-
知识追踪研究进展综述
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
摘要
作为教育领域重点研究方向之一的知识追踪(KT),可以依据学生历史学习轨迹,精准建模,为学生提供自适应学习服务。一个可以自动追踪学习者知识掌握情况的知识追踪模型对教育者和学习者都是必要的,因为它既可以向教育者反馈学习者知识掌握情况, 让教育者更加了解每一个学习者, 也可以推断学习者的知识弱点, 向学习者推荐高效的学习路径和恰当的学习资源, 从而做到因材施教。为了更加深入认识知识追踪,笔者从知识追踪的相关概念和任务展开叙述,梳理其发展脉络,综述知识追踪的原理、分析当前主流知识追踪模型大的优缺点。先后介绍了基于马尔可夫过程的知识追踪、基于深度学习的知识追踪和基于 Logistic模型的知识追踪,并在此基础上做出了一定展望。
关键词:知识追踪(KT);自适应学习;深度学习;Logistic模型
-
引言
智能导学系统和大规模在线开放课程(Massive Open Online Course, MOOC)等在线教育平台日益普及, 为大规模搜集学生学习数据提供了强有力的支撑。然而, 在线教育系统在提供便利的同时, 由于学习平台上的学生人数远远超过教师数量, 导致平台提供自主学习服务和个性化教学存在诸多困难。如何最大限度地利用这些数据,分析学生的知识状态,过去和未来的学习活动,从而实现学生的自适应学习以成为亟待解决地问题。研究人员试图利用知识追踪技术根据学生的历史学习情况来评估学生对知识点的掌握水平,从而预测学生将来的表现,进而更好地为提供个性化教学资源和推荐相关学习路径作好诊断。具体来说, 基于学生的学习记录, 准确地对学生的学习状态进行分析, 进而为学生提供个性化导学服务。
-
知识追踪概述
知识追踪(Knowledge Tracing)是根据学生过去的答题情况对学生的知识掌握情况进行建模,从而得到学生当前知识状态表示的一种技术,早期的知识追踪模型都是依赖于一阶马尔科夫模型,例如贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)。便我们能准确地预测学生对于各个知识概念的掌握程度,以及学生在未来学习行为的表现。准确可靠的知识追踪意味着我们可以根据学生的自身的知识状态,给他们推荐合适的练习题目,比如,推荐给学生薄弱知识概念关联的题目,而过于困难或者过于简单的题目不应该被推荐,从而可以给学生进行高效的个性化教学。
知识追踪通常依赖于整个过程中学习者的状态建模,建模目的是从学生的练习中学习学生状态的潜在表示,这些状态表示有许多应用场景,如分数预测、习题推荐等。通常,我们也把获得的状态表示看作是学生的知识熟练度,传统的学生建模采用BKT进行建模,它是含有隐变量的马尔可夫模型通过将学生的知识状态假设为一组二进制变量来对学生知识点的变化进行追踪。为了解决知识追踪任务首先进行用户交互建模,现有的建模方法依据反馈的时间分为下面两种。第一种建模方式为实时反馈的用户交互建模,在现实中的棠些情况下学生完成一道习题后需要重刻更新模型中学生对于知识点的掌握情况倩息。比如在P常练习中,学生完成一道习题后可以立即得到反馈,学生的知识点掌握情况也随之发生变化。第二种建模方式为基于阶段性反馈的用户交互建模,与上一种情况完全相反,某些情况下学生宗成一道习题不能够立即获得反馈,因此不能立刻更新模型中学生对于知识点的掌握情况。比如在考试时,学生完成一道题目后不可能立刻获取答案,因此考试过程中学生对于知识点的掌握程度变化不大。
由于知识追踪对于学习过程的重要意义,业界已经出现了很多相关的模型,如贝叶斯知识追踪(BKT),循环神经网络(RNN)等。其中,RNN被应用于一种称为深度知识追踪(DKT)的方法中,实验结果表明,DKT方法在不需要人工选取大量特征的情况下,优于传统方法。总体来说,由于人脑和知识的复杂性,知识追踪问题还有很多内容有待解决.
-
研究进展
现有的知识追踪模型大致可以分为3类: 基于基于马尔可夫过程的知识追踪、基于深度学习的知识追踪以及基于Logistic模型的知识追踪。下面将分别详细介绍这3类模型。
(一)基于马尔可夫过程的知识追踪
马尔可夫过程是一类随机过程,即当前的时刻状态已知,未来时刻状态仅与当前时刻状态有关而与历史状态无关的随机过程。马尔可夫过程“无历史记忆”的特性,可以有效简化知识追踪建模 的复杂度,即假设学习者下一时刻的知识状态仅与当前时刻的知识状态有关。在ITS中的一个重要问题是,什么时候能够判断某个学生掌握了某个知识点。一个比较简单的处理方式是要求学生连续对N个同一知识点相关的题目回答正确,虽然这种方式现在仍然被某些系统利用,而 BTK能够用一种更加直观而容易理解的方式解决这个问题。
1.1贝叶斯知识追踪
BKT是隐马尔可夫模型的一个特例,它将学生的历史响应作为观测序列,将学生对知识点的掌握作为状态序列,并且考虑猜测、失误及遗忘因素。BKT为每个知识点独立建模,假设学生的响应为二元观测变量:正确与错误。知识状态为二元变量:掌握与未掌握,并且可从未掌握状态通过学习获得知识点过渡到掌握状态,学习过程中不存在遗忘。如图1 所示,模型为每个知识点赋予5个参数,分别为两个学习参数、两个表现参数、一个遗忘参数。
(1)两个学习参数。
1)P(L0),先验概率:学生未进行练习时,掌握知识点的概率。2)P(T),转移概率:学生进行练习,对知识点从未掌握到掌握的概率。
(2)两个表现参数。
1)P(G),猜测概率:学生未掌握知识点但通过猜测能正确回答习题的概率。2)P(S),失误概率:学生掌握知识点但失误导致错误回答习题的概率。
(3)一个遗忘参数。
P(F),遗忘概率:学生对知识点从掌握到未掌握的概率。
图1、贝叶斯知识追踪模型
根据学生在正确回答习题的情况下,考虑猜测,掌握知识点的概率的表达式如下:
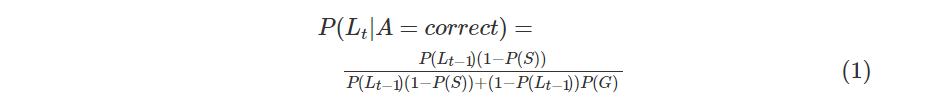
在错误回答习题的情况下,考虑失误,掌握知识点的概率的表达式如下:
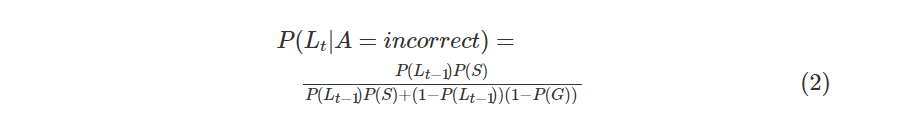
更新学生在t时刻掌握知识点的概率:
P(Lt)=P(Lt|A)+(1-P(Lt|A))P(T) (3)
预测下一时刻学生能够正确回答习题的概率:
P(Ct+1)=P(Lt)(1-P(S))+(1-P(Lt))P(G) (4)
BKT模型给出了“三个假设”:(1)学习者在在学习过程中只有两种知识状态,分别是掌握和未掌握; (2)学习者在知识学习过程中不会对知识点产生遗忘,即不可逆;(3)每个知识点都与其他知识点保持相互独立。显然,这三个假设相对于在真实学习情景中学习者的知识状态而言太过于理想化。针对假设 1,认为学习者的知识状态表达只有掌握和未掌握两个状态,会导致对学习过程的分析粒度过粗,而形成建模误差;针对假设 2,学 习者在学习过程必然会存在遗忘行为,若假设学习者一旦学会就不会遗忘,则不符合现实情况;针对假设 3,在学习过程中知识之间具有一定的关联,如学习者在了解加法的交换律这一概念后会对其理解乘法的交换规律产生促进作用。
基于马尔可夫过程的知识追踪是用图来表示变量概率依赖关系,使用学习者答对答错这个观察量和学习者潜在知识状态这个隐变量,表示概率图的两个节点,再设计出隐变量与变量、 变量与变量之间的联系,最后假设这些变量服从特定的分布。其优势在于:(1)对数据集大小的要求不高;(2)模型简捷,可以很好地利用教育学原理,可解释性强。而其不足之处在于:(1)由于其固有的结构以及函数形式的限制,不能对学习者长期学习的时序依赖建模;(2)依赖教育专家对教学场景的理解,容易导致建模的局限性。目前,基于马尔可夫过程的知识追踪因其解释性强、 模型简捷, 已被广泛应用于各类智能导学系统和在线学习平台。
(二)基于深度学习的知识追踪
深度学习(Deep Learning)是机器学习下的一个特殊分支,是借鉴了人脑由很多神经元组成的特性而形成的一个框架。深度学习最早应用于人工智能领域,随着人工智能技术与教育的深度融合,深度学习在教育领域中的应用也愈加广泛。斯坦福大学团队于2015年首次将深度学习引入知识追踪领域,提出深度知识追踪(Deep Knowledge Tracing,DKT)模型。DKT模型主要采用循环神经网络(Recurrent Neural Network,RNN),对学习者的知识状态进行高维连续表征,并利用其作答序列的时序关系信息进行题目作答对错的预测。其在学习者表现预测以及学习者知识状态挖掘方面,体现出了更高的精准性,也能更好地帮助学习者清晰自我认知结构并更具针对性地开展学习;相应地,教育者也能更好地进行教学干预和个性化教学。深度知识追踪最大的一个潜在应用是帮助学生优化知识点的学习效率,根据学生实时的知识点掌握水平来帮助学生选择最好的学习的顺序,这样可以帮助学生有针对性补他目前知识上最大的短板。相比贝叶斯知识追踪(BKT)深度知识追踪(DKT)有不少优势:(1)模型可以反映出长时间的知识掌握程度,相比传统贝BKT假设知识一旦掌握了就不再会被遗忘,深度知识追踪引入循环神经网络模型可以很好地模拟知识长时间不做会被遗忘的行为,更加符合人们的认知。(2)能够对复杂的知识点间的联系进行建模,从而发现不同知识点间的内在联系。当然深度知识追踪模型也是存在着缺点的:(1)模型存在无法重构的可能性,比如学生在此刻做对Undefined知识点,但是某些情况下,模型认为下一刻对Undefined知识点的掌握水平反而下降。(2)在时间序列上,学生存在对知识点掌握程度不连续的情况,部分学生的波动可能过大[4]。
2.1 DKT模型
标准DKT的结构如图2所示。DKT模型输入为学生答题记录{x1,x2,…,xt},通过one-hot编码或压缩感知表示法xt被转化为向量输入模型。为了将输入映射到输出,输入向量会通过隐藏层进行特征提取,隐藏层{h0,h1,…,ht}的状态向量ht可理解为学生在第t时刻的知识状态。将学生的知识状态通过输出层计算可得到输出向量,{y1,y2,…,yt}表示在时间步1~t,学生正确回答每一道习题的概率。所涉及公式如下所示:
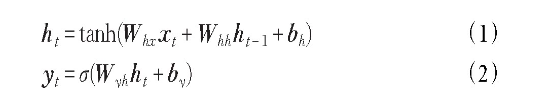
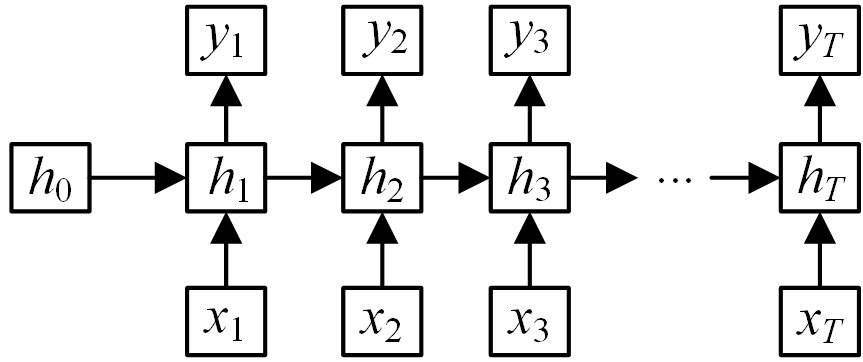
图2 DKT模型结构图
2.2 DKT的局限
DKT是目前最流行的知识追踪模型,但是也存在以下局限性:
(1)DKT假设学生在学习过程中不存在遗忘;
(2)DKT仅使用习题涉及的知识点及正确性作为模型的输入,忽视了教育平台收集到的其他特征;
(3)DKT只评估学生的整体知识水平,忽略了对每个知识点的掌握情况;
(4)DKT模型存在波动与无法重构的问题;
(5)DKT不具备可解释性。
(三)基于 Logistic模型的知识追踪
Logistic 模型是一类基于 Logistic 函数的大型模型,其基本概念是正确回答练习的概率可以由学生和KC参数的数学函数表示。在 Logistic 模型中,学生的二元答案(正确/不正确)遵循伯努利分布。21世纪初,研究者们提出了采用 Logistic 模型处理知识追踪任务,以学生成绩为因变量,从历史数据中学习一 般参数对学生建模来进行答题预测。主要分为两大类:项目反应理论(IRT)、因子分析模型。
3.1 项目反应理论
项目反应理论(Item Response Theory,IRT)的产生是因为传统教育测量具有很大的局限性。其中所谓“项目”(item)其实就是指的我们试卷中的题目,“项目反应”(item response)就是考生在具体题目上的作答。简而言之,IRT就是建立在学生能力和作答正确率的关系上的。影响学生在项目上作答结果的主要因素有两个:其一是学生本身的能力水平;其二是试题项目的 测量学属性,如项目难度、区分度和猜测性等。IRT模型的两个基础模型是正态肩型模型(the normal ogive model)和逻辑回归模型(logistic model),IRT初始模型的基本形式是由正态肩型模型构成的,但是其模型中采用了积分函数的形式,在实际参数估计和使用中不方便,因此后来logistic形式成为了主要应用的模型。根据学生的能力水平θ和项目的难度等级βj ,输出一个学生在测试中正确回答一个项目 j(即 一个问题)的概率 p(a) 。最简单的模型如下。
定义该概率的项目反应函数具有以下特征:如果一个学生的能力水平较高,那么这个学生正确回 答题目的概率就更高;另一方面,如果题目比较难,那么学生正确回答的概率就相对较低。此外除了预测学生的反应,IRT 还可以用来评估项目的难度水平和学生的能力。
-
知识追踪应用
(一)智能学习推荐
智能学习推荐是给学习者推荐适合自己的教学资源,例如最佳学习项目序列、习题资源等。 知识追踪能够通过学习者过去的学习交互序列追踪学习者的知识状态,从而预测下一次交互作答的准确概率。因此,教师可以借此观察学习者的预期学习状态,并推荐下一个能使学习者知识状态更好的学习问题,再利用启发式 Exceptimax 算法,给出学习者的最佳学习项目序列。
(二)自动学习干预
知识追踪能够在学习过程中不断更新学习者的知识状态,使教师能够及时了解学习者的知识结构,进而采取补救措施,如针对学习薄弱点进行教学、为学习者推荐难度适中的练习等,从而提高教学效能, 达到因材施教的目的,为学习者提供个性化的发展机会。
(三)学习可视化
研究者通过文本数据的交互结构图形来形象 地展示信息或者知识,可以帮助人们更加直观地理解相关教育数据。 在知识追踪领域,有研究者通过可视化知识追踪诊断结果,从而直观地分析学习者的知识掌握情况、知识点之间的关系网络。
-
总结
随着教育信息化程度的不断加深,以预测学生知识状态为目标的知识追踪正成为个性化教育中一项重要且富有挑战性的任务。知识追踪作为一项教育数据挖掘的时间序列任务,能通过对前一阶段的表现来预测学习者对知识的掌握情况, 并可以利用知识之间的关系, 自动描绘学习者不断变化的知识状态, 分析学习者整体学习趋势,更好地模拟学习者的学习过程, 提高学习者的学习效率;通过分析学习者的学习轨迹所包含的有意义信息, 潜在地做出提供暗示、反馈或建议新的练习等干预措施, 让教育者更加了解学习者的进步和问题领域, 满足学习者对个性化学习路径和学习资源的需求,提高智能辅导系统的有效性, 为研究者实现自动分析学习者知识掌握程度、自动评价学习者和自动反馈给学习者自适应的学习资源和学习路径提供动态的数据支撑。
知识追踪模型作为一种对学习者知识掌握情况建模的主流方法, 在教育方面已经有了不少成功案例, 研究的深度和广度都得到了很大的拓展。然而, 在知识点、学习者和数据三个层面都还存在一些不足。例如对于知识掌握的预测会设定度和阈值, 但是很少涉及学习者知识掌握判定的度或阈值的设定, 不知道什么类型的知识设定什么样的阈值范围, 以及设置阈值的依据是什么;而且现有的知识追踪模型相关文献多是对单个学习者对于知识点掌握预测, 缺少小组学习、合作学习/协作学习的学习者知识掌握的研究。但毋庸置疑的是, 知识追踪模型比判断学习者知识掌握的传统方法提供了更丰富的动态信息和预测, 使教育者可以面对更多学习者,更加了解学习者知识的掌握, 让学习者更加清楚自己学习的问题。随着人工智能技术的发展, 知识追踪模型在教育领域的研究会得到越来越广泛的运用。
-
参考文献
[1]张军.智慧教育视域下的全人化人才培养[J].中国高教研究,2022(07):3-7.DOI:10.16298/j.cnki.1004-3667.2022.07.02.
[2]曾凡智,许露倩,周燕,周月霞,廖俊玮.面向智慧教育的知识追踪模型研究综述[J].计算机科学与探索,2022,16(08):1742-1763
[3]王志锋,熊莎莎,左明章,闵秋莎,叶俊民.智慧教育视域下的知识追踪:现状、框架及趋势[J].远程教育杂志,2021,39(05):45-54.DOI:10.15881/j.cnki.cn33-1304/g4.2021.05.005.
[4] Chun-Kit Yeung and Dit-Yan Yeung. Addressing two problems in deep knowledge tracing via predictionconsistent regularization. In Proceedings of the 5th ACM Conference on Learning @ Scale, pages 5:1–5:10. ACM, 2018.
[5]陈之彧,单志龙.知识追踪研究进展[J].计算机科学,2022,49(10):83-95.
[6]李菲茗,叶艳伟,李晓菲,史丹丹.知识追踪模型在教育领域的应用:2008—2017年相关研究的综述[J].中国远程教育,2019(07):86-91.DOI:10.13541/j.cnki.chinade.20181214.001.
[7]李蓬.深度知识追踪在适应性学习系统的应用[J].现代计算机,2021(16):27-31.
[8]王卓,张铭.基于贝叶斯知识跟踪模型的慕课学生评价[J].中国科技论文,2015,10(02):241-246.
-
-
- 标签:
- 知识追踪
-
加入的知识群:

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~