-
PISA数据的决策树分析
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
PISA数据的决策树分析(张亦瑄)


教育数据挖掘方法与应用实验报告
姓名
张亦瑄
学号
202105720433
年级
2021级
专业
教育技术学(师范)
学院
教育科学与技术学院
实验二:pisa数据的决策树分析
-
一、实验目的
pisa数据的决策树分析实验探索影响学生学业表现的关键因素,为教育政策制定者和学校提供有针对性的改进建议。通过构建决策树模型,我们的目标是识别哪些个体特征、家庭背景和学习环境因素与学生数学成绩之间存在关联。具体实验目的包括:
识别关键因素:通过分析pisa数据,我们希望确定对学生数学成绩产生最大影响的变量和因素,以便针对性地改进教育策略和资源分配。
制定干预策略:通过生成决策树规则,我们可以识别哪些学生群体更容易在数学考试中表现不佳。这有助于制定个性化的教育干预措施,提高学生的学术成绩。
了解变量重要性:实验还旨在评估不同变量的重要性,以便决策者更好地了解哪些因素最值得关注和改进。
通过这一实验,我们可以深入了解pisa数据集中的信息,为改善学生的教育体验和成绩提供实际指导,并为教育政策的制定提供有力支持。
-
二、实验工具
ibmspss modeler
-
三、实验原理
决策树分析是一种常用于数据挖掘和机器学习的技术,用于解决分类和回归问题。pisa数据可以用于分析教育和学生表现方面的问题。下面是决策树分析的实验原理:
决策树的工作原理是通过递归地将数据集划分为更小的子集,直到每个子集能够被明确地分类,或者达到停止划分的条件。这个过程会形成一个决策树,每个内部节点代表一个特征的测试,每个分支代表一个可能的测试结果,每个叶节点代表一个类别的预测。
在本实验中,我们将使用pisa数据集,这是一个全球性的学生能力评估项目,提供了大量关于学生、学校和家庭背景的信息。通过决策树分析,我们可以深入探索哪些个体特征、家庭背景和学习环境因素与学生数学成绩之间存在关联。
-
四、实验步骤
c5.0 决策树算法
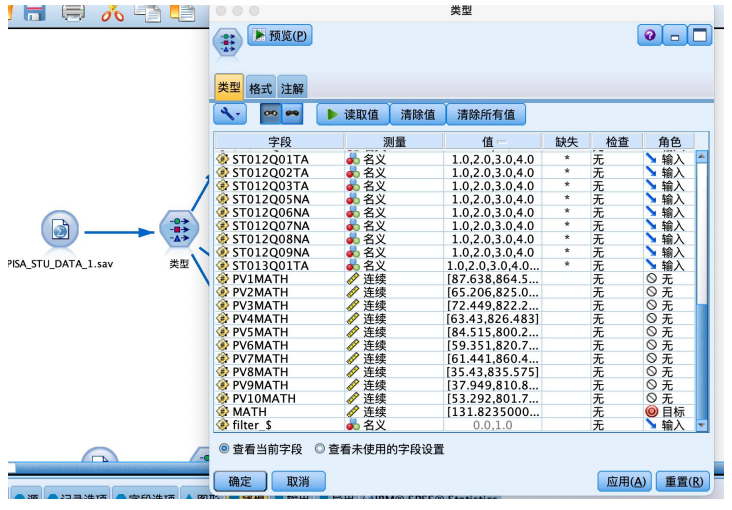
从“源”中拖拽出“statistics 文件”到数据流编辑区,并编辑数据,从“字段选项”选项卡中拖拽“类型”节点到数据流编辑区,建立连接,建立好如图数据流,并编辑“类型”节点,执行“读取值”操作,并将“math”字段的角色设置为“目标”,其余字段设置为“输入”。
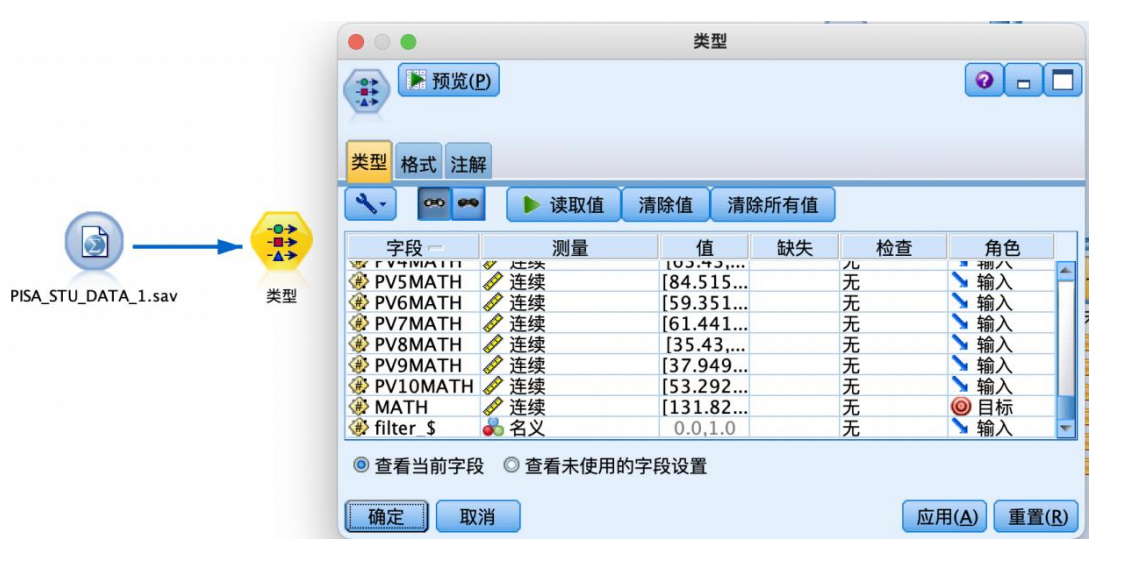
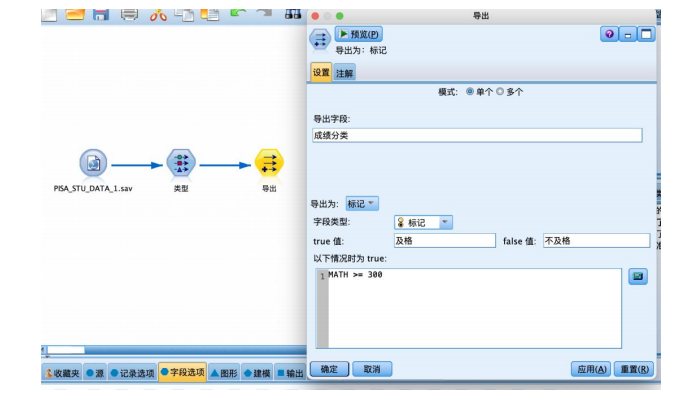
从“字段选项”选项卡中拖拽“导出”节点到数据流编辑区,并与“类型”节点相连接。如图所示右键编辑“导出”节点参数,将数值型“math”字段变换为标记型字段,命名为“成绩分类”,设置公式“math >= 300”,true 值对应“及格”,false 值对应“不及格”,设置好后确定应用。
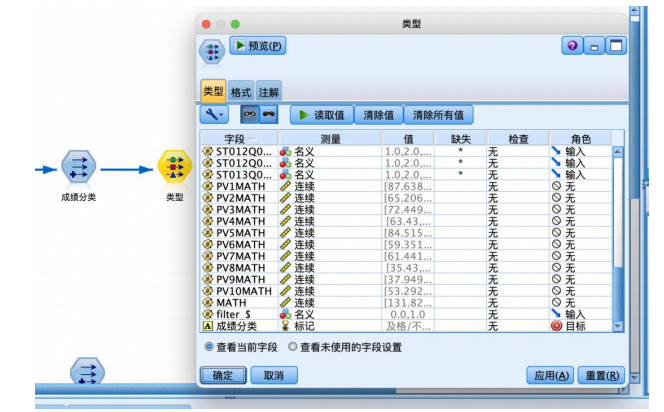
从“字段选项”选项卡中拖拽“类型”节点到数据流编辑区,与“导出”节点连接,并编辑“类型”节点,将“成绩分类”字段的角色设置为“目标”,其余字段设置为“输入”,并将与数学成绩有关的字段角色设置为“无”,如图所示。
从“字段选项”选项卡中拖拽“分区”节点到数据流编辑区,与“类型”节点连接,并右键编辑参数,设置 70%的数据用作训练,30%的数据用作预测。

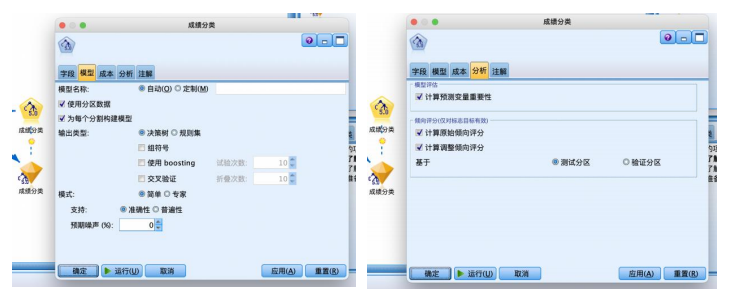
从“建模”选项卡中拖拽“c5.0”节点到数据流编辑区连接并右键编辑。“模型”选项卡使用默认的“简单”模式,“分析”选项卡设置计算输入变量重要性的指标,将模型评估与倾向评估都勾选如图。
运行得到结果。
c&rt 算法
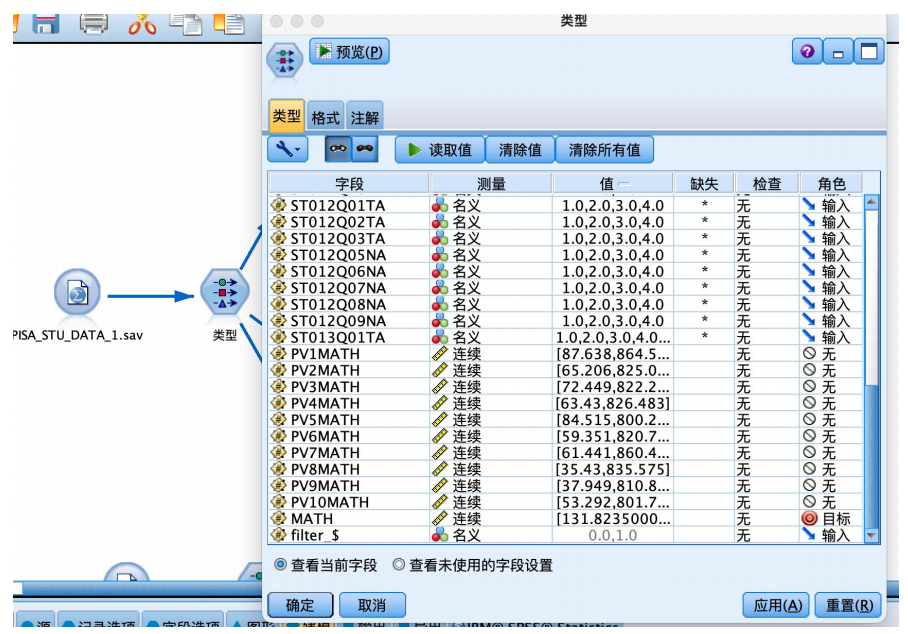
从“源”中拖拽出“statistics 文件”到数据流编辑区,并编辑数据,从“字段选项”选项卡中拖拽“类型”节点到数据流编辑区,建立连接,建立好如图数据流,并编辑“类型”节点,执行“读取值”操作,对部分值进行处理。将“math”字段的角色设置为“目标”,其余字段设置为“输入”,并将十次数学成绩设置为“无”。
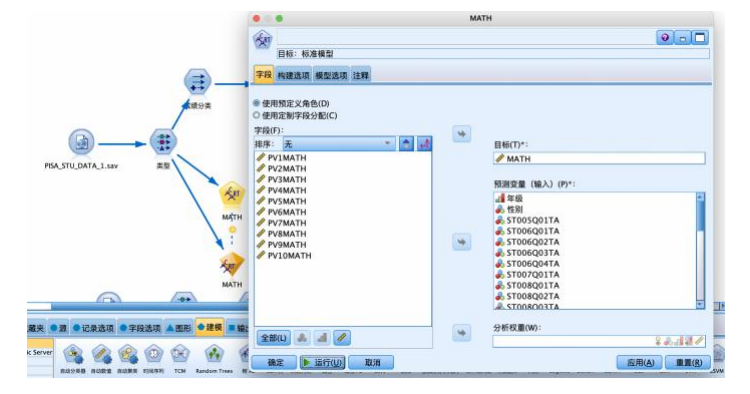
选择“建模”选项卡,拖拽“c&rt”节点到数据流编辑区。将“statistics 文件”节点与“c&rt”节点建立连接,右键并对其进行编辑。在“字段”选项卡中,选择“使用预定义角色(d)”,设置“构建选项”-“目标”“基本”“中止规则”“整体”,勾选“基本”中的“设置最大风险差(标准误差),都使用默认的如图参数。在“模型选项”选项卡中,选择“自动”,运行得到结果。

chaid 算法
从“源”中拖拽出“statistics 文件”到数据流编辑区,并编辑数据,从“字段选项”选项卡中拖拽“类型”节点到数据流编辑区,建立连接,建立好如图数据流,并编辑“类型”节点,执行“读取值”操作,对部分值进行处理。将“math”字段的角色设置为“目标”,其余字段设置为“输入”,并将十次数学成绩设置为“无”。
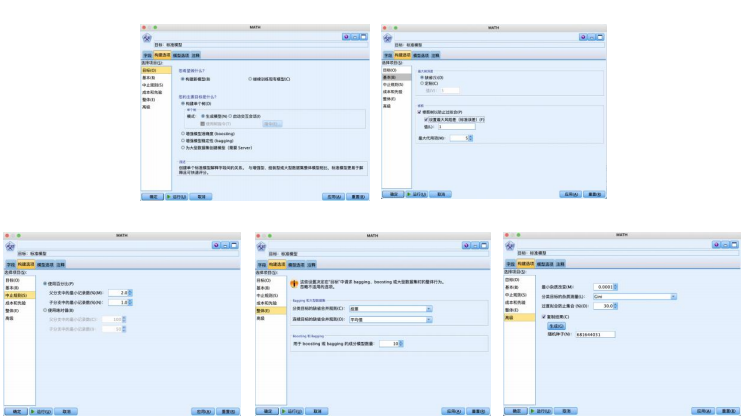
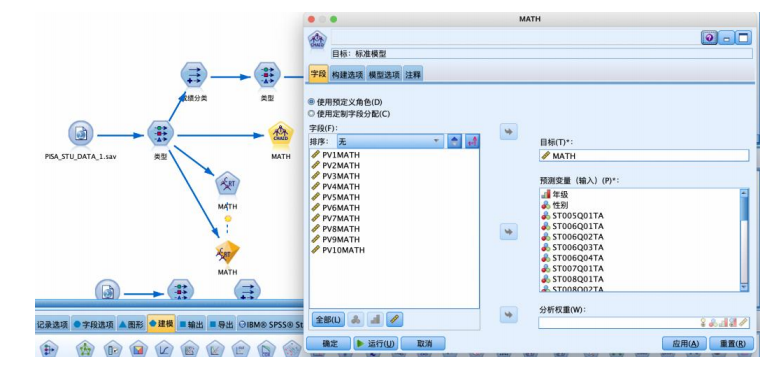
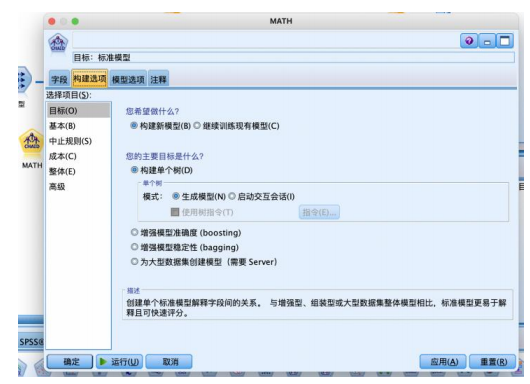
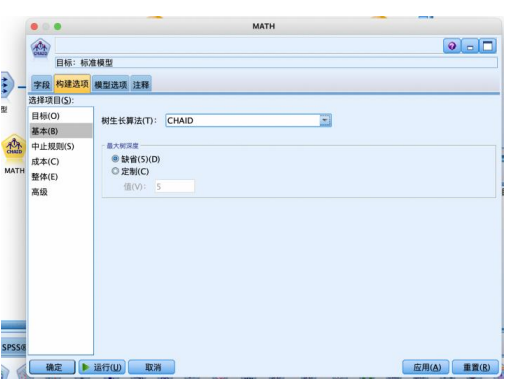
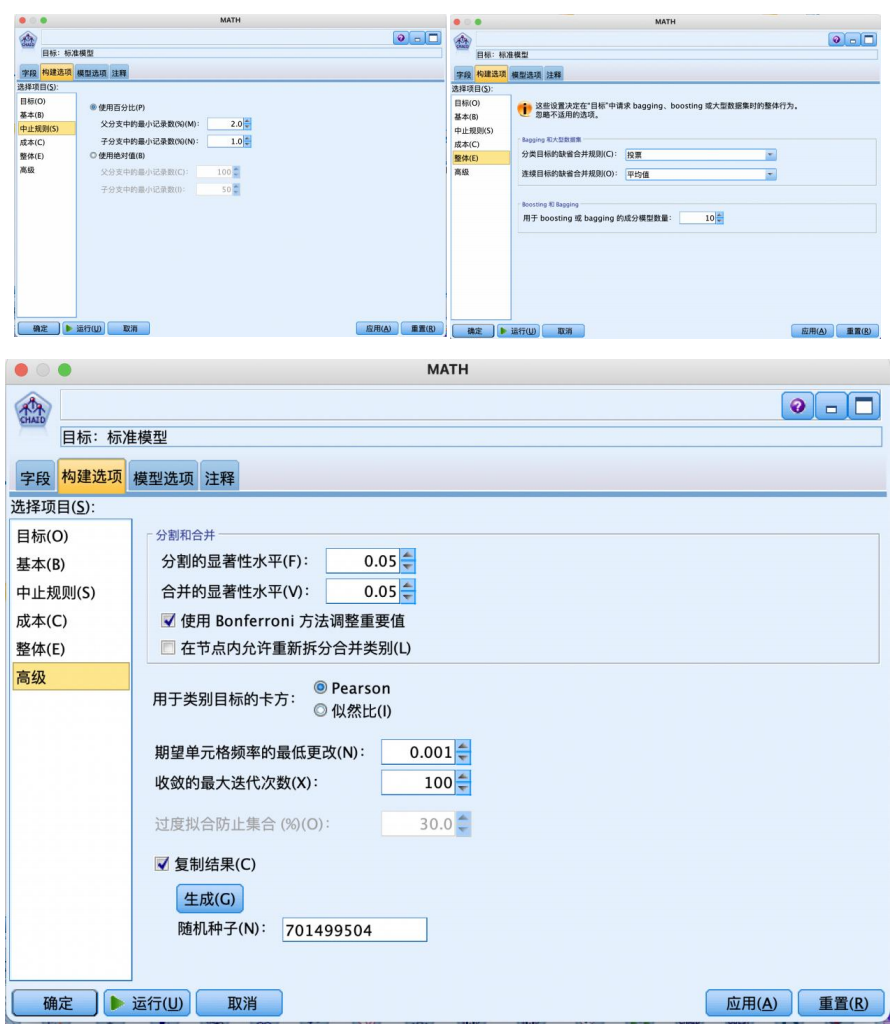
选择“建模”选项卡,拖拽“c&rt”节点到数据流编辑区。将“statistics 文件”节点与“c&rt”节点建立连接,右键并对其进行编辑。在“字段”选项卡中,选择“使用预定义角色(d)”,设置“构建选项”-“目标”,使用默认的如图参数,设置“构建选项”-“基本”-“树生长算法”,有 chaid 和穷举chaid 两种算法,本例选择 chaid 算法,“最大树深度”是不包括根节点在内的最大树层数,避免过拟合,默认为 5。设置“构建选项”-“中止规则”“整体”“高级”,都使用默认的如图参数,运行得到结果。
-
五、实验结果
c5.0 决策树算法
运行结果如图所示,左侧是推理规则,右侧是输入变量倾向性得分的图形表示。
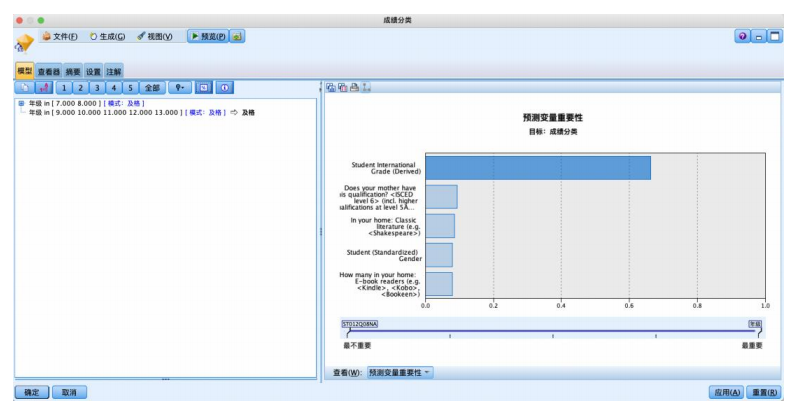
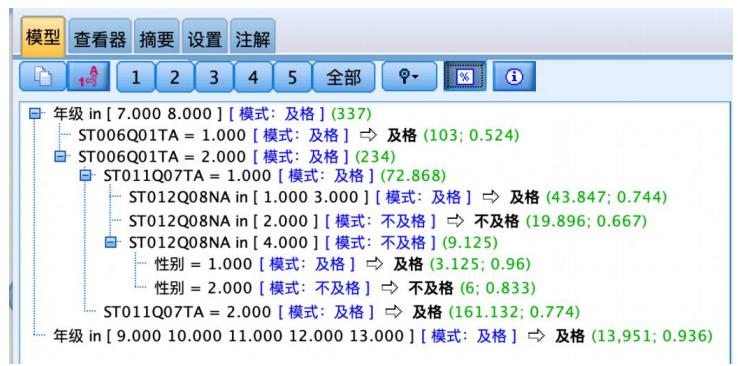
左侧的文字结果是从决策树上直接获得的推理规则,单击工具栏上的%按钮,可得到每个节点的样本量及置信度。
生成如图所示的规则集,更直观表示结果。
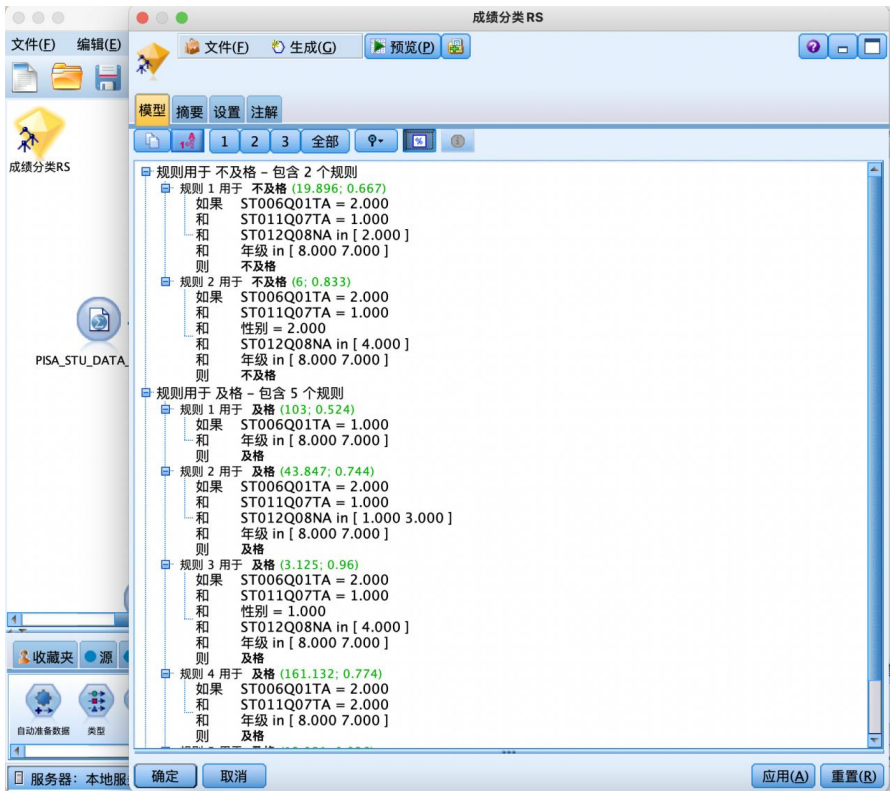
结果:
规则1用于预测不及格,样本有19个,正确预测率(规则置信度)为66.7%,即如果母亲没有获得一些isced证书(包括在一些国家获得5a级的高级资格证书)和在家中有古典文学作品和在家中有一本电子阅读器和在七八年纪的学习者样本数学成绩倾向于不及格。
规则2覆盖6个样本,准确率为83.3%,可不断类推下去,不再
赘述。
c&rt 算法
运行结果:
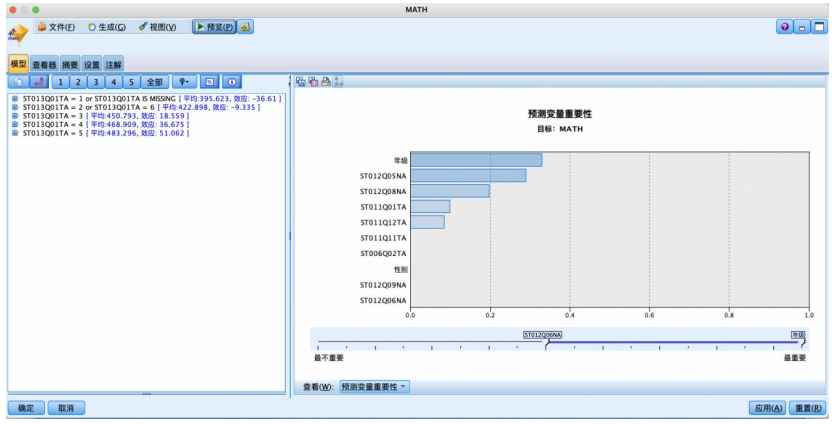
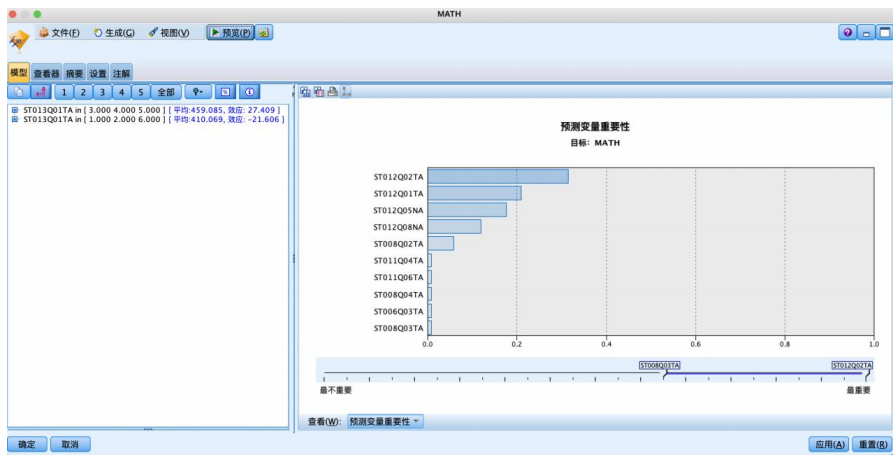
基于 chaid 算法的数据分析
运行结果:
-
六、分析与讨论
(1)c5.0决策树算法通过生成推理规则和可视化重要变量的得分图,提供对影响学生数学成绩的关键变量的洞察。从推理规则中可以看出,母亲是否获得一些6级isced证书、家中是否有古典文学作品、学生性别等变量对数学成绩有显著影响。这些规则可以帮助学校和政策制定者更好地了解哪些因素可能导致学生数学成绩不及格,从而采取有针对性的改进措施。此外,通过置信度和样本量的信息,可以评估每个规则的可靠性。
(2)c&rt算法也提供了对影响数学成绩的重要变量的洞察。家庭的汽车数量、电视数量、智能手机数量、电子阅读器数量等都被识别为重要变量。这些结果有助于理解家庭环境对学生学业表现的影响。该算法还通过可视化呈现了不同变量的重要性,使决策者更容易理解。
(3)基于chaid算法的分析也强调了一些重要的影响因素,如年级、家庭的智能手机数量、家庭的电子阅读器数量等。此外,该算法还提到了其他变量,如家中是否有学习桌子、宇典、技术参考书等。这表明学生数学成绩受多个因素的综合影响,不仅仅是学生个体特征,还包括家庭和学习环境因素。
这些不同的决策树算法在分析pisa数据时提供了多种方式来理解学生数学成绩的影响因素。学生数学成绩受多个因素的影响,包括个体特征(如年级、性别)、家庭背景(如母亲的教育水平、家庭资源)、学习环境(如电子设备、学习桌子)等。因此,在改善学生数学成绩时,需要综合考虑这些因素。
不同的决策树算法可以提供不同的视角和解释,有助于深入理解数据。选择适合问题的算法和分析方法非常重要,以确保得到有用的结论。
可视化是理解和传达分析结果的重要工具。通过图形表示,可以更直观地呈现变量的重要性和规则的逻辑。
最终的分析结果可以为学校、政府和教育决策者提供有针对性的建议,帮助他们制定更有效的教育政策和干预措施,以提高学生的数学成绩和学习经验。
-
七、总结或个人反思
在进行数据分析前,需要深入理解数据的背景和特点,包括了解pisa数据的来源、数据的质量、缺失值处理等。在未来的工作中,我应该更加关注数据质量的问题,确保数据的准确性和完整性。
在算法选择上选择合适的算法对于解决问题至关重要。在本次分析中,我使用了不同的决策树算法,因为不同算法可以提供不同的洞察角度。在今后我应该进一步研究和了解不同算法的优缺点,以便更好地选择适合特定问题的算法。
可视化是将分析结果传达给他人的重要手段。我使用了图形表示来呈现变量的重要性和规则的逻辑,而在日后,我可以探索更多的可视化技巧,以提高结果的可理解性。
数据科学领域不断发展,新的算法和技术不断涌现。我需要保持持续学习的态度,不断更新自己的知识和技能,以跟上领域的最新发展。数据分析是一门实践性很强的领域,通过实际的项目和案例分析,我可以积累更多的经验,提高自己的分析能力。我应该积极寻找机会参与实际项目,并不断挑战自己。
通过总结和反思本次数据分析经验,我可以更好地指导自己在未来的工作中取得更好的成果。持续学习、实践经验、团队合作和伦理意识都将成为我在数据科学领域取得成功的关键因素。
-
-
- 标签:
- PISA数据的决策树分析
- PISA
- 决策树
-
加入的知识群:
.jpg)

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~