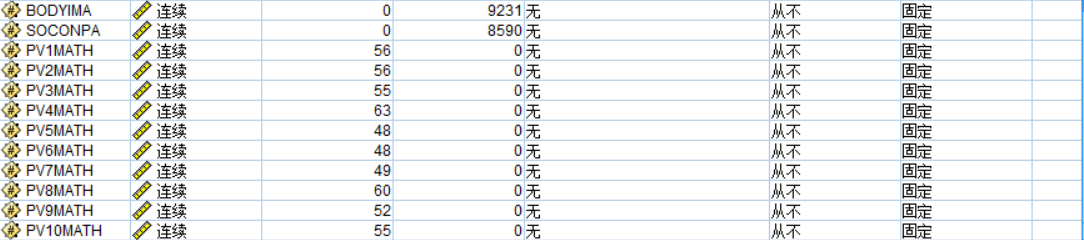
选择st005q01ta-st013q01ta字段,在缺失插补栏选择空值与空白值,方法选择指定-固定为众数后确定,点击上方生成,选择缺失值超节点,即生成缺失值插补。
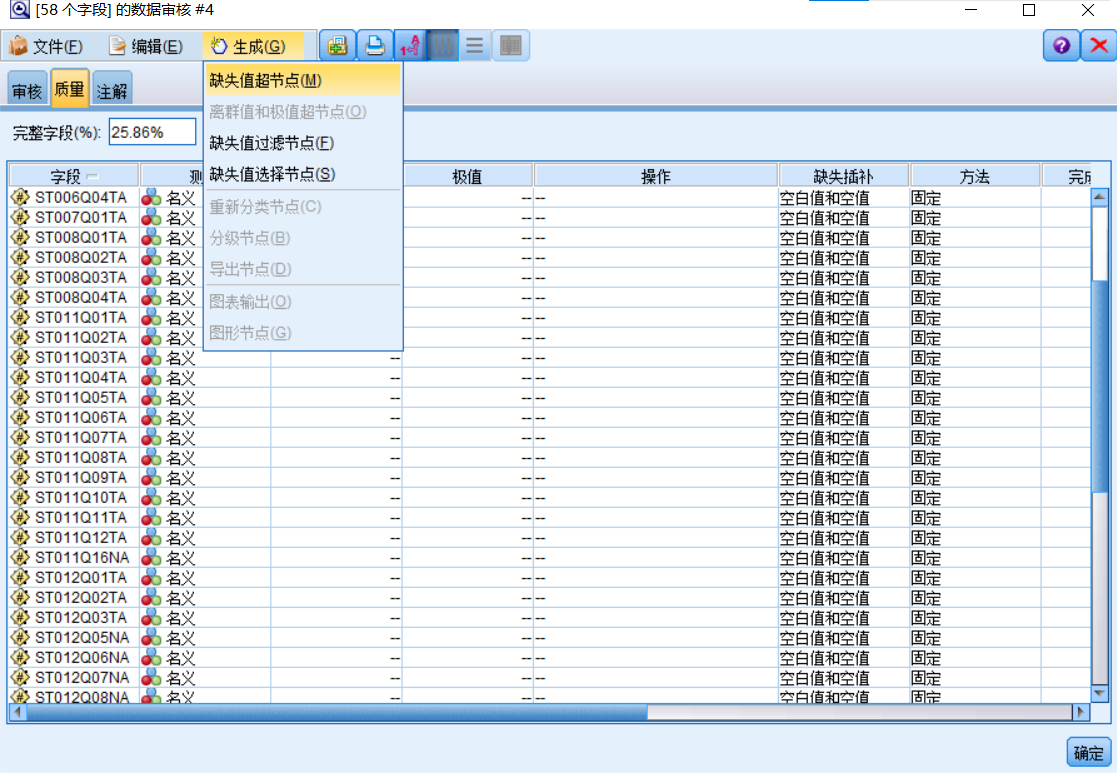
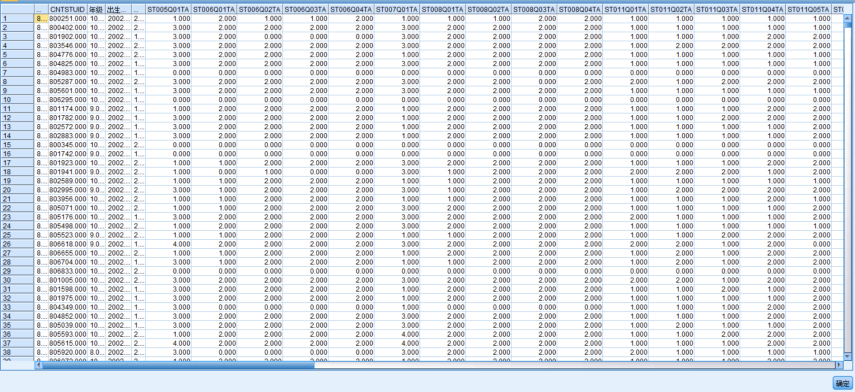
对缺失值插补做可视化表格连接,发现异常数据均已被填写或修改。

再对数据作类型筛选,将缺失值插补连接到类型,右键类型控件后编辑,利用ctrl+a快捷键全选所有字段,修改值选项卡为读取,点击上方读取值,应用后确定,再连接到表格控件,运行后发现异常值均已被过滤。
字段选项→过滤器,与类型连接,经过对数据的分析,对以下无意义(结果为同一个值)字段进行过滤。
-
数据分类
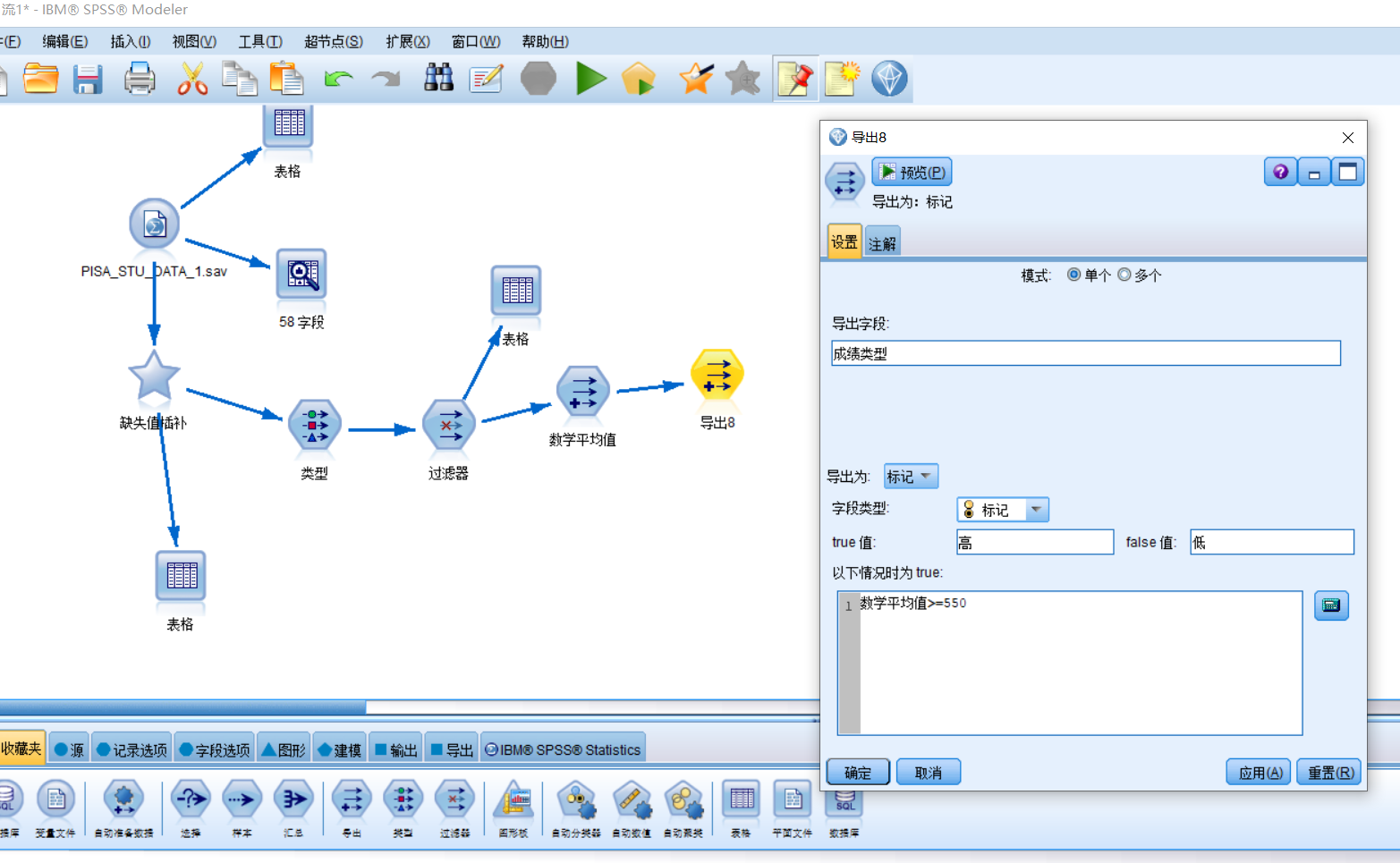
在字段选项中选择“导出”,建立一个成绩类型字段,字段类型为标记,true值改为高低两类,条件为数学平均值>=550。
同实验一,复制实验一中的字段家庭经济情况和文学素养。
根据类型查看家庭经济情况大致数值范围,新建字段家庭经济情况分类,将家庭经济情况分为较穷、中等、较富三类。
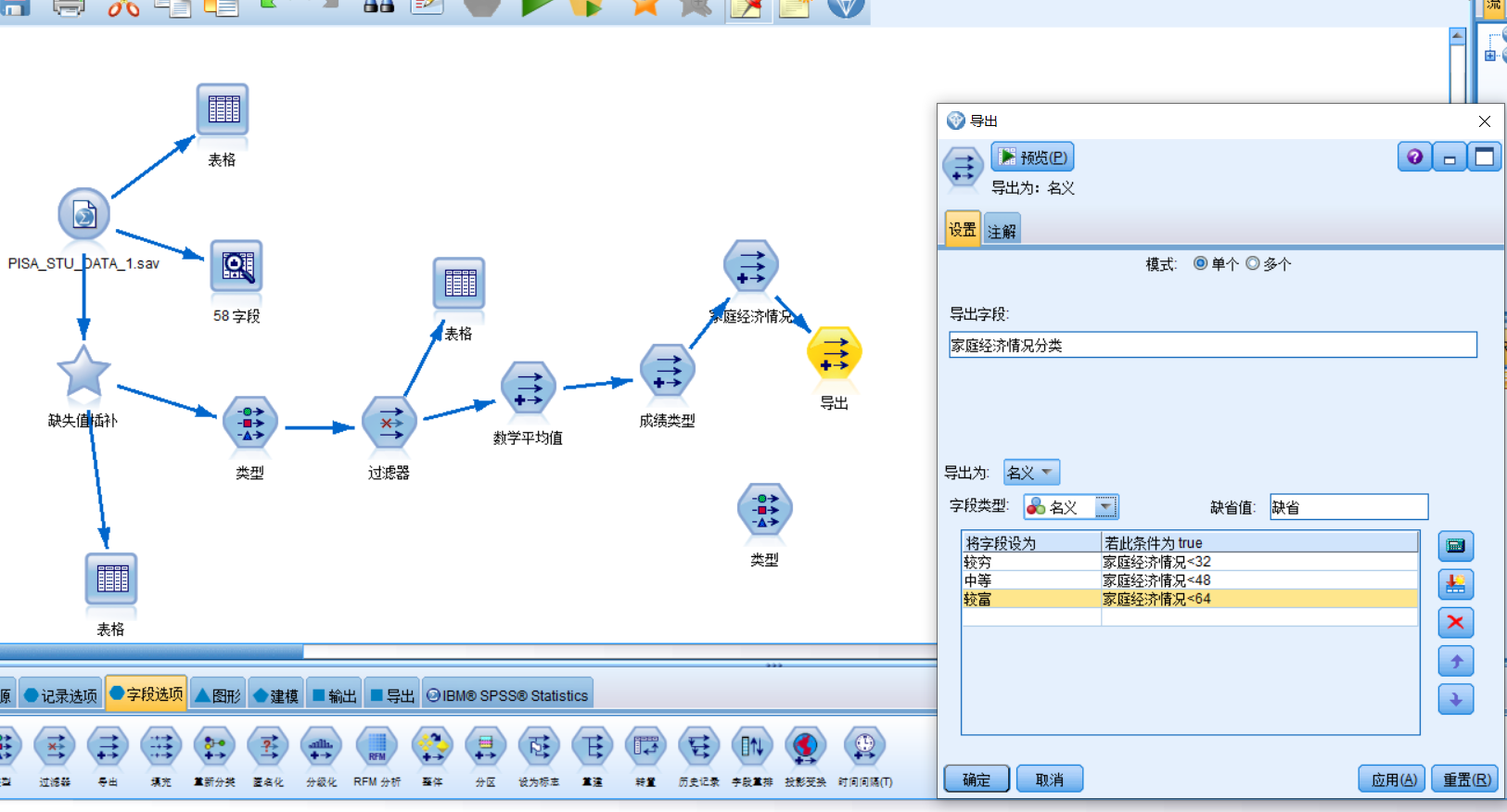
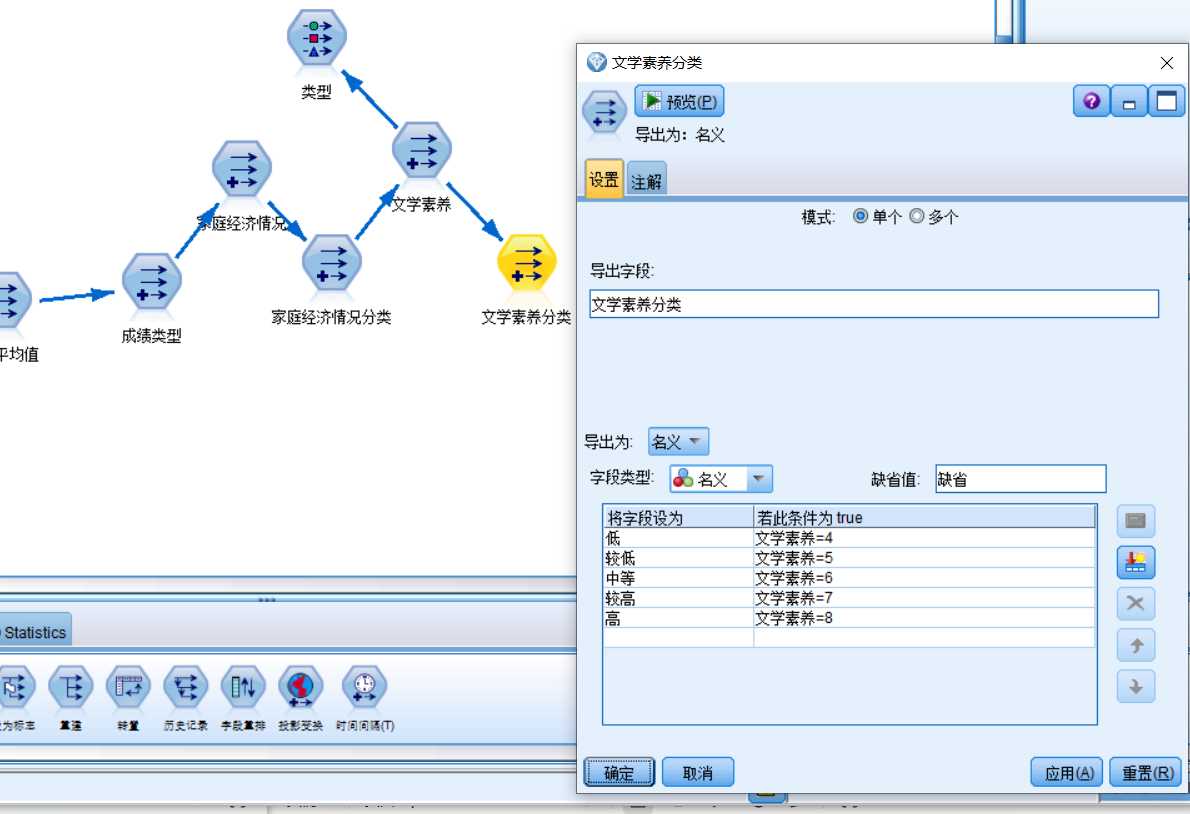
根据类型查看文学素养分类大致数值范围,新建文学素养分类,将文学素养分为低,较低,中等,较高,高五类。
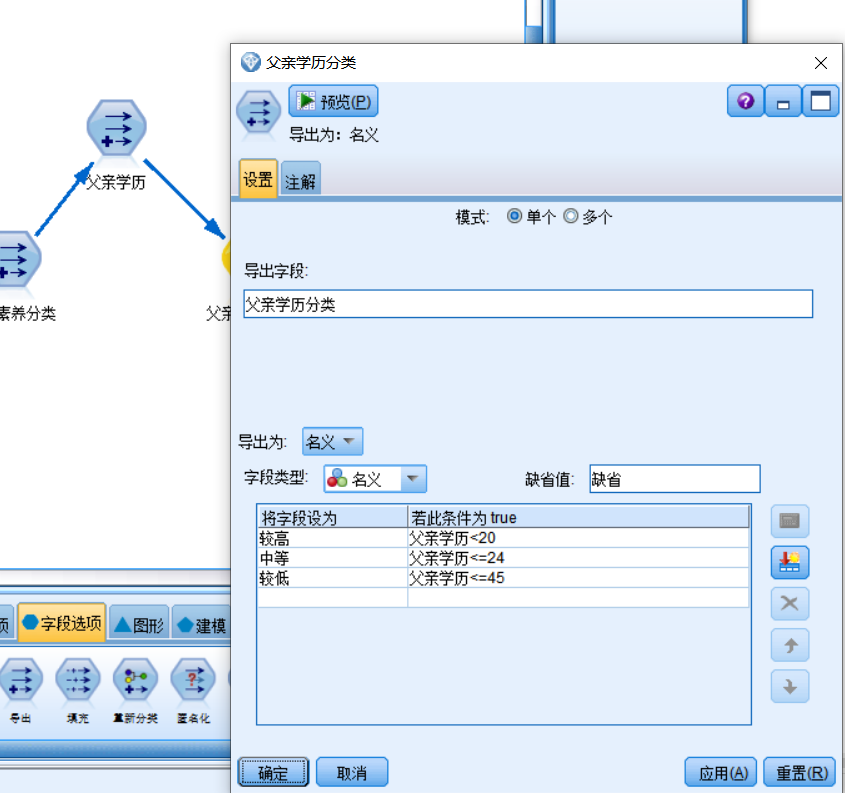
添加字段父亲学历,对学历等级进行权重赋值计算,添加父亲学历分类字段,将学历分为较低中等较高三个。

添加母亲学历以及母亲学历分类同上。
添加学习资源与环境字段与学习资源与环境分类字段。
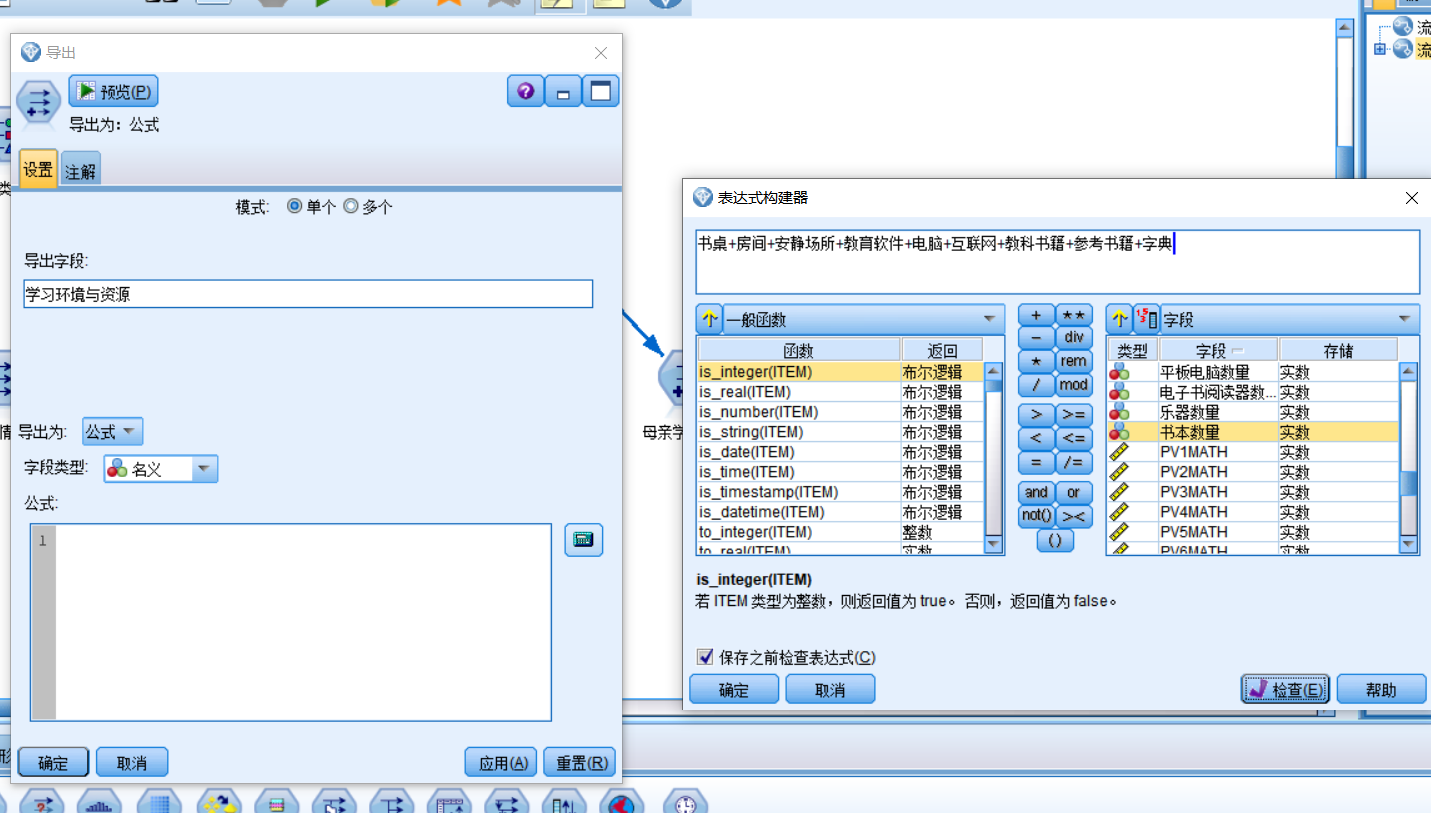
决策树分析
提炼出目标值和输入值:

建模中选择chaid。
-
五、实验结果及分析
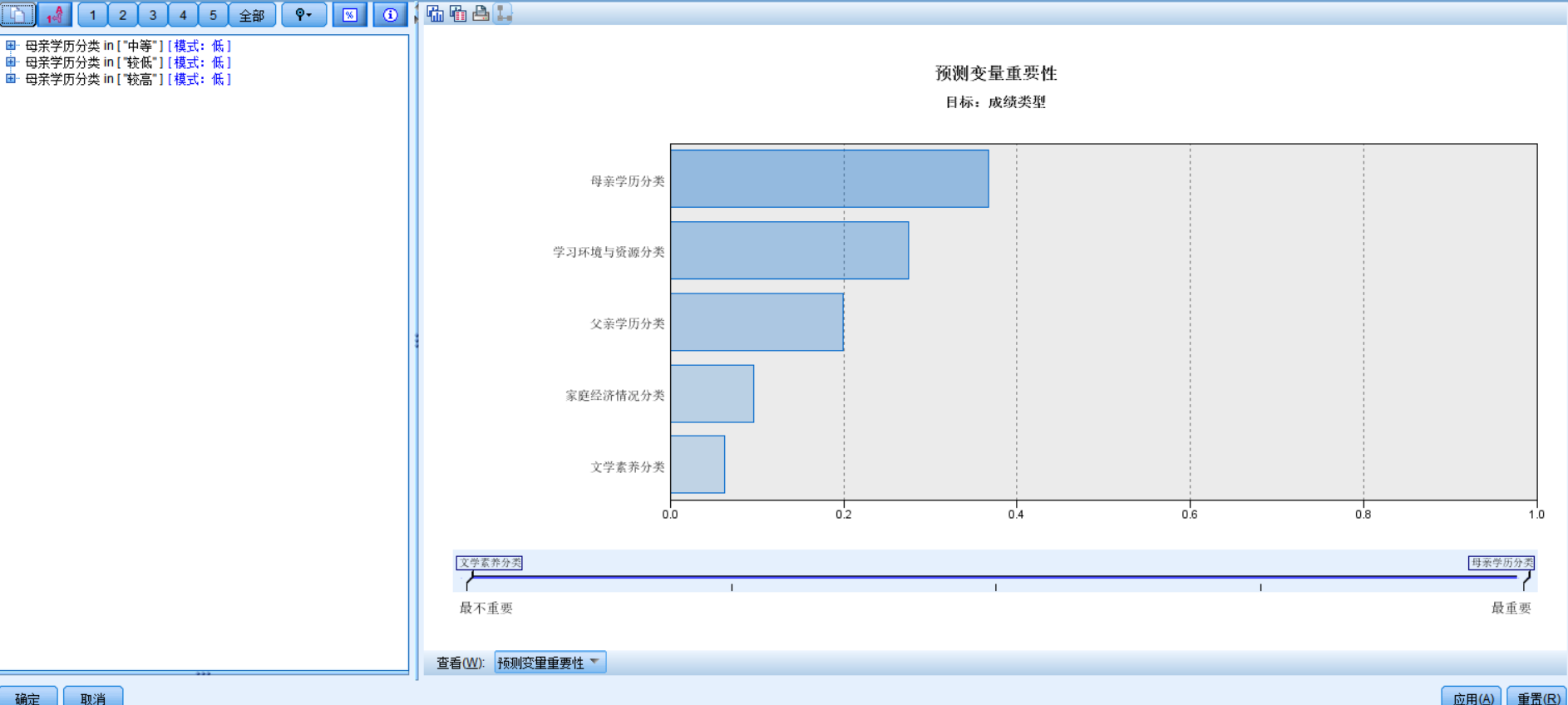
图5-1
图5-1为决策树chaid模型的重要性预测结果,图中显示,母亲学历分类的重要性最高,即母亲学历对学生成绩影响占比最大,其次是学习环境与资源、父亲学历、家庭经济情况、文学素养。
母亲学历基本无法改变,因此可以注重学生的学习环境与资源,为学生提供安静的场所进行学习以及电脑、辅助书籍等学习资源。
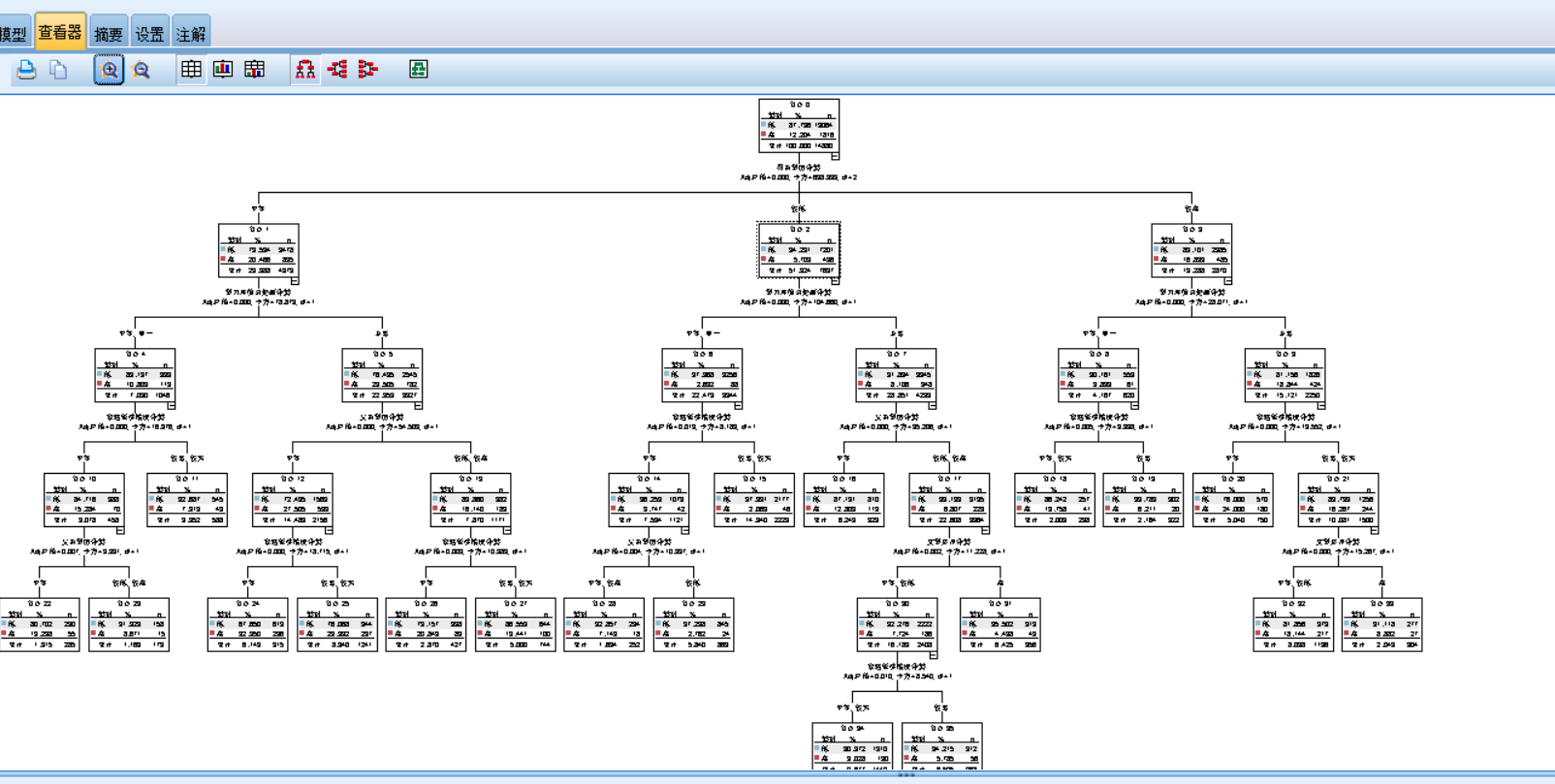
图5-2
图5-2为预测结果的树状图,根据重要性层层下分,综合每一个因素观察各因素对学生成绩的影响。

图5-3
图5-3为其中一个分支,即母亲学历中等的条件下,继续探究其他因素对学生成绩的影响。图中显示,有29.388%的学生,其母亲学历处于中等,其中,有百分之79.534%的学生成绩较低,20.466%的学生成绩较高。
即便母亲学历中等的情况,学生成绩居高的占比还是比较可观的,因此,纵使母亲学历的重要性最高,但学生仍旧可以通过自主的努力打破这类差异。
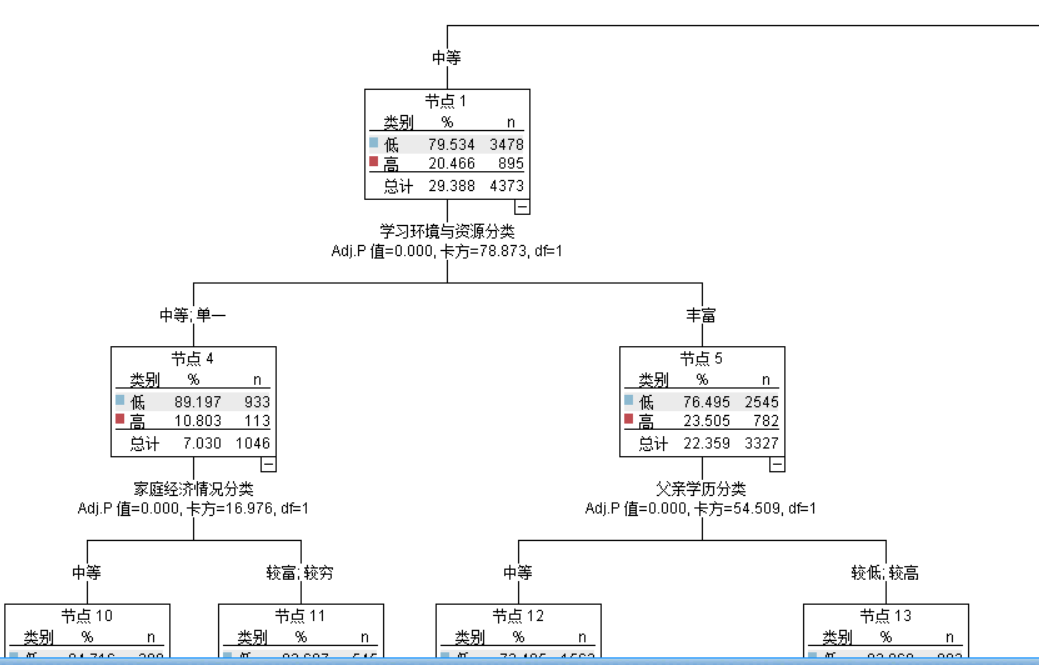
图5-4
图5-4为其中一个分支,即母亲学历中等和学习环境和资源单一的条件下,继续探究其他因素对学生成绩的影响。图中显示,有7.030%的学生,其母亲学历处于中等,学习资源与环境较为单一,可以看出与丰富的学习环境与资源相比较,学生成绩高的占比会少很多。
因此,学习环境和资源的重要性也很大,家校需要重视这一方面的影响,努力为学生打造一个良好的学习环境,并适当的提供学习资源供学生学习。
-
总结或个人反思
总结:pisa数据的决策树分析可以帮助我们理解不同因素对学生学习成绩的影响。通过分析数据,我们可以获得关于教育政策和实践的有价值的见解。也可以识别出对学生成绩影响最大的因素。通过构建一棵决策树,我们可以找到关键的决策节点,并了解哪些因素对学生表现具有重要影响。
反思:数据的质量和准确性对于决策树分析的结果至关重要。如果数据收集或输入有误,可能导致错误的决策树模型和结论。因此,在进行分析之前,应该对数据进行仔细的清洗和验证。
-
-
- 标签:
-
加入的知识群:
.jpg)

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~