-
Off-task行为预测
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
学习目标
1.了解学生产生off-task行为的原因;2.掌握感知机模型和Logistic回归模型的基本原理;3.学会使用模型分析学生产生off-task行为的相关因素;4.结合模型数据分析所得的结果从而进行教学设计的创新与改革。-
学习建议
1.建议学习课时6课时;2.课后阅读相关文献完善知识体系;3.认真完成课后思考题并与学习小组进行讨论。-
思维导图

-
4.1案例导入
在课堂上保持专注的注意力被认为是成功学习的重要因素。由于off-task行为而导致的教学时间损失被研究人员和从业者视为一项重大挑战。然而,对导致off-task行为的因素的研究很少。本章介绍了一项大规模研究的结果,该研究调查了小学生如何在课堂环境中分配注意力,以及注意力分配模式如何随着性别,年级水平和教学格式的变化而变化。研究结果表明,教学形式与小学生的课外行为有关。这些发现可以开始为制定基于研究的教学设计指南奠定基础,旨在优化课堂环境中的注意力。-
4.1.1 问题描述和定义
Off-task行为而导致的教学时间损失是教育环境中公认的问题,这一观点被研究人员(例如, Baker,2007:卡威特和斯莱文,1981年:Lee等人,1999年)和从业者(例如, Lemov,2010) 广泛认可已有一百多年的历史(参见Currio,1884年,引自柏林人,1990年)。注意力质量和表现之间的联系已经在认知心理学文献中得到证实(例如,乔杜里和戈尔曼,2000:迪克森和萨利,2007;德玛萨-德雷布洛和米勒,1988年)。还有文献记载,off-task行为对学校环境中的表现和学习成果有负面影响(有关评论,请参阅弗雷德里克和沃尔伯格,1980;古德曼,1990)。尽管之前对off-task行为进行了大量研究,但设计有效、易于实施和可扩展的干预措施以减少off-task行为一直具有挑战性。罗伯茨(2001)表明许多存在干预可能不成功,因为它们没有充分考虑导致off-task行为的条件。本研究的目的是扩展前人对小学生off-task行为的研究,以开始阐明off-task行为所涉及的因素,特别是与课堂活动相关的因素,因此具有可塑性。学校发生教学时间损失的原因有很多;这些原因包括但不限于:天气(例如,下雪天),突然被打断(例如,通过扬声器发出的通知)和特殊事件。然而,已经表明,学生的注意力不集中(即在教学时间参与off-task行为)是导致教学时间损失的最大因素(Karweit&Slavin,1981)。先前研究检查off-task行为频率的研究估计,儿童在常规教育教室中花费10%至50%的课余时间(Lee等人,1999:卡威特和斯莱文,1981)。雇用认知导师的教室报告了类似的结果,估计下任务行为占教学时间的15%至25%(例如,贝克,科贝特,&Koedinger.2004;贝克,2007)。然而,研究与off-task行为相关的因素的研究有限。最近,研究人员开始探索教室设计对儿童off-task行为的作用。Godwin和Fisher(2011)发现,与视觉环境相比,包含相对大量可视化媒介(例如图表,海报,操纵器)的课堂环境在幼儿园儿童中引发了更多的偏离任务的行为。这些设计选择被发现阻碍了儿童关注课程内容的能力,并降低了学习成果。相关发现由巴雷特等人(2012)获得。巴雷特和同事们采用了更全面的设计方法,并纳入了建筑因素(例如,物理空间,导航,家具规模等);环境元素(例如,光,声音,温度,空气质量等);以及教室装饰(例如,颜色,组织等)。Barrett等人发现,这些设计选择(与学生因素相结合)与学生后来的学业成绩有关。教学形式(例如,全班教学,小组教学等)是教学设计的另一个重要方面。然而,人们对教学形式与整体费率和任务外行为类型之间的关系知之甚少。本研究的目的是研究教学类型是否与小学生偏离任务行为的发生率有关。-
4.1.2 数据描述和分析
本研究从off-task行为的总量和偏离任务行为的形式两方面,研究了具体的教学策略是否与小学生偏离任务行为的发生率有关。为了实现这一目标,我们记录了小学生在各种教学活动(例如,全小组教学,小组工作等)中的注意力分配模式。
(1)研究对象
二十二间教室参加了本研究。参与的教室是从5所当地特许学校中选出的。招聘了五个年级:幼儿园到四年级。五个年级的分布情况如下:5间幼儿园教室、4间一年级教室、5间二年级教室、2间三年级教室和6间四年级教室。平均班级规模为21名学生(10名男生,11名女生)。然而,由于缺席,在一次观察中观察到的儿童平均人数为18.9名儿童。每次治疗观察到的儿童人数从15人到22人不等。
(2)设计和程序
在学年的后半段,每个教室被观察了四次,总共进行了84次观察。由于22间教室中的四间教室时间有限,只进行了三次观察。观察会议在两个时间段内错开(时间1:2012年2月至4月,时间2:2012年5月至6月),每个时间段内发生两次观察会议。在一个时间段内,观测会话之间的平均延迟为3.7天(延迟范围为1至14天)。跨时间段的平均延迟为73.2天。每次观察会议持续约一个小时。
(3)on-task和off-task行为的可操作化
在本研究中,集中注意力被定义为“注意力或多或少地被引导的状态。到一个目标或任务“(鲁夫和罗斯巴特,1996年,第110页)。通过视觉参与来实施集中注意力。如果孩子们将目光投向老师(或课堂助理)、教学活动或适当的教学材料,则孩子被归类为在任务。如果孩子在看别处,他们就被归类为偏离任务。眼睛凝视是视觉注意力的常见衡量标准(有关评论,请参阅亨德森和费雷拉,2004;只是&卡彭特,1976),这可以说是一个合理(尽管不完美)的集中注意力的衡量标准。
(4)编码
所有编码人员都接受了贝克-罗德里戈观察方法协议(BROMP)的培训,以使在现场设置中编码行为数据(Ocumpaugh, Bakor,&Rodrigo,2012),使用为Android手持计算机开发的软件。所有编码人员都接受了广泛的培训,包括编码录像带和现场观察会议。评分者间的可靠性是在研究之前建立的。河童值的范围从0.79到0.84。这种可靠性水平与过去的课堂研究编码脱任务行为一致,并且超过了Fleiss(1981)在现场设置中称为“优秀”的0.75阈值。
使用循环编码策略观察儿童,以减少观察者关注更突出的偏离任务行为的倾向。观察儿童的顺序在每节课开始时确定。每次观察一个孩子时,观察持续长达20秒。记录了在20秒期间观察到的第一个明确的行为。快速浏览被认为是模棱两可的行为,编码人员被指示等待明确的行为发生。如果在20秒之前注意到一个行为,则编码员继续下一个孩子,并开始一个新的20秒观察期。程序员使用周边视觉或侧视观察儿童。利用周边视觉来避免直接观察被观察的学生。这种技术使孩子不太清楚s(他)正在被观察。该程序已成功可靠地捐获了学生在先前工作中的行为,从而评估了学生的行为和影响(参见Baker等人,2006:贝克等人,2010;奥坎波等人,2012) 。
程序员将儿童的行为归类为任务或任务外。如果孩子正在看老师(或课堂助理),教学活动和/或相关的教学材料,他们被归类为任务。如果孩子在看别处,他们被归类为偏离任务。在区分任务和off-task行为时,还考虑了上下文线索(即教师指示)。例如,如果一个孩子被指示与伴侣讨论一个想法,程序员会将与另一个同伴交谈归类为任务,除非编码人员能够清楚地辨别出对话与教学任务无关。
如果孩子被归类为偏离任务,则会记录off-task行为的类型。六个相互排斥的类别记录了任务外的行为: (1) 自我分散,(2)同伴分心,(3) 环境分心,(4) 用品,(5) 走路,或(6)其他。自我分心需要与孩子自己身上的东西接触,比如一件衣服或一件附属物,以及孩子闭上眼睛的情节。同伴分心被定义为与另一个(或)在没有指示的情况下与另一个(或)学生互动或看着他们。环境干扰包括与教室中与手头任务无关的任何物体进行交互或观察,而耗材包括不恰当地使用属于指定任务的任何物体(例如,玩弄书写用具)。步行作为学生作化在教室里走来走去,当它被认为不适合这项任务时。其他干扰包括学生行为,这些行为偏离了任务,但与上述五个类别并不明显一致。第七类“未知”也包括在内,以捕捉罕见的情况,在这些情况下,不知道孩子是在执行任务还是在任务之外,并且观察者不可能或不适应为了更好地了解孩子而搬迁。当学生因各种原因(例如,使用洗手间)离开教室时,也会使用未知数。
每节课中的儿童都被视为一组不同的学生,因为不可能将四节课的观察结果联系起来。因此,共观察到1587个学生会话对。学生会话对是指编码员在特定会话中观察到的特定学生。每次会话的平均观察次数为330.13,每个儿童在一次会议内的平均观察次数为17.58。
(5)数据分析:变量
使用这些数据,我们试图在观察会话中预测每个学生的总任务或off-task行为,以及学生在任务外时倾向于参与的行为类型。考虑将两类预测变量纳 入模型:学生特征和教学设计。性别和年级被列为学生特征。与教学设计相关的预测变量包括每种课堂教学格式的比例和变量教学格式的转换/持续时间。
教学格式作为预测变量包括在内,以检查某些教学格式是否引发不同数量的非任务行为。六种不同的教学形式被编码: (1) 个人工作,(2) 小组或合作伙伴工作,(3)全组教学在办公桌上,(4) 坐在地毯上的全组教学,(5) 跳舞,(6)测试。计算了学生在上述每种格式中花费的时间比例。表1提供了每种教学格式的平均持续时间。
每当老师暂停教学以从一项活动切换到另一项活动时(例如,从处理数学问题过渡到听短篇小说),都会注意到过渡。在许多情况下,转换与改变教学形式(例如,从全组指令切换到小组指令) ;然而,情况并非总是如此,因为过渡可以在不改变教学格式的情况下发生(例如,儿童从一个小组活动轮换到另一个小组活动)。过渡经常通过老师要求孩子们拿出新的教学材料(例如,“请拿出你的数学活页夹”)或要求学生改变位置(例如,“请把你的笔记本收起来,走到地毯上”)来标记过渡。
-
4.2 感知机模型
近年来,机器学习在各个领域发挥出了出色的表现,在自然语言处理,图像识别,推荐系统 等领域都发挥了巨大的作用,成为了当前十分热门的一个学科领域。机器学习的整体思路是定义一个有效的目标模型和一个可以衡量目标模型优劣程度的损失函数,通过对数据的学习一步步地优化目标模型使得损失最小的方式来求出最优模型,最终可以利用这个目标模型来完成各种任务。感知机是机器学习算法中第一个具有重要学术意义的基础算法,它具有运算简单,收敛速度快,具有实用价值等特点,是机器学习领域重要的算法之一,同时也是著名的机器学习算法支持向量机(SVM)的基础。
20 世纪 50 年代,美国神经学家 Frank Rosenblatt 提出了可以模拟人类感知能力的机器,并称之为“感知机”,感知机算法随之诞生。感知机算法是一个基本的二分类机器学习算法,该算法原理为:找出一个 n 维分离超平面可以基本将训练集特征空间中所有样本点分为正负两类,该平面即对应一个感知机模型,从而利用该模型对新样本进行分类。
感知机模型是二分类模型且线性可分,它的目标是通过训练数据训练出能够将数据进行线性二分类的分离超平面。
(1)二分类:个体均可被分为两个类别,比如每个人按照生物学性别可分为男和女,通常将其中一个类别作为正类,用1表示,将另一个作为负类,用-1表示。一般将更加关注的类别作为正类。
(2)线性可分:可以用超平面将不同的样本完全分开。
(3)分离超平面:超平面是指n维线性空间中维度为n-1的子空间,分离超平面是一个可以把线性空间分割成不相交的两部分的超平面。对于二维和三维空间来说,该平面即分别为一条线和一个面,对于四维空间来说为一个体,对于五维空间,是一个四维几何结构。
感知机模型的决策函数:
y=sigh(w·x+b)
w 叫做权值(weight)或权值向量, w(w1,w2,w3,…,wn),来表示各个输入对于输出的重要程度,b叫做偏置 (bias) 用来调整整体结果和阈值之间的关系。sign 为符号函数,取 +1 或 -1;sigh(m) 为符合函数,当 m>0 时, sigh(m)=+1;当 m<0 时,sigh(m)=-1。

-
4.2.1感知机学习策略
在数据集线性可分的前提下,感知机的学习目标是通过已知数据训练出一个超平面, 这个超平面需要具有如下特性:能够将训练集中的两类样本点完全正确分类。为了找到这个超平面,即确定感知机模型参数 w,b,需要确定一个学习策略,即定义一个损失函数,来衡量目标模型的优劣,损失函数极小化的过程就是目标模型优化的过程。所以求解目标模型,就可以转换为求解损失函数的最小值。如何定义损失函数?一个自然选择是误分类点的总数,通过误分类点的综述来衡量当前感知机模型的优劣,但是这样的损失函数存在一个严重的问题:对于数据量较小的训练集,我们可以通过这样损失函数找到目标模型,但是当数据集的数据量较大时,我们需要通过计算来求出当前损失函数的最小值,而此时的损失函数关于 w,b 不是连续可导函数,这样会严重影响我们求出损失函数最小值的效率。所以感知机的损失函数采用另一种形式来定义:计算所有点到超平面的总距离,这样当损失函数为最小值时,意味着所有样本点分类正确,此时损失函数的参数 <w,b> 即为目标模型的参数 <w,b>。感知机 f(x)=sign(w.x+b) 模型的损失函数定义为:L(w,b) = -∑yi(w*xi+b)<xi,yi> 为 第 i 组 数 据 的 输 入 和 输 出,(w*xi+b) 是根据当前模型对 x 做出的预测值,yi 是对应于 xi 的真实值,当一个样本被分类正确时(即取阈值为 0 时,预测值和真实值都大于 0 或者都小于 0),它的输出是负值,分类错误时,输出值是正值,即损失函数的最小值意味着最多的正确分类点。首先我们需要初始化一组参数< w0,b0>,即初始化一个超平面,然后通过梯度下降法不断地极小化目标函数,即对损失函数 L(w,b) = -∑yi(w*xi+b) 分别对 w,b 求偏导,以求出损失函数最小值。 随机选取一个误分类点 (xi,yi),对 w 和 b 进行更新:w←w+ηyi xib←b+ηyi其中 η 是步长,又称为学习速率,用来控制 w 和 b 更新幅度的大小,η 越大,需要更新的次数越少,但是可能跨过最小值,倒置反复更新,而 η 越小,则需要更新的次数越多,所以选取适当的 η 也是一个重要的环节。这种学习策略可以理解为当一个样本点被错误分类时,则更新 w 和 b 的值,直到该样本点被正确分类。如此循环,直至所有的样本点都被正确分类。
随机选取一个误分类点 (xi,yi),对 w 和 b 进行更新:w←w+ηyi xib←b+ηyi其中 η 是步长,又称为学习速率,用来控制 w 和 b 更新幅度的大小,η 越大,需要更新的次数越少,但是可能跨过最小值,倒置反复更新,而 η 越小,则需要更新的次数越多,所以选取适当的 η 也是一个重要的环节。这种学习策略可以理解为当一个样本点被错误分类时,则更新 w 和 b 的值,直到该样本点被正确分类。如此循环,直至所有的样本点都被正确分类。
-
4.2.2感知机算法实现
可以知道,感知机的学习目的是求得一个能将训练集正实例点和负实例点完全分开的分离超平面。要寻找到这么一个超平面,其实就是找合适的w和b,我们采用的是损失函数,同时将损失函数极小化的方法。
对于损失函数的选择,采用误分类点到超平面的距离,二维上:点到直线的距离。-
4.3 Logistic回归模型分析
一、概述Logistic回归又称Logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。Logistic回归几乎已经成了流行病学和医学中最常用的分析方法,现有文献对于Logistic回归模型的应用也多数集中在临床医学肿瘤的恶性良性分类、财务分析或体育活动等领域。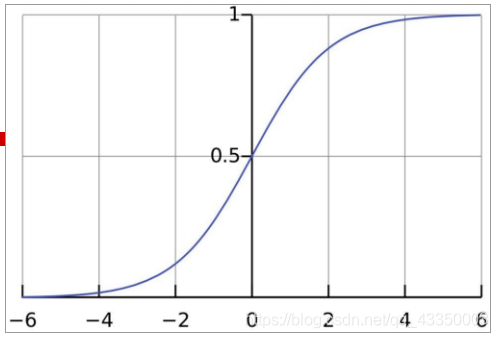 Logistic回归分析实质就是发生概率除以没有发生概率再取对数。就是这个不太繁琐的变换改变了取值区间的矛盾和因变量自变量间的曲线关系。究其原因,是发生和未发生的概率成为了比值,这个比值就是一个缓冲,将取值范围扩大,再进行对数变换,整个因变量改变。不仅如此,这种变换往往使得因变量和自变量之间呈线性关系,这是根据大量实践而总结。所以,Logistic回归从根本上解决因变量要不是连续变量怎么办的问题。二、逻辑回归的工作原理逻辑回归的工作原理是测量因变量,即我们想要预测的变量和一个或多个自变量之间的关系。它通过在其底层逻辑函数的帮助下,估计概率来做到这一点。逻辑回归中的关键术语有:1.变量:任何可以测量或技术的数字、特征或数量。比如年龄、速度、性别。2.系数:一个数字通常是一个整数乘以它所伴随的变量。例如12x,数字12就是系数。3.Exp:指数的缩写形式。4.异常值:与其他数据点显着不同的数据点。5.估计器:生成参数估计值的算法或公式。6.卡方检验:是一种检验数据是否符合预期的假设检验方法7.标准误差:统计样本总体的近似标准偏差。8.正则化:一种通过在训练数据集上你和函数来减少误差和过拟合的方法。9.多重共线性:两个或多个自变量之间存在相关性。10.拟合优度:描述统计模型与一组观测值的拟合程度。11.优势比:红娘,两个事件之间关联强度的指标。12.对数似然函数:评估统计模型的拟合优度。13.Hosmer-Lemeshow检验:评估观察到的事件发生率是否与预期事件发生率匹配的检验。(三)逻辑回归的应用情形应用逻辑回归来预测分类因变量,换句话说,当预测是分类的时候使用它,例如是或否,真或假,0或1。逻辑回归的预测概率或输出可以是其中之一,没有中立立场。对于预测变量,他们可以是以下任何类别的一部分:1.连续数据:可以在无线尺度上测量的数据。他可以取两个数字之间的任何职例,如以磅为单位的重量,或以华氏度为单位的温度。2.离散的名义数据:适合命名类别的数据。一个简单的例子是头发颜色:金色、黑色或棕色。3.离散、有序的数据:符合某种规模顺序的数据,例如以1到5的等级说明您对产品或服务的满意程度。简而言之,通过查看历史数据逻辑回归可以预测:电子邮件是垃圾邮件,肿瘤是致命的,促销电子邮件接收者是回复者还是回复者。本质上,逻辑回归有助于解决概率和分类问题,换句话说,您只能期望逻辑回归的分类和概率结果。例如,它可用于确定某事真货假的概率,也可用于在是或否等两个结果之间做出决定,如果观察数少于特征数,则不应使用逻辑回归,否则可能会导致过拟合。(四)线性回归与逻辑回归逻辑回归预测,一个或多个自变量的分类变量,而线性回归预测,连续变量,换句话说,逻辑回归提供恒定输出,而线性回归提供连续输出。由于线性回归中的结果是连续的,因此结果有无限可能的值?但是对于逻辑回归可能的结果值数量是有限的。逻辑回归和线性回归都是监督机器学习算法和回归分析的两种主要类型,逻辑回归用于解决分类问题,而线性回归主要用于回归问题,线性回归和逻辑回归可以预测不同的东西,逻辑回归可以帮助预测学生是否通过考试,而线性回归可以预测学生的分数。(五)逻辑回归的类型逻辑回归可以根据结果的数量或因变量的类别分为不同的类型,一般的逻辑回归指的是二元逻辑回归。1.二元逻辑回归二元逻辑回归是一种用预测因变量和自变量之间关系的统计方法,在这种方法中,因变量是一个二元变量,这意味着他只能取两个值,例如是或否、真或假、成功或失败、0或1等。二元逻辑回归的一个简单示例是确定电子邮件是否为垃圾邮件。2.多项逻辑回归多项逻辑回归是二元逻辑回归的扩展,它允许超过两类结果或因变量。它类似于二元逻辑回归,但可以有两个以上的可能,结果这意味着结果变量可以有三种或更多可能的无序类型,例如因变量可以表A类、B类和C类。幼儿园逻辑回归类似多项逻辑回归也使用最大似然估计来确定概率。例如,多项逻辑回归可用于研究一个人的教育和职业选择之间的关系。在这里,职业选择将是由不同职业类别组成的因变量。3.有序逻辑回归序数逻辑回归也称为序数回归,是二元逻辑回归的另一种扩展,它用于预测具有三种或更多可能性的有序类型的,因变量具有数量意义的类型,例如因变量可以表示非常不同意,不同意,同意或非常同意。可用于确定工作绩效或工作满意度。
Logistic回归分析实质就是发生概率除以没有发生概率再取对数。就是这个不太繁琐的变换改变了取值区间的矛盾和因变量自变量间的曲线关系。究其原因,是发生和未发生的概率成为了比值,这个比值就是一个缓冲,将取值范围扩大,再进行对数变换,整个因变量改变。不仅如此,这种变换往往使得因变量和自变量之间呈线性关系,这是根据大量实践而总结。所以,Logistic回归从根本上解决因变量要不是连续变量怎么办的问题。二、逻辑回归的工作原理逻辑回归的工作原理是测量因变量,即我们想要预测的变量和一个或多个自变量之间的关系。它通过在其底层逻辑函数的帮助下,估计概率来做到这一点。逻辑回归中的关键术语有:1.变量:任何可以测量或技术的数字、特征或数量。比如年龄、速度、性别。2.系数:一个数字通常是一个整数乘以它所伴随的变量。例如12x,数字12就是系数。3.Exp:指数的缩写形式。4.异常值:与其他数据点显着不同的数据点。5.估计器:生成参数估计值的算法或公式。6.卡方检验:是一种检验数据是否符合预期的假设检验方法7.标准误差:统计样本总体的近似标准偏差。8.正则化:一种通过在训练数据集上你和函数来减少误差和过拟合的方法。9.多重共线性:两个或多个自变量之间存在相关性。10.拟合优度:描述统计模型与一组观测值的拟合程度。11.优势比:红娘,两个事件之间关联强度的指标。12.对数似然函数:评估统计模型的拟合优度。13.Hosmer-Lemeshow检验:评估观察到的事件发生率是否与预期事件发生率匹配的检验。(三)逻辑回归的应用情形应用逻辑回归来预测分类因变量,换句话说,当预测是分类的时候使用它,例如是或否,真或假,0或1。逻辑回归的预测概率或输出可以是其中之一,没有中立立场。对于预测变量,他们可以是以下任何类别的一部分:1.连续数据:可以在无线尺度上测量的数据。他可以取两个数字之间的任何职例,如以磅为单位的重量,或以华氏度为单位的温度。2.离散的名义数据:适合命名类别的数据。一个简单的例子是头发颜色:金色、黑色或棕色。3.离散、有序的数据:符合某种规模顺序的数据,例如以1到5的等级说明您对产品或服务的满意程度。简而言之,通过查看历史数据逻辑回归可以预测:电子邮件是垃圾邮件,肿瘤是致命的,促销电子邮件接收者是回复者还是回复者。本质上,逻辑回归有助于解决概率和分类问题,换句话说,您只能期望逻辑回归的分类和概率结果。例如,它可用于确定某事真货假的概率,也可用于在是或否等两个结果之间做出决定,如果观察数少于特征数,则不应使用逻辑回归,否则可能会导致过拟合。(四)线性回归与逻辑回归逻辑回归预测,一个或多个自变量的分类变量,而线性回归预测,连续变量,换句话说,逻辑回归提供恒定输出,而线性回归提供连续输出。由于线性回归中的结果是连续的,因此结果有无限可能的值?但是对于逻辑回归可能的结果值数量是有限的。逻辑回归和线性回归都是监督机器学习算法和回归分析的两种主要类型,逻辑回归用于解决分类问题,而线性回归主要用于回归问题,线性回归和逻辑回归可以预测不同的东西,逻辑回归可以帮助预测学生是否通过考试,而线性回归可以预测学生的分数。(五)逻辑回归的类型逻辑回归可以根据结果的数量或因变量的类别分为不同的类型,一般的逻辑回归指的是二元逻辑回归。1.二元逻辑回归二元逻辑回归是一种用预测因变量和自变量之间关系的统计方法,在这种方法中,因变量是一个二元变量,这意味着他只能取两个值,例如是或否、真或假、成功或失败、0或1等。二元逻辑回归的一个简单示例是确定电子邮件是否为垃圾邮件。2.多项逻辑回归多项逻辑回归是二元逻辑回归的扩展,它允许超过两类结果或因变量。它类似于二元逻辑回归,但可以有两个以上的可能,结果这意味着结果变量可以有三种或更多可能的无序类型,例如因变量可以表A类、B类和C类。幼儿园逻辑回归类似多项逻辑回归也使用最大似然估计来确定概率。例如,多项逻辑回归可用于研究一个人的教育和职业选择之间的关系。在这里,职业选择将是由不同职业类别组成的因变量。3.有序逻辑回归序数逻辑回归也称为序数回归,是二元逻辑回归的另一种扩展,它用于预测具有三种或更多可能性的有序类型的,因变量具有数量意义的类型,例如因变量可以表示非常不同意,不同意,同意或非常同意。可用于确定工作绩效或工作满意度。-
4.3.1 logistic回归算法原理
逻辑回归算法是大数据中常用的数据分析方法之一,它具有模型简单、训练速度快等特点,在产业技术中有着广泛的应用。数据集大小逻辑回归和深度学习模型预测性能的影响。逻辑回归模型不仅本身具有很高的预测精度,同时便于理解,符合监管对可解释性的要求。该模型的许多前提假设比较符合经济现实和金融数据的分布规律,譬如它不要求模型变量间具有线性的相关关系,不要求变量服从协方差矩阵相等和残差服从正态分布等,这使得模型的适用性和灵活性都很好。建立模型可选用的方法非常多,如区别分析、线性回归、逻辑回归及分类树等统计方法,或是人工神经网络、基因演算法及专家系统等非统计方法。本文采用逻辑回归的方法来建立数据驱动的评分模型。如表 1 所示。通常,逻辑回归可以用于一个名义或顺序因变量的建模。首先,假设有 n 个包含违约状态变量 y 的观测值。违约状态变量 y 有两种取值:0 表示正常事件,1 表示违约事件。同时,假设收集到r个预测变量,或自变量,也被称为协变量,x1,…,xr。第 i 个观测值的自变量和因变量的取值分别表示为xi1,…,xir 和 yi。具体符号详见表 1: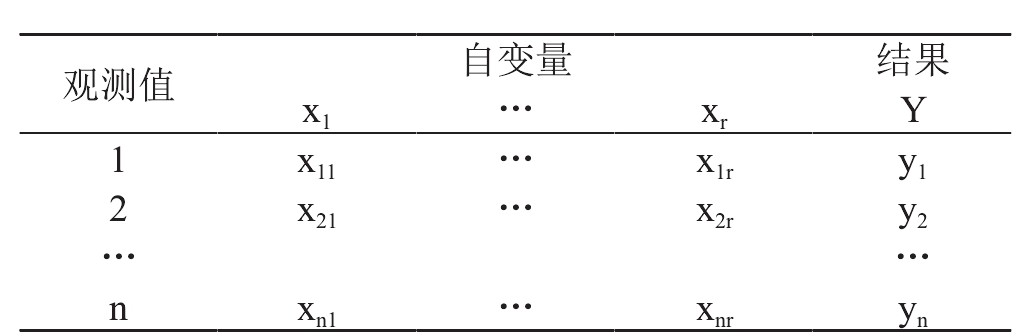 用逻辑回归模型计算事件(y=1)的概率为:
用逻辑回归模型计算事件(y=1)的概率为: 常数 β0,β1,…,βr 称为模型参数。第一个常数 β0 称为截距项。同时将自变量x和模型参数β定义为r+1维的向量,如下:xT=[1 x1 … xr] 和 βT=[β0 β1 … βr]结合上述两个向量,则概率公式可以重新整理为:
常数 β0,β1,…,βr 称为模型参数。第一个常数 β0 称为截距项。同时将自变量x和模型参数β定义为r+1维的向量,如下:xT=[1 x1 … xr] 和 βT=[β0 β1 … βr]结合上述两个向量,则概率公式可以重新整理为: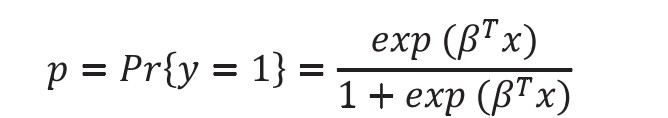 也可以写成另外一种替代形式:
也可以写成另外一种替代形式:
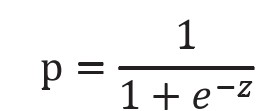 对概率公式进行简单的转换,可以得到:
对概率公式进行简单的转换,可以得到: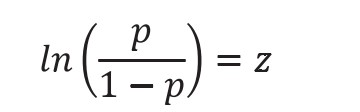 上式左边的转换式被称为 logit 函数。需要注意的是,p是违约的概率,而 (1-p) 是正常的概率。比例 p/(1-p) 被称为比率,即违约事件概率与正常事件概率的比值。因此,logit 函数仅仅是比率的自然对数。而逻辑回归模型是用比率的对数作为因变量的线性回归模型。用给定数据拟合逻辑回归模型,首先从似然函数和似然方程开始。最大似然法则(ML)通过构建一个代表从建议的模型得到的数据的似然值而发生作用。然后,如果给定的参数数据最大化了似然函数的值,则该法认为得到了最优模型。逻辑回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,此次模型开发的因变量就是二分类的(好 / 坏账户)。逻辑回归对自变量类型一般不做规定,但它要求自变量与因变量的逻辑转换之间应符合线性关系。当自变量为分类变量时,可不必考虑线性关系,但当自变量为连续型变量时,则需要检验二者之间的线性关系是否成立。如果不成立,应进行相应的变量变换,如对数变换、指数变换、多项式变换等,使其以恰当的形式进入模型。由于此次开发采用分箱型模型的方法,所有的自变量属于分类变量,所以不需要检验线性关系。模型最终变量需要进行检测,包括业务逻辑检查、稳定性检查、回归结果检查、评估方差膨胀系数和变量特征分析。上面描述的几种统计测试便是判断在最终模型中,变量是否被包括或被排除的基础。因此,如果要对学生的走神行为进行分析,可以将Logistic回归分成两种任务情况,也就是二元分类问题:非此即彼,即走神与集中。首先确定研究对象→选择调查工具→进行数据分析→得出结论。暂时的设想流程是:可以以班级为单位,设置对照组,两个班级学生,收集并整理分析两组人群上课时不同的神态与学习方式等。自变量既可以是连续的,也可以是分类的。最后通logistic回归分析,可以得到自变量的权重,但是我们通过假设函数计算的输出值即可不可能只有0或1两个情况,很显然,根本没有连续函数能达到这个功能,所以在输出值有一段连续值得情况下,可以设置一个阈值:如果h0(x)≥0.5,那么我们预测y=1,则更倾向于学生走神;如果h0(x)<0.5,我们预测y=0,则更倾向于学生没有走神。
上式左边的转换式被称为 logit 函数。需要注意的是,p是违约的概率,而 (1-p) 是正常的概率。比例 p/(1-p) 被称为比率,即违约事件概率与正常事件概率的比值。因此,logit 函数仅仅是比率的自然对数。而逻辑回归模型是用比率的对数作为因变量的线性回归模型。用给定数据拟合逻辑回归模型,首先从似然函数和似然方程开始。最大似然法则(ML)通过构建一个代表从建议的模型得到的数据的似然值而发生作用。然后,如果给定的参数数据最大化了似然函数的值,则该法认为得到了最优模型。逻辑回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,此次模型开发的因变量就是二分类的(好 / 坏账户)。逻辑回归对自变量类型一般不做规定,但它要求自变量与因变量的逻辑转换之间应符合线性关系。当自变量为分类变量时,可不必考虑线性关系,但当自变量为连续型变量时,则需要检验二者之间的线性关系是否成立。如果不成立,应进行相应的变量变换,如对数变换、指数变换、多项式变换等,使其以恰当的形式进入模型。由于此次开发采用分箱型模型的方法,所有的自变量属于分类变量,所以不需要检验线性关系。模型最终变量需要进行检测,包括业务逻辑检查、稳定性检查、回归结果检查、评估方差膨胀系数和变量特征分析。上面描述的几种统计测试便是判断在最终模型中,变量是否被包括或被排除的基础。因此,如果要对学生的走神行为进行分析,可以将Logistic回归分成两种任务情况,也就是二元分类问题:非此即彼,即走神与集中。首先确定研究对象→选择调查工具→进行数据分析→得出结论。暂时的设想流程是:可以以班级为单位,设置对照组,两个班级学生,收集并整理分析两组人群上课时不同的神态与学习方式等。自变量既可以是连续的,也可以是分类的。最后通logistic回归分析,可以得到自变量的权重,但是我们通过假设函数计算的输出值即可不可能只有0或1两个情况,很显然,根本没有连续函数能达到这个功能,所以在输出值有一段连续值得情况下,可以设置一个阈值:如果h0(x)≥0.5,那么我们预测y=1,则更倾向于学生走神;如果h0(x)<0.5,我们预测y=0,则更倾向于学生没有走神。-
4.3.2 Logistic回归模型算法实现步骤
因此,如果要对学生的off-task行为进行分析,可以将Logistic回归分成两种任务情况,也就是二元分类问题:非此即彼,即off-task行为与on-task行为。首先归纳整理→选择工具→编码→进行数据分析→得出结论。
1. 归纳整理
本研究归纳整理了二十二间教室五个年级:幼儿园到四年级。五个年级的分布情况如下:5间幼儿园教室、4间一年级教室、5间二年级教室、2间三年级教室和6间四年级教室。平均班级规模为21名学生(10名男生,11名女生)。然而,由于实际情况影响,在其进行的84次观察里。每次观察到的儿童平均人数为18.9名。
2. 选择工具
所有编码人员都接受了贝克-罗德里戈观察方法协议(BROMP)的培训,评分者间的可靠性是在研究之前建立的。使用循环编码策略观察学生。使用工具包括观察工具(手机、录像机)、记录工具(会议记录表)、编码以及Logistic回归模型。需要注意的是,每次观察一个孩子时,观察持续长达20秒。编码人员被指示等待并记录在20秒期间观察到的第一个明确的行为,如果在20秒之前注意到一个行为,则编码员继续下一个孩子,并开始一个新的20秒观察期。在此期间编码人员使用周边视觉或侧视观察儿童,利用这种方式避免直接观察被观察的学生。这种技术使孩子不太清楚自己是否正在被观察,有效保证观察的准确性。(Baker等人,2006:贝克等人,2010;奥坎波等人,2012)。
3. 编码
程序员将儿童的行为归类为on-task行为或off-task行为。如果孩子正在看老师(或课堂助理),教学活动和/或相关的教学材料,他们被归类为on-task行为。如果孩子在看别处或超过10s视线未转动,他们被归类为off-task行为。在区分on-task行为和off-task行为时,还需要考虑教师的指示等因素。例如,如果一个孩子被指示与伴侣讨论一个想法,程序员会将与另一个同伴交谈归类为on-task行为,除非编码人员能够清楚地辨别出对话与教学任务无关。
如果孩子被归类为off-task行为,则会记录下off-task行为的类型。六个相互排斥的类别记录了任务外的行为:
(a)自我分心:需要孩子与自己的东西接触,比如一件衣服或一件附属物,以及孩子闭上眼睛的情节;
(b)打扰同伴:被定义为与另一个(或)在没有指示的情况下与另一个(或)学生互动或看着他们;
(c)乱写乱画:学生在教学材料或书桌上随意涂抹的行为;
(d)摆弄物品:不恰当地使用属于指定任务的任何物体,例如玩弄书写用具等;
(e)走动:当学生因各种原因(例如,使用洗手间)离开教室或者在教室里走来走去(极少发生);
(f)其他:与上述五个类别并不明显一致。
每节课中的儿童都被视为一组不同的学生,因为不可能将四节课的观察结果联系起来。因此,共观察到1587个学生会话对。学生会话对是指编码员在特定会话中观察到的特定学生。每次会话的平均观察次数为330.13,每个儿童在一次会议内的平均观察次数为17.58。
4. 数据分析
(1)建模过程
·对特征进行再次筛选
·训练筛选特征的函数
·筛选出好的特征
·用筛选后的特征训练模型
·选出最高模型正确率。
(2)数据处理
因变量Y只能包括数字0和1,如果因变量的原始数据不是这样,那么就需要数据编码,设置成0和1,使用SPSSAU“数据处理”-“数据编码”功能,操作如下图:

(3)SPSSAU上传数据
·登录账号后进入SPSSAU页面,点击右上角“上传数据”,将处理好的数据进行“点击上传文件”上传即可。

(4)拖拽分析项
在“进阶方法”模块中选择“二元Logit”方法,将Y定类变量放于上方分析框内,X定类/定量变量放于下方分析框内,点击“开始分析”即可。
-
章节小结
本研究是首次大规模研究小学生的off-task行为,旨在研究教学设计特征与课题行为发生率之间的关系。具体而言,我们研究了教学格式的类型(例如,个人工作,小组工作,整个小组工作等)和可变的教学格式的过渡/持续时间是否与off-task行为的整体速率有关。我们的研究结果表明,这两个变量都与儿童参与教学活动。与此同时,儿童的性别和年级(K-4)在以下方面的贡献微乎其微。一旦考虑到教学设计的特征(例如,教学格式和可变的转换/教学格式的持续时间),就会产生off-task行为。报告的结果还表明,某些类型的教学格式比其他类型与更多的任务行为相关,尽管需要进一步的研究来解释这一发现。有几种可能的假设可以探索。一个潜在的潜在因素是教师监督的差异。对于某些教学形式(例如,小组工作),课堂管理比其他形式(例如,在办公桌上进行全组教学)吏容易。因此,教师更容易监督的教学形式可能会导致学生off-task的机会减少。其次,学生对教学任务的参与也可能因教学形式而异。例如,单独或在学生课桌上进行的教学活动(即在课桌上进行的全团体教学)可能比小组活动更具吸引力或激励性,而小组活动往往更注重社会导向,并包括更多的动手学习部分。更具激励性的教学活动反过来可能会增加学生的完成任务行为。此外,教学时间因这些格式而异。因此,当教学由小块教学活动与在较长时间内发生的教学活动组成时,儿童可能能够更好地保持集中注意力的状态(参见Ruff& Lawson,1990;萨里德和布雷兹尼茨,1997)。目前,这些假设是推测性的,需要进一步调查以确定其可行性。如前所述,off-task行为在教育环境中是一个重大问题,因为它被认为会阻碍学习。优化教学设计以促进任务行为是一个理想的目标:然而,将教学设计选择与课堂环境中的注意力分配。目前的研究结果是提供经验证据以指导教学设计的第一步。-
参考文献
[1] GOdwin, Karrie .Classroom activities and off-task behavior in elementary school children[J].Cognitive Science 2013(35): 2428-2433.
[2]田甜.小学生课堂走神行为分析及改善策略研究[D].四川师范大学,2021: 1-4.
[3]徐芳,廖婷,陈冠杏,朱宗顺.特殊儿童不专注行为的功能性评估研究综述[J].现代特殊教育,2016(24):3-9.
[4]Moore D W, Anderson A, Glassenbury M, et al.Increasing On-Task Behavior in Students in a Regular Classroom: Effectiveness of a Self-Management Procedure Using a Tactile Prompt[J].Journal of Behavioral Education, 2013 (4) : 302-311.
[5]唐婷,黎明.大数据环境下的逻辑回归算法分析与研究[J].电子技术与软件工程,2022(17):178-181.
[6] GOdwin, Karrie .Classroom activities and off-task behavior in elementary school children[J].Cognitive Science 35 (2013): 2428-2433.
[7]Barbara Addy Holtz,Elyse Brauch Lehman. Development of Children's Knowledge and Use of Strategies for Self-Control in a Resistance-to-Distraction Task[J]. Merrill-Palmer Quarterly (1982-),1995,41(3).
[8]卢雪梅. 中学生课堂走神问卷编制及其初步应用[D].天津师范大学,2020: 2-9,27.
[9]Holdtz, Barbara Addy and Elyse Brauch Lehman. Development of Children's Knowledge and Use of Strategies for Self-Control in a Resistance-to-Distraction Task.” Merrill-palmer Quarterly 41 (1995): 361-380.
[10] Karrie E. Godwin, Ma. V. Almeda, Off-task behavior in elementary school children,Learning and Instruction 44 , (2016): 128-143.
-
思考题
1、学完本章,思考并总结影响学生产生off-task行为的因素。2、作为一名新时代的人民教师,你将在采取什么样的教学措施以降低学生产生off-task行为的机率。 -
-
- 标签:
- 人工智能教育应用
- 走神行为预测
- 机器学习
-
加入的知识群:

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~